사전 프로덕션 또는 프로덕션 환경의 요구 사항을 충족하기 위해 다양한 배포서버 유형, cloud 제공자, 클러스터 계층으로 클러스터 구성할 수 있습니다. 이러한 권장 사항을 사용하여 벡터 검색 수행하기 위한 배포서버 유형, cloud 제공자 및 리전, 클러스터 및 검색 계층을 선택합니다.
환경 | 배포 유형 | 클러스터 계층 | 클라우드 제공자 리전 | 노드 아키텍처 |
|---|---|---|---|---|
쿼리 테스트 | Flex cluster, dedicated cluster Local deployment | M0 or higher tierN/A | All N/A | MongoDB 및 Atlas Search 프로세스는 동일한 노드에서 실행됩니다. |
프로토타입 애플리케이션 | 전용 클러스터 | Flex 클러스터, | 모두 | MongoDB 및 Atlas Search 프로세스는 동일한 노드에서 실행됩니다. |
프로덕션 | 별도의 검색 노드가 있는 전용 클러스터 |
| MongoDB 와 Atlas Search 프로세스는 서로 다른 노드에서 실행됩니다. |
이러한 배포 모델에 대해 자세히 알아보려면 다음 섹션을 검토하세요.
리소스 사용량
벡터 인덱싱을 위한 메모리 요구 사항
MongoDB Vector Search는 메모리에 전체 인덱스 보유하므로 데이터 세트에 전체 정밀도 벡터가 포함된 경우 MongoDB Vector Search 인덱스 및 JVM 에 충분한 메모리가 있는지 확인해야 합니다. 각 인덱스 인덱싱되는 벡터와 추가 메타데이터 의 조합입니다. 인덱스 크기는 주로 인덱싱 하는 벡터의 크기에 따라 결정되며, 메타데이터 공간은 일반적으로 상대적으로 명목입니다.
양자화를 사용하지 않는 경우, MongoDB Vector Search는 전체 충실도 벡터를 메모리에 저장합니다. 자동 양자화를 활성화 MongoDB Vector Search는 훨씬 적은 리소스를 필요로 하는 양자화된 벡터를 메모리에 저장하고 전체 충실도 벡터를 디스크에 저장합니다. Atlas UI MongoDB Search 페이지에서 Size 및 Required Memory 열을 확인하여 벡터 인덱스에 대한 디스크 및 메모리 요구 사항 간의 차이를 확인할 수 있습니다.
단일 벡터 에 대해 다음 요구 사항을 고려하세요.
임베딩 모델 | 벡터 차원 | 공간 요구 사항 |
|---|---|---|
Voyage AI | 2048 | 8kb (for float)2.14kb (for int8)0.334kb (for int1) |
OpenAI | 1536 | 6kb |
Google | 768 | 3kb |
Cohere | 1024 | 4kb (for float)1.07kb (for int8)0.167kb (for int1) |
BinData 양자화된 벡터. 자세한 내용은 양자화된 벡터 수집을 참조하세요.
필요한 공간은 인덱싱하는 벡터의 수와 벡터 차원에 따라 선형적으로 확장됩니다. Search Index Size 메트릭을 사용하여 검색 노드에 필요한 공간과 메모리 양을 확인할 수도 있습니다.
벡터의 스토리지 요구 사항
BinData 또는 양자화된 벡터를 사용하면 binData 또는 양자화된 벡터를 사용하지 않을 때에 비해 리소스 요구 사항이 크게 줄어듭니다. 다음 사항을 확인할 수 있습니다.
binData벡터 사용 시mongod에서 벡터의 디스크 스토리지가 66% 감소합니다.자동 벡터 양자화 또는 양자화된 벡터 수집 사용 시 벡터 압축으로 인해
mongot에서 벡터 RAM 사용량이 3.75배(스칼라) 또는 24배(바이너리) 감소합니다.
자동 양자화를 사용할 때, Atlas는 리스코어링 또는 정확한 검색을 위해 고정밀 벡터를 디스크에 저장하고, 리스코어링을 위한 RAM 및 캐시 사용을 최소화합니다.
