Opções de implantação do Atlas Search
Nesta página
É possível estruturar seu Atlas cluster com diferentes tipos de sistema, provedores de nuvem e camadas de cluster para atender às necessidades de um ambiente de pré-produção ou produção. Use essas recomendações para selecionar o tipo de sistema, o provedor de nuvem e a região, e as camadas do cluster e Atlas Search para executar a Atlas Search vetorial.
ambiente | Tipo de implementação | Camada do cluster | Região do provedor de nuvem | Arquitetura de nó |
|---|---|---|---|---|
Testando queries | Shared or dedicated cluster Local deployment | M0, M2, M5, or higher tierN/A | All N/A | Processos do MongoDB e Atlas Search executados no mesmo nó |
Aplicativos de protótipos | Cluster dedicado, fragmentado ou não fragmentado |
| Todos | Processos do MongoDB e Atlas Search executados no mesmo nó |
Produção | Cluster dedicado com nós de pesquisa separados, fragmentados ou não fragmentados |
| Amazon Web Services e Azure em algumas regiões do ou Google Cloud Platform em todas as regiões | Processos do MongoDB e Atlas Search executados em nós diferentes |
Para saber mais sobre esses modelos de sistema, revise as seguintes seções:
Ambientes de teste e protótipos
Para testar suas queries de pesquisa e criar protótipos do seu aplicativo, recomendamos a seguinte configuração. Essa configuração é mais adequada para os seguintes casos de uso:
Menos de 2 milhões de documentos no total para indexar.
Menos de 10GB de dados indexados.
Menos de 10.000 queries em um período 7 dias.
Se seu uso exceder os valores listados, migre para nós de pesquisa separados.
Tipo de implementação
Para testar as consultas do Atlas Search, você pode implantar um cluster compartilhado ou dedicado ou implantações locais do Atlas.
Cluster Tiers
Os clusters compartilhados incluem os níveis M0, M2 e M5 . Esses tipos de cluster de baixo custo estão disponíveis para testar suas consultas do Atlas Search . No entanto, você pode enfrentar contenção de recursos e latência de consulta em clusters compartilhados. Se você iniciar seu projeto com um cluster compartilhado, recomendamos atualizar para uma camada mais alta quando seu aplicativo estiver pronto para produção.
Os clusters dedicados incluem M10 e níveis superiores. As camadas M10 e M20 são adequadas para a prototipagem de seu aplicação. Você pode fazer o upgrade para níveis mais altos para lidar com grandes conjuntos de dados ou implantar nós de pesquisa dedicados para isolamento da carga de trabalho quando seu aplicativo estiver pronto para produção.
Provedor de nuvem e região
Todos os níveis de cluster estão disponíveis em todas as regiões de provedores de nuvem compatíveis. O provedor de nuvem e a região escolhidos afetam as opções de configuração disponíveis para as camadas do cluster e o custo de execução do cluster.
Se preferir testar as queries do Atlas Search localmente, você pode usar a Atlas CLI para implantar um conjunto de réplicas de nó único hospedado em seu computador local. Para saber mais, consulte Como criar uma implantação local do Atlas.
Quando seu aplicativo estiver pronto para produção, migre sua implantação local do Atlas para um ambiente de produção usando o Migração em produção. As implantações locais são limitadas pelos recursos de CPU, memória e armazenamento de seu computador local.
Arquitetura de nó
Neste modelo de implantação, o processo de pesquisa mongot é executado ao lado do mongod em cada nó no cluster do Atlas. O processo mongod roteia queries para o mongot no mesmo nó e eles compartilham os mesmos recursos.

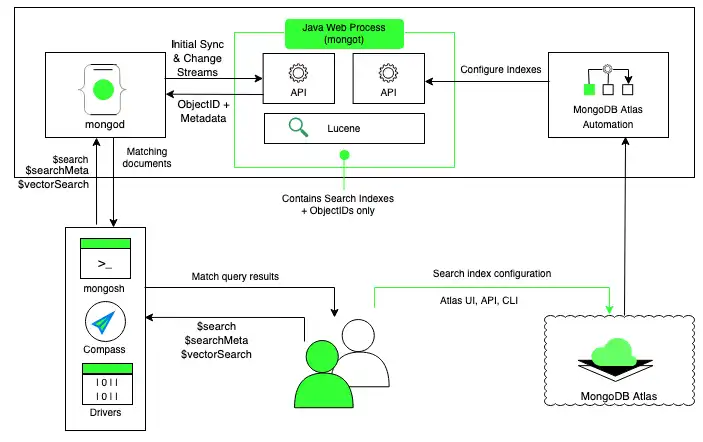
Por padrão, o Atlas habilita o processo de pesquisa mongot no mesmo nó que executa o processo mongod quando você cria seu primeiro índice do Atlas Search. O processo mongot executa as ações descritas em Sobre o processo mongot.
