Key value databases, also known as key value stores, are NoSQL database types where data is stored as key value pairs and optimized for reading and writing that data. The data is fetched by a unique key or a number of unique keys to retrieve the associated value with each key. The values can be simple data types like strings and numbers or complex objects.
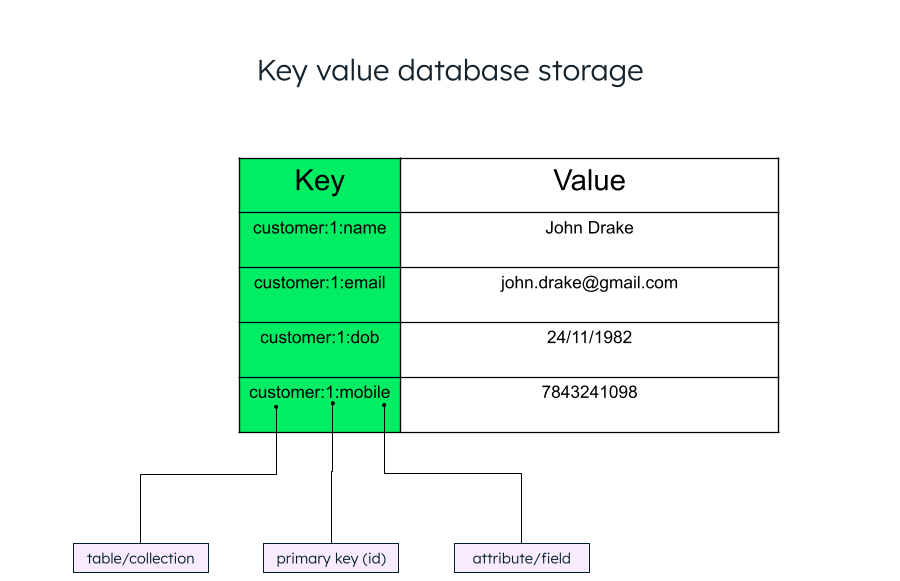
The unique key can be anything. Most of the time, it is an id field, since that's the unique field in all the documents. To group related items, you can also add a common prefix to the key. The general structure of a key value pair is key: value. For example, “name”: “John Drake.”
Table of contents
- Types of key value databases
- How do key value databases work?
- What are the features of a key value database?
- When to use key value stores
- MongoDB as a key value store
- Key value database vs cache
- Advantages of key value databases
- Summary
- FAQs
Over the years, database systems have evolved from legacy relational databases storing data in rows and columns to distributed databases allowing a solution per use case. Key value pair stores are not a new concept and have been around for the last few decades. One of the known stores is the old Microsoft Windows Registry allowing the system/applications to store data in a “key value” structure, where a key can be represented as a unique identifier or a unique path to the value.
Data is written (inserted, updated, and deleted) and queried based on the key to store/retrieve its value.
Types of key value databases
Key value databases are optimized for performance, and depending on the use case, there are different types of key value databases. For example, if your purpose of using a key value database is caching, then you can use an in-memory key value store. If you are looking for persistent storage (disk), you can use a persistent key value database. There are also multi-model key value databases that support multiple data models, like document, graph, and key value, thus offering flexibility. Examples of popular key value databases are:
- In-memory key value databases: MongoDB.
- Persistent key value databases: MongoDB.
- Multi-model key value databases: MongoDB.
How do key value databases work?
A key value database, AKA key value store, associates a value (which can be anything from a number or simple string to a complex object) with a unique identifier (key), which is used to keep track of the object. In its simplest form, a key value store is like a dictionary/array/map object as it exists in most programming paradigms but is managed by a database management system (DBMS).