MongoDB Vector Search 인덱스 정의 에서 자동 양자화 를 활성화 경우 클러스터의 크기를 조정할 때 디스크 공간도 고려해야 합니다. 이는 자동 양자화를 구성한 경우 MongoDB Vector Search가 ENN 검색 및 재채점을 위해 완전 정밀도 벡터도 디스크에 저장하기 때문입니다. 따라서 사용하는 hardware 에 적절한 디스크 대 RAM 비율이 있는지 확인합니다. 스칼라 양자화의 경우 대략 4:1 의 저장 대 RAM 비율, 이진 양자화의 경우 24:1 의 저장 대 RAM 비율을 수용할 수 있는 검색 노드를 구성하는 것이 좋습니다.
예시
이 예시는 my-embeddings라는 필드에 저장된 Voyage 의 10,000만 개 1024 차원 임베딩에 대해 바이너리 양자화를 구성하는 방법을 설명합니다.
{ "fields":[ { "type": "vector", "path": "my-embeddings", "numDimensions": 1024, "similarity": "euclidean", "quantization": "binary" } ] }
다음 공식을 사용하여 리스코어링을 포함한 바이너리 양자화 활성화 인덱스의 디스크 공간을 대략적으로 계산합니다.
Original index size * (25/24)
여기서 분모의 24는 분수를 더 쉽게 표현하기 위해 24부분으로 분할된 원래 인덱스 크기를 나타냅니다. 분자의 25는 바이너리 벡터를 저장하는 데 필요한 추가 데이터에 대해 원래 인덱스 크기의 약 1/24에 해당하는 추가 공간 할당을 나타냅니다. 원래 인덱스와 Hierarchical Navigable Small Worlds 그래프는 여전히 디스크에 저장됩니다. HNSW 그래프가 압축되지 않기 때문에 크기 초과 계수는 1/32이 아닌 1/24입니다.
예시
원래 인덱스 크기가 1GB라고 가정해 보겠습니다. 아래와 같이 리스코어링을 사용하여 바이너리 양자화된 인덱스 크기를 계산할 수 있습니다.
1 GB * (25/24) = 1.042 GB
중요
Atlas UI 에서 Atlas 전체 인덱스 크기를 표시하지만, Atlas RAM 과 디스크에 저장된 인덱스 내의 데이터 구조를 세분화하여 표시하지 않기 때문에 클 수 있습니다. MongoDB Search 지표 자동 양자화를 활성화 때 메모리에 보관되는 훨씬 더 작은 인덱스 표시합니다.
자동 양자화를 구성한 벡터의 경우, 예상 인덱스 크기의 125%에 해당하는 여유 디스크 공간을 할당하는 것이 좋습니다.
테스트 및 프로토타입 제작 환경
벡터 검색 쿼리를 테스트하고 애플리케이션의 프로토타입을 만들려면 다음 구성을 권장합니다.
배포 유형
MongoDB Vector Search 쿼리를 테스트하기 위해 Flex 클러스터, 전용 클러스터 배포 하거나 로컬 Atlas 배포서버 사용할 수 있습니다.
Cluster Tiers
무료 클러스터에는 M0 계층이 포함됩니다. Flex 클러스터는 MongoDB를 학습하거나 소규모 개념 증명 애플리케이션을 개발하는 팀에 적합한 저비용 클러스터 유형입니다. Atlas Flex 클러스터로 프로젝트를 시작하고 나중에 프로덕션 지원 전용 클러스터 계층으로 업그레이드할 수 있습니다.
이러한 저비용 클러스터 유형은 MongoDB Vector Search 쿼리를 테스트하는 데 사용할 수 있습니다. 그러나 Flex 클러스터에서는 리소스 경합과 쿼리 지연 시간 발생할 수 있습니다. Flex 클러스터 로 프로젝트 시작하는 경우, 애플리케이션 프로덕션할 준비가 되면 상위 계층 으로 업그레이드하는 것이 좋습니다.
전용 클러스터에는 M10 이상의 계층이 포함됩니다. M10 및 M20 계층은 애플리케이션 프로토타입을 제작하는 데 적합합니다. 애플리케이션이 프로덕션에 적용될 준비가 되면 더 높은 계층으로 업그레이드하여 대규모 데이터세트를 처리하거나 전용 검색 노드를 배포하여 워크로드를 분리할 수 있습니다.
클라우드 제공자 및 리전
선택한 클라우드 공급자와 리전은 클러스터 계층에 사용할 수 있는 구성 옵션과 클러스터 실행 비용에 영향을 미칩니다.