Você pode definir campos de origem armazenados no seu índice do Atlas Search para que o processo mongot possa armazenar os campos especificados em mongot. Você pode então usar a opção returnStoredSource na sua query do Atlas Search para recuperar os campos armazenados para documentos correspondentes diretamente de mongot em vez de fazer uma pesquisa completa de documentos no banco de dados.
Veja também:
Benefícios
Quando você habilita o Atlas Search, pode facilmente construir uma pesquisa em cima de seus dados com um mecanismo de pesquisa integrado e totalmente gerenciado que se sincroniza automaticamente com seu banco de dados. O Atlas Search fornece uma linguagem de query avançada que usa estágios de pipeline de agregação do Atlas Search, como $search e $searchMeta para pesquisa de texto completo e $vectorSearch para pesquisa semântica em conjunto com outros estágios de pipeline de agregação do MongoDB e classificação de resultados baseada em pontuação.
Implantar ambos os processos no mesmo nó pode ser mais econômico, dependendo dos recursos provisionados para o seu cluster, do que executar o processo de pesquisa em um nó separado e dedicado.
Limitações
Você pode experimentar a contenção de recursos entre o mongod do banco de dados e os processos mongot de pesquisa. Isso pode afetar negativamente o desempenho do índice e a latência das queries. Recomendamos este modelo de implantação apenas para ambientes de teste e prototipagem. Para aplicativos prontos para produção e cargas de trabalho de pesquisa associadas, recomendamos migrar para nós de pesquisa dedicados.
Custo
Não há taxas ou encargos adicionais quando você ativa a O Atlas Search no seu cluster do Atlas. No entanto, você pode observar um aumento na utilização de recursos no cluster, dependendo de fatores como o tamanho das collections indexadas ou definições de índice.
Considerações
Como os processos mongod e mongot são executados no mesmo nó, mongot pode ficar indisponível em determinadas circunstâncias. A tabela a seguir descreve as possíveis causas:
Causa | Descrição |
|---|---|
Dimensionamento da camada do cluster - Armazenamento de rede | Quando você escala um cluster para cima ou para baixo, o Atlas provisiona uma nova instância. Após a instância estar pronta, o Atlas anexa o armazenamento de rede e inicia Se o |
Dimensionamento da camada do cluster - SSD local | Quando você escala um Atlas cluster usando o SSD local, não é possível reter o armazenamento e anexe-o novamente aos novos nós. Portanto, o Atlas executa uma sincronização inicial para reconstruir os índices de pesquisa. As queries de pesquisa falham até que a sincronização inicial seja concluída. |
Downgrade do Lucene | Em casos raros em que é necessário fazer o downgrade do Lucene, talvez você não consiga ler os formatos de índice Lucene mais recentes. |
Ajuste de armazenamento | Você pode manter o armazenamento de rede conectado aos nós do Atlas cluster. Isso permite que você expanda ou contraia a capacidade de volume sem impacto para No entanto, reter o armazenamento de rede pode não ser possível em determinadas regiões, quando o cluster estiver usando discos NVMe locais ou em outras circunstâncias raras. Nesses casos, o Atlas executa uma sincronização inicial e as queries de pesquisa falham até que a sincronização inicial seja concluída. |
| Durante uma atualização de versão do |
Novo nó | Quando você adiciona um novo nó ao seu cluster, o Atlas executa uma sincronização inicial para criar os índices de pesquisa. As queries de pesquisa que usam o novo nó |
Reinicialização ou substituição da instância |
|
| Sempre que o processo |
Ambiente de produção
Para seu aplicativo pronto para produção, recomendamos a seguinte configuração de cluster. Essa configuração é adequada para os seguintes casos de uso:
Total de documentos maior que 2M a serem indexados.
Maior que 10GB de dados indexados.
Maior que 10.000 consultas em um período 7 dias.
Tipo de implementação
Para aplicativos prontos para produção, você precisa de um cluster dedicado.
Cluster Tiers
Os clusters dedicados incluem M10 e níveis superiores. As camadas M10 e M20 são adequadas para ambientes de desenvolvimento e produção. No entanto, os níveis mais altos podem lidar com grandes conjuntos de dados e cargas de trabalho de produção. Recomendamos que você também implante nós de pesquisa dedicados para sua carga de trabalho de pesquisa. Isso permite que você dimensione sua implementação de pesquisa de forma independente e adequada.