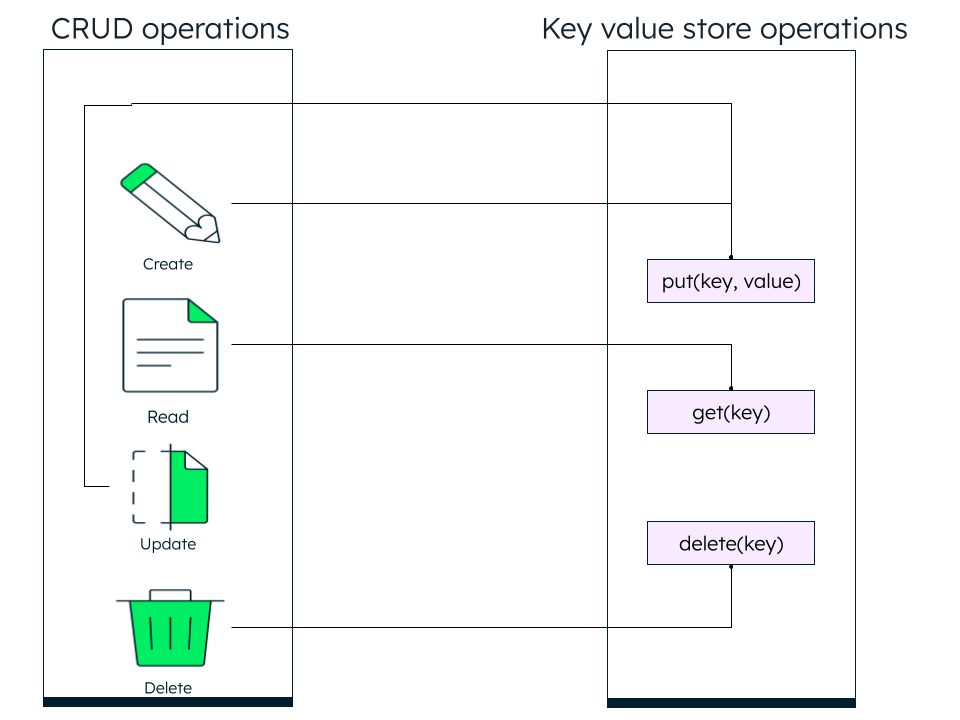
There are three main operations performed by a key value database:
- put(key, value): insert or update a value into the database.
- get(key): read a value from the database.
- delete(key): delete a value from the database.
Key value database schema
Unlike relational databases, key value data stores do not follow a specific schema, making them flexible. This makes them a good choice for unstructured and semi structured data. Storing and retrieving data becomes much simpler when it is done in a key value store when compared to that of relational database table structure. In the below image, due to the JSON structure, all the data is grouped together. You can store anything from simple types to complex types as values. While fetching the data, you can retrieve the individual records by iterating through the JSON data.
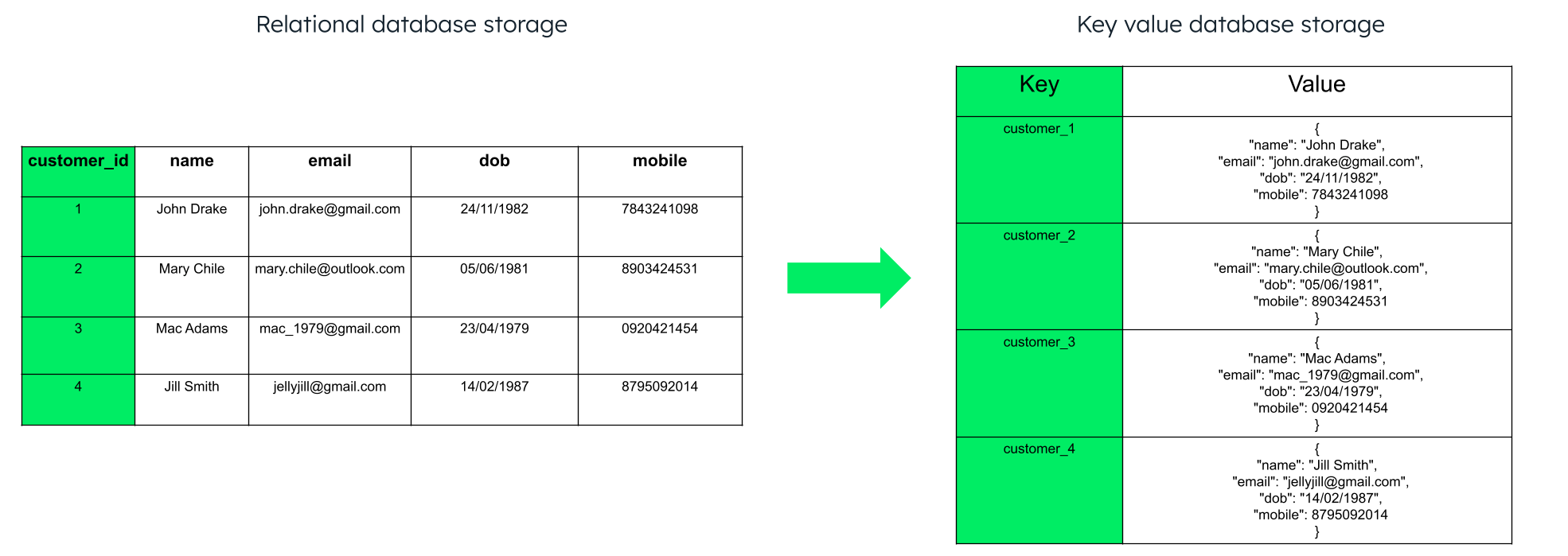
Grouping similar items in key value stores
In general, you can store an item as an individual key value pair. However, for storing complex objects like a customer, you will want to store all the related details, like the customer name and email address, as related data. You can group related items by using a consistent naming convention for keys (like a prefix). For example, we can have the key as “customer:1,” “customer:2,” and so on. To read such related data, you can iterate through the keys with common prefixes.
Key value databases use compact, efficient index structures to be able to quickly and reliably locate a value by its key, making them ideal for systems that need to be able to find and retrieve data in constant time.
Document databases like MongoDB not only support quick retrievals even with complex data types, but also provide more advanced querying capabilities. MongoDB has the advantage of acting like a key value store database when the data types are simple, while it works as a full-fledged document database when more complex data types or nested structures are involved.
Redis is a key value database that is optimized for tracking relatively simple data structures (primitive types, lists, heaps, and maps) in a persistent database. By only supporting a limited number of value types, Redis is able to expose an extremely simple interface to querying and manipulating them, and when configured optimally is capable of high throughput.