모든 클러스터 계층은 지원되는 모든 cloud 제공자 리전에서 사용할 수 있습니다.
로컬에서 MongoDB Vector Search 쿼리를 테스트하려는 경우, Atlas CLI 사용하여 로컬 컴퓨터에서 호스팅되는 단일 노드 복제본 세트 배포 수 있습니다. 시작하려면 MongoDB Vector Search 빠른 시작 을 완료하고 로컬 배포 탭 선택합니다.
애플리케이션을 프로덕션할 준비가 되면 실시간 마이그레이션을 사용하여 로컬 Atlas 배포를 프로덕션 환경으로 마이그레이션하세요. 로컬 배포는 로컬 컴퓨터의 CPU, 메모리 및 스토리지 리소스에 의해 제한됩니다.
노드 아키텍처
테스트 및 프로토타입 환경의 경우, MongoDB 프로세스와 MongoDB Search 프로세스가 동일한 노드 에서 실행 노드 아키텍처를 권장합니다. 이 배포서버 모델의 다음 다이어그램에서 MongoDB Search mongot 프로세스 Atlas cluster 의 각 노드 에서 mongod 와 함께 실행되며 동일한 리소스를 주식 .

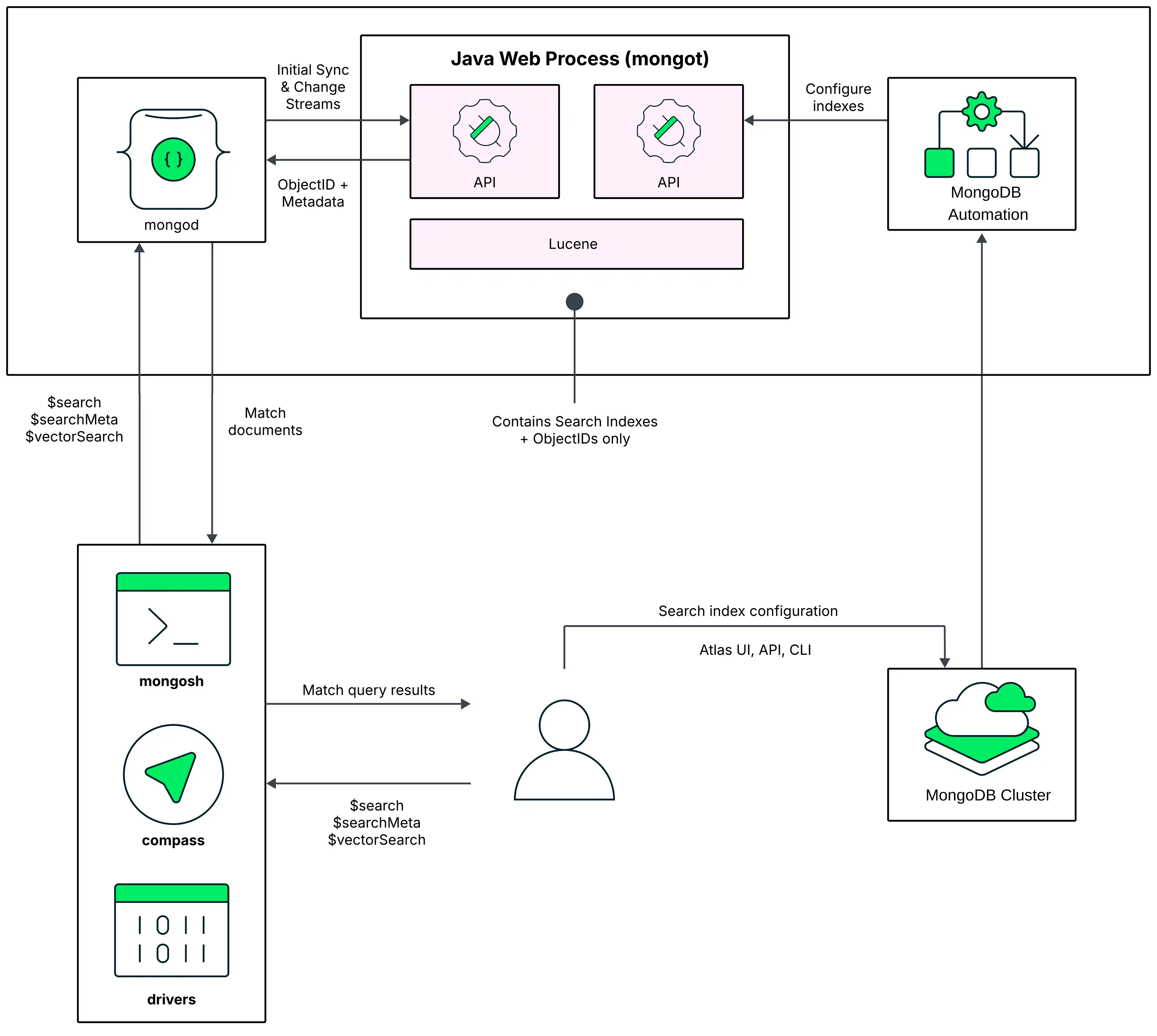
기본값 으로 Atlas 첫 번째 MongoDB Vector Search 인덱스 생성할 때 mongod 프로세스 실행하는 동일한 노드 에서 MongoDB Search mongot 프로세스 활성화합니다.