Provedor de nuvem e região
Os nós de pesquisa estão disponíveis em todas as regiões da Google Cloud Platform, mas estão disponíveis apenas em um subconjunto de regiões da Amazon Web Services e do Azure . Você deve selecionar um provedor de nuvem e uma região onde os nós de pesquisa estejam disponíveis para sua implementação.
Todas as camadas de cluster estão disponíveis em regiões de provedores de nuvem com suporte. O provedor de nuvem e a região que você escolher afetam as opções de configuração e as camadas de pesquisa disponíveis para o cluster e o custo de execução do cluster.
Arquitetura de nó
Nesse modelo de implantação, o processo mongot é executado em nós de pesquisa, que são separados dos nós do cluster nos quais o processo mongod é executado. O Atlas implanta nós de pesquisa com cada cluster ou com cada fragmento no cluster.
Por exemplo, se você implantar dois nós de pesquisa para um cluster com três fragmentos, o Atlas implantará seis nós de pesquisa, dois para cada fragmento. Você também pode configurar o número de nós de pesquisa e a quantidade de recursos provisionados para cada nó de pesquisa.
Ao implantar nós de pesquisa separados, o Atlas atribui automaticamente um mongod para cada mongot para indexação. O mongot se comunica com o mongod para ouvir e sincronizar as alterações de índice para os índices que armazena. O Atlas Search indexa e processa suas consultas de forma semelhante a quando os processos mongod e mongot são executados no mesmo nó. Para mais informações, consulte Criar e gerenciar índices do Atlas Search e Criar e executar queries no Atlas Search. Para saber mais sobre a implantação de nós de pesquisa separadamente, consulte Nós de pesquisa para isolamento de carga de trabalho.

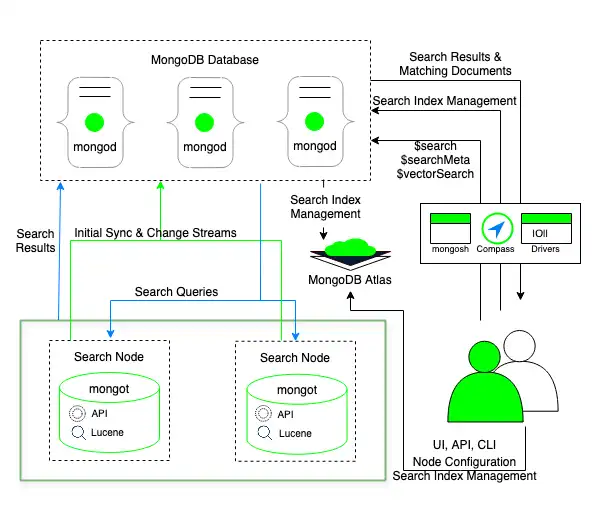
Quando você migra para os Nós de Pesquisa, o Atlas implanta os Nós de Pesquisa, mas não atende a queries nos nós até que ele crie com êxito todos os índices no cluster nos Nós de Pesquisa. Enquanto o Atlas cria os índices nos novos nós, ele continua a atender queries usando os índices nos nós do cluster. O Atlas começa a atender queries dos nós de pesquisa somente depois de criar com êxito os índices nos nós de pesquisa e remover os índices nos nós do cluster.
Se você excluir todos os nós de pesquisa em seu cluster, haverá uma interrupção no processamento dos resultados da query de pesquisa. Para saber mais, consulte Modificar um cluster. Se você excluir seu agrupamento do Atlas, o Atlas pausará e então excluirá todos os sistemas do Atlas Search associados (processosmongot).
Você pode definir campos de origem armazenados no seu índice do Atlas Search para que o processo mongot possa armazenar os campos especificados em mongot. Você pode então usar a opção returnStoredSource na sua query do Atlas Search para recuperar os campos armazenados para documentos correspondentes diretamente de mongot em vez de fazer uma pesquisa completa de documentos no banco de dados.
Benefícios
A distribuição de nós de pesquisa separados oferece os seguintes benefícios:
- Alta disponibilidade
- Quando você implanta nós de pesquisa separados, o Atlas aplica um mínimo de dois nós de pesquisa para garantir que sua carga de trabalho permaneça operacional, com tempo mínimo de inatividade, em evento de falha ou interrupção.
- Escalabilidade
Quando distribui nós de pesquisa separados, você pode fazer o seguinte:
Dimensione o armazenamento e o compute independentemente do cluster MongoDB.
Dimensiona a carga de query independentemente do MongoDB.
Você pode dimensionar os nós de pesquisa horizontalmente e verticalmente.