What are the features of a key value database?
A key value database is defined by the fact that it allows programs or users of programs to retrieve data by keys, which are essentially names, or identifiers, that point to some stored value. Because key value databases are defined so simply, it's easy to get the accurate information in less time. Below are some important features of key value databases:
Flexible data models
Key value databases do not have a fixed schema or table structure. Hence, as data evolves, it is easy to move key value stores from one system to another without any changes to the architecture or design. Flexible data structure also ensures speed and scalability.
No query language
As there is no fixed structure, key value databases do not need a query language for CRUD operations. You can simply give the key as input and get the values as output. Some key value databases support advanced capabilities for querying—for example, retrieving a set of related items, aggregations, text search, and partial field retrieval.
Support for complex data types
Along with simple types like string or number, key value databases can also support data types like arrays, JSON, date, media files (binary data), and nested structures.
Indexing support for performance
Advanced key value databases support various types of indexing apart from primary indexing, like secondary indexing, hash indexing, tree-based indexing, and wild card indexing, to improve performance and efficiency of data retrieval.
When to use key value stores
There are several use-cases where choosing a key value store approach is an optimal solution:
Real time random data access, e.g., user session attributes in an online application such as gaming or finance
Caching mechanism for frequently accessed data or configuration based on keys
Application is designed on simple key-based queries
MongoDB as a key value store
While MongoDB is primarily a document database, it does cover a wide range of database examples and use cases, supporting key value pair data concepts. With its flexible schema and rich query language with secondary indexes, MongoDB is a compelling store for “key value” data.
Learn more in this article and try it with MongoDB Atlas, MongoDB's database-as-a-service platform.
