Sincronização baseada em partição
Nesta página
- Conceitos chave
- Termos-chave
- Partição
- Chave de partição
- Altere uma chave de partição
- Valor da partição
- Ativar sincronização baseada em partição
- Antes de começar
- Procedimento
- Regras e permissões baseadas em partição
- Comportamento da Sincronização baseada em partição
- Permissões de sincronização baseadas em partições
- Conceitos chave
- Permissões de leitura
- Permissões de Escrita
- Estratégias de permissão
- Permissões globais
- Permissões para partes específicas
- Permissões para usuários específicos
- Permissões baseadas em dados do usuário
- Regras de função
- Migrar regras de sincronização baseada em partição para as regras do App Services
- Estratégias de partição
- Estratégia de firehose
- Estratégia de usuário
- Estratégia de equipe
- Estratégia de canal
- Estratégia de região
- Estratégia de bucket
- Ingestão de dados
- Configuração de sincronização baseada em partição
- Altere sua configuração de sincronização baseada em partição
- Erros de Sincronização baseada em partição
- Compactação de backend
O Atlas Device Sync tem dois modos de sincronização: Sincronização flexível e a antiga sincronização baseada em partições. A sincronização baseada em partição foi descontinuada e não é permitida para novas configurações do Sync.
As informações nesta página são para usuários que ainda estão usando a sincronização baseada em partições.
Observação
Migrar da sincronização baseada em partição para a Flexible Sync
Recomendamos migrar aplicativos de sincronização baseada em partição para o Flexible Sync. Para obter mais informações sobre migração, consulte Migrar modos de Device Sync .
Conceitos chave
Na Sincronização Baseada em Partição, os documentos em um cluster sincronizado formam uma "partição" tendo o mesmo valor para um campo designado como "chave de partição". Todos os documentos em uma partição têm as mesmas permissões de leitura/gravação para um determinado usuário.
Você define uma chave da partição cujo valor determina se o usuário pode ler ou escrever um documento. O App Services avalia um conjunto de regras para determinar se os usuários podem ler ou escrever em uma determinada partição. Os Serviços de Aplicativo mapeiam diretamente uma partição para arquivos do .realm sincronizados individualmente. Cada objeto em um Realm sincronizado tem um documento correspondente na partição.
Exemplo
Considere um aplicativo de gerenciamento de inventário usando a Sincronização Baseada em Partição. Se você usar store_number como chave de partição, cada repositório poderá ler e gravar documentos referentes ao seu inventário.
Um exemplo das permissões para este tipo de app pode ser:
{ "%%partition": "Store 42" }
Os funcionários da loja poderiam ter acesso de leitura e gravação a documentos cujo número de loja fosse Loja 42.
Enquanto isso, os clientes poderiam ter acesso somente com leitura ao inventário da loja.
No cliente, você passa um valor para a chave de partição ao abrir um domínio sincronizado. Em seguida, os App Services sincronizam objetos cujo valor de chave de partição corresponde ao valor passado do aplicativo cliente.
Exemplo
Com base no exemplo de inventário de armazenamento acima, o SDK pode passar para store42 como o partitionValue na configuração de sincronização. Isso sincronizaria qualquer item de inventário cujo partitionValue fosse store42.
Você pode usar dados personalizados do usuário para indicar se um usuário conectado é funcionário da loja ou cliente. Os funcionários da loja teriam permissão de leitura e gravação para o conjunto de dados store42, enquanto os clientes só teriam permissão de leitura para o mesmo conjunto de dados.
const config = { schema: [InventoryItem], // predefined schema sync: { user: app.currentUser, // already logged in user partitionValue: "store42", }, }; try { const realm = await Realm.open(config); realm.close(); } catch (err) { console.error("failed to open realm", err.message); }
O Device Sync exige que os MongoDB Atlas clusters executem versões específicas do MongoDB. A sincronização baseada em partição requer MongoDB 4.4.0 ou superior.
Termos-chave
Partição
Uma partição é uma coleção de objetos que compartilham o mesmo valor-chave de partição.
Um Atlas cluster MongoDB consiste em vários servidores remotos. Esses servidores fornecem o armazenamento para seus dados sincronizados. O Atlas cluster armazena documentos em coleções. Cada coleção MongoDB mapeia para um tipo de objeto de Realm diferente. Cada documento em uma coleção representa um objeto específico do Realm.
Um domínio sincronizado é um arquivo local em um dispositivo. Um domínio sincronizado pode conter alguns ou todos os objetos relevantes para o usuário final. Um aplicativo cliente pode usar mais de um domínio sincronizado para acessar todos os objetos que o aplicativo precisa.
As partições vinculam objetos no banco de dados do Realm a documentos no MongoDB. Quando você inicializa um arquivo de Realm sincronizado, um de seus parâmetros é um valor da partição. Sua aplicativo cliente cria objetos no realm sincronizado. Quando esses objetos são sincronizados, o valor da partição se torna um campo nos documentos do MongoDB. O valor deste campo determina quais documentos do MongoDB o cliente pode acessar.
Em alto nível:
Uma partição mapeia para um subconjunto dos documentos em um cluster sincronizado.