Você pode aumentar ou reduzir o número de nós de pesquisa e escalar horizontalmente seu cluster. Você pode provisionar entre um mínimo de 2 e um máximo de 32 nós de pesquisa, ambos incluídos. O Atlas Search distribui suas consultas para execução nos nós de pesquisa percorrendo a lista de nós de pesquisa disponíveis, o que permite equilibrar a carga de consultas em todos os nós provisionados.
Você pode selecionar diferentes níveis para seus nós de pesquisa. Os diferentes níveis de pesquisa permitem que você selecione as configurações de CPU, RAM e armazenamento mais apropriadas para sua carga de trabalho vetorial e de full-text.
- Desempenho
Ao implantar nós de pesquisa separados, você melhora o desempenho e a utilização dos recursos dos processos
mongodemongote elimina a contenção de recursos entre os dois processos.Os nós de pesquisa dedicados oferecem suporte à pesquisa simultânea de segmentos, o que permite que o Atlas Search pesquise vários segmentos de índice ao mesmo tempo e melhore o tempo de resposta da query em alguns casos. Para saber mais, consulte Paralelizar a execução de query entre segmentos.
Dimensione e amplie seu cluster
Para determinar a quantidade de memória que você precisará nos nós de pesquisa, use as seguintes métricas do Atlas:
Tamanho do Índice de Pesquisa
RAM total no nó de pesquisa
Por exemplo, considere o seguinte:
Tamanho do índice de pesquisa = 10GB
Total de RAM no nó de pesquisa = 4GB
Dos 4GB de RAM, suponha que 1GB seja usado por outros processos e apenas 3GB estejam disponíveis para os dados de índice. Portanto, os 7GB restantes dos dados de índice (10GB - 3GB = 7GB) são paginados, conforme necessário, do disco. A paginação frequente do disco (7GB) causa aumento de falhas de página, E/S de disco e IOWait da CPU, resultando em degradação do desempenho.
Um nível de pesquisa mais alto com mais RAM (8GB ou mais) permite que a maioria dos dados do índice de pesquisa sejam fornecidos pela memória, minimizando as leituras de disco e as falhas de página, melhorando assim o desempenho.
Observação
Os SSDs locais usados para nós de pesquisa exigem uma sobrecarga de armazenamento de 20% para permitir operações de indexação.
Custo dos Nós de Pesquisa
O MongoDB permite nós de pesquisa separados em clusters dedicados (M10 ou superior). Os nós de pesquisa são distribuídos em instâncias NVMe com uso intensivo de computador. Você deve distribuir um mínimo de dois nós. Você será cobrado diariamente pelo uso de recursos por hora por nó. Para saber mais, consulte Custo do nó de pesquisa.
Habilitar Encryption at rest
Você pode ativar a Encryption at rest com o Customer Key Management para todos os dados nos nós de pesquisa para proteger suas cargas de trabalho do Atlas Search com chaves de criptografia gerenciadas pelo cliente. Para saber mais, consulte Habilitar gerenciamento de chaves do cliente para nós de pesquisa.
No momento, esse recurso está disponível apenas para o AWS KMS.
Migrar para nós dedicados do Atlas Search
Com nós de pesquisa dedicados, você pode dimensionar sua implantação de pesquisa separadamente do cluster. Eles também eliminam qualquer contenção de recursos que você possa enfrentar em um cluster que executa o banco de dados e os processos de pesquisa no mesmo nó.
Para migrar para nós de pesquisa dedicados, faça as seguintes alterações na sua implantação:
Se atualmente sua implantação estiver usando uma nível compartilhado, atualize seu cluster para um nível superior. Os nós de pesquisa dedicados são compatíveis somente com níveis de cluster
M10e superiores. Para saber mais sobre como migrar para uma camada do cluster diferente, consulte Modificar o Cluster Tier.Os nós de pesquisa dedicados estão disponíveis em um subconjunto das regiões da Amazon Web Services e do Azure, e em todas as regiões do Google Cloud Platform compatíveis. Certifique-se de implementar seu cluster em regiões onde os nós de pesquisa também estão disponíveis. Se o cluster existente estiver em regiões onde os nós de pesquisa não estão disponíveis, migre-o para regiões onde os nós de pesquisa estão disponíveis. Para saber mais, consulte Regiões do fornecedor de nuvem.
Habilite Search Nodes for workload isolation e configure nós de pesquisa. Para saber mais, consulte Adicionar nós de pesquisa.
Quando você implanta nós de pesquisa separados, o Atlas Search continua a atender queries usando os índices no cluster Atlas, enquanto o Atlas cria os índices nos nós de pesquisa. O Atlas encaminha as queries para os nós de pesquisa somente depois de concluir o seguinte:
Cria com sucesso todos os índices nos nós de pesquisa.
remove os índices de pesquisa dos nós do cluster.