쿼리 실행 때 MongoDB Search는 구성된 읽기 설정 (read preference) 사용하여 쿼리 실행 노드 식별합니다. 쿼리 먼저 복제본 세트 클러스터 의 경우 mongod, 샤딩된 클러스터 의 경우 mongos 인 MongoDB 프로세스 로 이동합니다.
복제본 세트 클러스터 의 경우 mongod 프로세스 쿼리 를 동일한 노드 의 mongot 로 라우팅합니다. 샤딩된 클러스터의 경우, 클러스터 데이터는 mongod 인스턴스(샤드)로 분할되며 각 mongot 프로세스 동일한 노드 의 mongod 인스턴스 에 있는 데이터에만 액세스 할 수 있습니다. 따라서 특정 샤드 대상으로 하는 MongoDB Search 쿼리를 실행 수 없습니다. mongos 는 쿼리 모든 샤드로 라우팅하여 이러한 분산 수집 쿼리를 만듭니다. 구역을 사용하여 클러스터 의 샤드 하위 집합에 샤딩된 컬렉션 배포하는 경우, MongoDB Search는 쿼리 중인 컬렉션 의 샤드가 포함된 구역 으로 쿼리 $search 를 라우팅하고 쿼리를 샤드에 대해서만 실행합니다. 컬렉션 이 위치합니다.
쿼리 MongoDB Search mongot 프로세스 로 라우팅된 후 mongot 프로세스 검색 및 점수 산정을 수행하고 일치하는 결과에 대한 문서 ID 및 기타 검색 메타데이터 해당 mongod 프로세스 에 반환합니다. 그런 다음 mongod 프로세스 일치하는 결과에 대해 암시적으로 전체 문서 조회를 수행하고 결과를 클라이언트 에 반환합니다. 쿼리 에 $search 동시 옵션을 사용하는 경우 MongoDB Search는 쿼리 내 병렬 처리를 활성화합니다. 자세히 학습 세그먼트 간 쿼리 실행 병렬 처리를 참조하세요.
mongot 프로세스에 대해 자세히 알아보려면 쿼리 처리를 참조하세요.
애플리케이션 프로토타입을 위한 클러스터 크기 조정
Atlas 동일한 노드 에서 데이터베이스 와 검색 워크로드를 실행하는 경우, MongoDB 저장 노드의 사용 가능한 메모리(RAM) 중 일정 비율을 차지하며, 나머지는 MongoDB Vector Search 인덱스 와 mongot 프로세스 위해 남겨둡니다.
계층 | 총 메모리 (GB) | MongoDB 벡터 검색에 사용할 수 있는 메모리 인덱스(GB) |
|---|---|---|
| 2 | 1 |
| 4 | 2 |
| 8 | 4 |
M10, M20 및 M30 클러스터 계층의 경우 25%는 MongoDB 위해 예약되고 나머지 75%는 MongoDB Vector Search 인덱스 포함한 다른 작업을 위해 예약됩니다. M40개 이상의 클러스터 계층의 경우, 50%는 MongoDB 위해 예약되고 나머지는 MongoDB Vector Search 인덱스 포함한 다른 작업을 위해 예약됩니다.