MongoDB stores data in collections, which are a group of BSON (Binary JSON) documents where each document is essentially built from a field-value structure. The ability of MongoDB to efficiently store flexible schema documents and perform an index on any of the additional fields for random seeks makes it a compelling key value store.
{
session_id : "ueyrt-jshdt-6783-utyrts",
create_time : 1122384666000
}Further, MongoDB's document values allow nested key value structures, allowing not only for accessing data by key in a global sense, but accessing and manipulating data associated with keys within documents, and even creating indexes that allow fast retrieval by these secondary kinds of keys.
{
name: "John",
age : 35,
dob : ISODate("01-05-1990"),
profile_pic : "https://example.com/john.jpg",
social : {
twitter : "@mongojohn",
linkedin : "https://linkedin.com/abcd_mongojohn"
}
}MongoDB’s native drivers support multiple top used languages like Python, C#, C++, and Node.js, allowing you to store the key value data in your language of choice.
Secondary indexes to support key value
Each one of the fields can be indexed based on your query patterns. For example, if we seek for a specific session_id as the key and the create_time as a value, we can index
db.sessions.createIndex({session_id : 1}) and query on that key:
db.sessions.find({session_id : "ueyrt-jshdt-6783-utyrts" },{create_time : 1}).create_time;Wild card indexes to support key value
Wild card indexing allows users to index every field or a subset of fields in a MongoDB collection. Therefore, if we have a set of field-value types stored in a single document and queries could come dynamically for each identifier, we can create a single index for those field value sets.
db.profiles.createIndex({"$**" : 1 });As a result, our queries will have a full per field-value query supported by this index. Having said that, wild card indexing should only be used in use cases when we cannot predict the field names upfront and the variety of the queries predicates require so. See wild card restrictions for more information.
Schema design to support key value
Since MongoDB documents can be complex objects, applications can use a schema design to minimize index footprints and optimize access for a “key-value” approach. This design pattern is called the Attribute Pattern and it utilizes arrays of documents to store a “key-value” structure.
attributes: [
{
key: "USA",
value: ISODate("1977-05-20T01:00:00+01:00")
},
{
key: "France",
value: ISODate("1977-10-19T01:00:00+01:00")
},
{
key: "Italy",
value: ISODate("1977-10-20T01:00:00+01:00")
},
{
key: "UK",
value: ISODate("1977-12-27T01:00:00+01:00")
},
...
]Indexing {attributes.key : 1 , attributes.value : 1} will allow us to search on any key with just one index.
Key-value database vs cache
Databases supporting key-value stores persist the data to a disk serving the database files, while a key-value cache implementation will mostly keep the data loaded in memory. In case of a server fault or restart, the data needs to be preloaded into the cache as it was not persistent.
MongoDB uses the cache of its WiredTiger engine to optimize data access and read performance together with strong consistency and high availability across replica sets. This allows for more resilient and available field-value stores while still using the best performance of cached data.
Advantages of key value databases
A key value approach allows defining efficient and compact data structure to access data in a simple form of a key value fetch/update/remove.
MongoDB documents can form compact flexible structures to support fast indexing for your key value stores. On the other hand, MongoDB documents may consist of rich objects which can contain entire hierarchies and sub-values, and sophisticated indexing allows documents to be retrieved by any number of different keys.
Summary
Key value stores are used for use cases where applications will require values to be retrieved fast via keys, like maps or dictionaries in programming languages. The compact structure and straightforward indexing and seeking through those indexes makes this database concept a win for specific application workloads.
However, modern applications will probably require more than just a key value retrieval, and this is where MongoDB and MongoDB Atlas offer the optimal solution. MongoDB can support the field-value store solution while allowing complex objects to be formed and multiple ways to query the data: full-text search, aggregation framework, Atlas data tiering, or scaling it across multiple shards.
FAQs
What is a key-value database?
A key value database is a type of NoSQL database that stores data in the form of key value pairs—for example, “name”: “John Drake.” Here, the name is the unique key that identifies the object, and John Drake is the value associated with it.