제한 사항
데이터베이스 mongod와 검색 mongot 프로세스 간에 리소스 경합이 발생할 수 있습니다. 이는 인덱스 성능과 쿼리의 지연 시간에 부정적인 영향을 미칠 수 있습니다. 이 배포 모델은 테스트 및 프로토타이핑 환경에만 사용하는 것을 권장합니다. 프로덕션에 즉시 사용할 수 있는 애플리케이션과 관련 검색 워크로드의 경우 전용 검색 노드로 마이그레이션하는 것이 좋습니다.
프로덕션 환경
프로덕션용 애플리케이션의 경우 다음과 같은 클러스터 구성을 권장합니다.
배포 유형
프로덕션 준비가 완료된 애플리케이션을 위해서는 워크로드 격리를 위한 검색 노드가 별도로 있는 전용 클러스터가 필요합니다.
Cluster Tiers
전용 클러스터에는 M10 및 그 이상의 계층이 포함됩니다. M10 및 M20 계층은 개발 및 프로덕션 환경에 적합합니다. 그러나 더 높은 계층은 대용량 데이터 세트와 프로덕션 작업을 처리할 수 있습니다. 검색 워크로드를 위해 전용 검색 노드를 배포하는 것도 좋습니다. 이를 통해 검색 배포를 독립적이고 적절하게 확장할 수 있습니다.
클라우드 제공자 및 리전
검색 노드는 Google Cloud Platform 의 모든 리전에서 사용할 수 있지만 Amazon Web Services 및 Azure 리전의 하위 집합에서만 사용할 수 있습니다. 배포서버 에 검색 노드를 사용할 수 있는 cloud 제공자 및 리전 선택해야 합니다.
모든 클러스터 계층은 지원되는 클라우드 공급자 리전에서 사용할 수 있습니다. 선택한 클라우드 공급자와 지역은 클러스터에 사용할 수 있는 구성 옵션과 검색 계층, 그리고 클러스터 실행 비용에 영향을 미칩니다.
노드 아키텍처
프로덕션 환경의 경우, MongoDB 프로세스와 MongoDB Search 프로세스가 별도의 노드에서 실행 노드 아키텍처를 권장합니다. 별도의 검색 노드를 배포 하려면 전용 검색 노드로 마이그레이션을 참조하세요.
이 배포서버 모델의 다음 다이어그램에서 MongoDB Search mongot 프로세스 mongod 프로세스 실행되는 클러스터 노드와는 별도의 전용 검색 노드에서 실행됩니다.

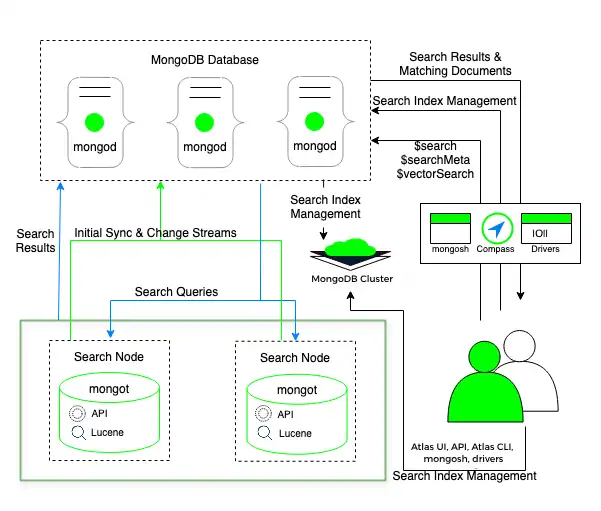
Atlas는 각 클러스터 또는 클러스터의 각 샤드에 대해 검색 노드를 배포합니다. 예를 들어 샤드가 3개인 클러스터에 검색 노드 2개를 배포하면, Atlas는 검색 노드를 6개(샤드당 2개) 배포합니다. 또한 검색 노드 수와 각 검색 노드에 프로비저닝된 리소스의 양을 구성할 수도 있습니다.
별도의 검색 노드를 배포 경우 Atlas 인덱싱 위해 각 mongot 에 대해 mongod 를 자동으로 할당합니다. mongot 는 mongod 와 동기화 저장하는 인덱스에 대한 인덱스 변경 사항을 수신하고 동기화합니다. MongoDB Vector Search는 mongod 및 mongot 프로세스가 모두 동일한 노드 에서 실행 배포서버 와 유사하게 쿼리를 인덱싱하고 처리합니다. 자세히 학습 벡터 검색을 위한 필드를 인덱싱하는 방법 및 벡터 검색 쿼리를 실행하는 방법을 참조하세요. 검색 노드를 별도로 배포하는 방법에 대해 자세히 학습하려면 워크로드 격리를 위한 검색 노드를 참조하세요.
검색 노드로 마이그레이션할 때, Atlas는 검색 노드를 배포하지만 검색 노드에서 클러스터의 모든 인덱스를 성공적으로 구축할 때까지 해당 노드에서 쿼리를 제공하지 않습니다. Atlas가 새로운 노드에서 인덱스를 구축하는 동안 클러스터 노드에 있는 인덱스를 사용하여 계속해서 쿼리를 제공합니다. Atlas는 검색 노드에서 인덱스를 성공적으로 구축하고 클러스터 노드에서 인덱스를 제거한 후에만 검색 노드에서 쿼리를 제공하기 시작합니다.
참고
검색 노드를 추가하거나 검색 계층을 변경하여 클러스터를 확장하면 전체 MongoDB 검색 인덱스의 재구축을 트리거합니다. 그러나 AWS 클러스터에 고객 키 관리를 사용한 미사용 데이터 암호화를 활성화하지 않은 전용 검색 노드가 있는 경우, Atlas는 다음과 같은 최적화를 제공합니다.
Atlas는 검색 노드를 확장할 때 새 노드에서 전체 MongoDB 검색 인덱스를 다시 빌드하지 않고 S3에 있는 인덱스의 최신 복사본을 사용합니다.
기존 노드의 경우, Atlas는 주기적으로 새로운 인덱스 파일의 증분 목록을 생성하고 업로드합니다. Atlas는 최대 14일 동안 인덱스 파일을 보관합니다.
Google Cloud 또는 Azure의 전용 검색 노드가 있는 클러스터에서는 아직 사용할 수 없습니다.
쿼리를 실행하면 쿼리가 구성된 읽기 설정에 따라 mongod로 라우팅됩니다. mongod 프로세스는 동일한 노드의 로드 밸런서를 통해 검색 쿼리를 라우팅하며, 로드 밸런서는 mongot 프로세스 전체에 요청을 분산합니다.
MongoDB Search mongot 프로세스 검색 및 점수 산정을 수행하고 일치하는 결과에 대한 문서 ID 및 메타데이터 mongod에 반환합니다. 그런 다음 mongod 는 일치하는 결과에 대해 전체 문서 조회를 수행하고 결과를 클라이언트 에 반환합니다. $search 쿼리 에 동시 옵션을 사용하는 경우 MongoDB Search는 쿼리 내 병렬 처리를 활성화합니다. 자세히 학습 세그먼트 간 쿼리 실행 병렬 처리를 참조하세요.
클러스터 의 모든 검색 노드를 삭제 하면 검색 쿼리 결과 처리 중단됩니다. 자세히 학습 클러스터 수정을 참조하세요. Atlas cluster 삭제 하면 Atlas 일시 중지된 후 연결된 모든 MongoDB Vector Search 배포(mongot 프로세스)를 삭제합니다.
혜택
이 배포 모델은 다음과 같은 이점을 제공합니다.
Atlas Search 워크로드에 대한 리소스의 고가용성을 보장하면서 리소스를 효율적으로 활용하세요.
데이터베이스 배포와 독립적으로 Atlas Search 배포의 크기를 조정하고 확장할 수 있습니다.
MongoDB Vector Search 쿼리를 동시에 자동으로 프로세스 특히 대규모 데이터 세트의 응답 시간을 개선합니다. 자세한 학습 은 세그먼트 간 병렬 쿼리 실행을 참조하세요.
프로덕션을 위한 검색 노드 크기 조정
MongoDB Vector Search는 메모리에 전체 인덱스 보유하므로 MongoDB Vector Search 인덱스 및 JVM 위한 메모리가 충분한지 확인해야 합니다. 검색 노드를 사용하면 데이터 격리 없이 워크로드 격리 할 수 있으며, RAM 할당량의 거의 90%를 벡터 데이터와 인덱스를 메모리에 저장 데 사용할 수 있으며 나머지는 JVM 에 사용할 수 있습니다.
각 인덱스는 인덱싱되는 벡터와 추가 메타데이터의 조합입니다. 인덱스 크기는 주로 인덱싱하는 벡터의 크기에 따라 결정되며 메타데이터 공간은 일반적으로 상대적으로 작습니다. 자세한 내용은 벡터 인덱싱을 위한 메모리 요구 사항을 참조하세요.
전용 검색 노드를 배포하면 다양한 검색 계층을 선택할 수 있습니다. 각 검색 계층에는 기본 RAM 용량, 저장 용량 및 CPU가 있습니다. 이를 통해 데이터베이스 배포와 독립적으로 클러스터 크기를 지정하고 확장할 수 있습니다. 검색 배포를 개별적으로 확장하기 위해 클러스터 구성을 언제든지 다음과 같이 변경할 수 있습니다.
클러스터의 검색 노드 수를 조정합니다.
Atlas Search 계층을 변경하여 노드의 CPU, RAM 및 스토리지를 조정합니다.
참고
검색 노드와 검색 계층 비용에 대해 자세히 알아보려면 MongoDB 가격 페이지에서 View all plan features를 확장하고 Atlas Vector Search를 클릭하세요.
노드 에는 MongoDB Vector Search 인덱스의 총 크기보다 최소 10% 더 큰 RAM 있는 것이 좋습니다. 또한 사용 가능한 CPU가 충분한지 확인하는 것이 좋습니다. 쿼리 지연 시간 사용 가능한 CPU 수에 따라 달라지며, 이는 쿼리 성능을 가속화하는 내부 동시성 수준에 상당한 영향 수 있습니다.
예시
크기가 약 3GB인 1M 768차원 벡터가 있다고 가정해 보겠습니다. S30(저 CPU) 및 S20(고 CPU) 검색 계층 모두 인덱스를 지원하기에 충분한 RAM을 갖추고 있습니다. S20(고 CPU) 검색 계층에는 쿼리를 동시에 실행하는 데 사용할 수 있는 CPU가 더 많으므로 S30(저 CPU) 검색 계층에 배포하는 것보다 S20(고 CPU) 검색 계층에 배포하는 것이 좋습니다.
미사용 데이터 암호화 활성화
기본값으로 MongoDB와 검색 프로세스 는 동일한 노드에서 실행. 이 아키텍처에서는 고객 관리 암호화 데이터베이스 데이터에 적용되지만 검색 인덱스에는 적용 되지 않습니다.
전용 검색 노드를 활성화 하면 검색 프로세스가 별도의 노드에서 실행 . 이를 통해 검색 노드 데이터 암호화를 활성화 할 수 있으므로 동일한 고객 관리 키로 데이터베이스 데이터와 검색 인덱스를 모두 암호화하여 포괄적인 암호화 적용 범위를 확보할 수 있습니다.
자세한 내용은 검색 노드에 대한 고객 키 관리 활성화를 참조하세요.
참고
이 기능은 KMS 제공자 전반에서 사용할 수 있지만 검색 노드는 AWS에 있어야 합니다.
전용 Atlas Search 노드로 마이그레이션
전용 검색 노드를 사용하면 클러스터와 별도로 검색 배포의 크기를 조정하고 확장할 수 있습니다. 또한 동일한 노드에서 데이터베이스와 검색 프로세스를 모두 실행하는 클러스터에서 발생할 수 있는 리소스 경합을 제거합니다.
전용 검색 노드로 마이그레이션하려면 배포를 다음과 같이 변경합니다.
현재 배포에서 프리 티어 클러스터 또는 Flex 클러스터를 사용하는 경우 클러스터를 상위 계층으로 업그레이드하세요. 전용 검색 노드는
M10이상의 클러스터 클러스터 계층에서만 지원됩니다. 다른 클러스터 계층으로 마이그레이션하는 방법에 대해 자세히 알아보려면 Cluster Tier 수정을 참조하세요.전용 검색 노드는 Amazon Web Services 및 Azure 리전의 하위 집합과 지원되는 모든 Google Cloud Platform 리전에서 사용할 수 있습니다. 검색 노드도 사용할 수 있는 리전에 클러스터 배포 해야 합니다. 기존 클러스터 검색 노드를 사용할 수 없는 리전에 있는 경우 클러스터 검색 노드를 사용할 수 있는 리전으로 마이그레이션 . 자세한 학습 은 클라우드 제공자 리전을 참조하세요.
Search Nodes for workload isolation을 활성화하고 검색 노드를 구성합니다. 자세한 내용은 검색 노드 추가를 참조하세요.