Todos os documentos em uma partição têm as mesmas permissões de leitura/escrita para um determinado usuário.
Atlas App Services mapeia cada partição para um arquivo
.realmsincronizado individualmente.Cada objeto em um domínio sincronizado tem um documento correspondente na partição.

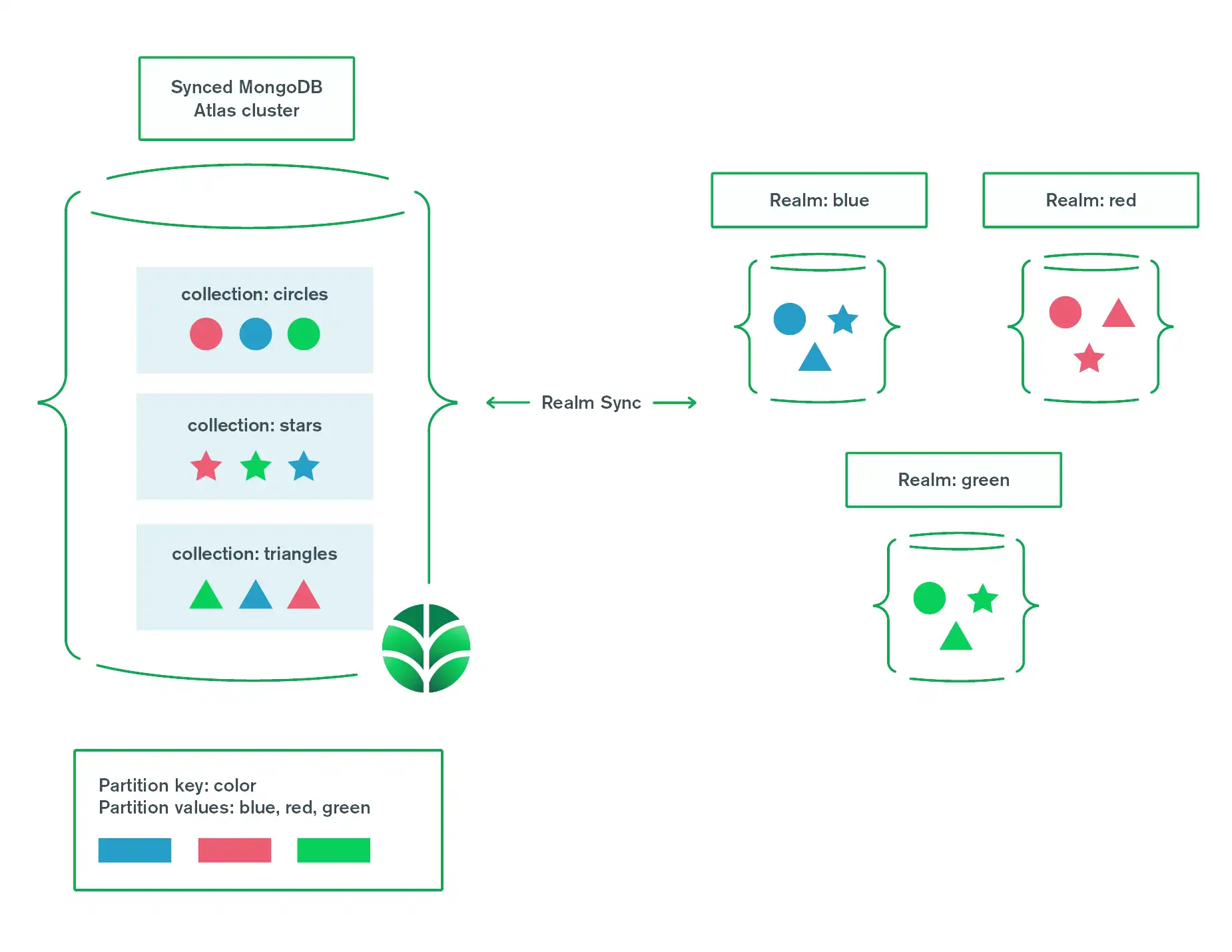
As partições moldam os dados em um Atlas cluster. Cada forma representa um tipo de objeto. As partições são determinadas pelo color de cada forma: vermelho, verde ou azul.
Chave de partição
Uma chave de partição é um campo nomeado que você especifica ao configurar o Atlas Device Sync. A sincronização de dispositivos usa essa chave para determinar qual partição contém um determinado documento.
Dependendo do modelo de dados e da complexidade do aplicativo, sua chave de partição pode ser:
Uma propriedade que já existe em cada documento e que logicamente particiona os dados. Por exemplo, considere um aplicativo onde cada documento é privado para um usuário específico. Você pode armazenar o valor de ID do usuário em um campo
owner_ide, em seguida, usá-lo como chave de partição.Uma propriedade sintética que você cria para dados de partição (por exemplo,
_partition). Você pode usar isso quando seu aplicativo não inclui uma chave de partição natural.
Você pode tornar a chave de partição obrigatória ou opcional em seus objetos. O App Services mapeia qualquer objeto que não inclua uma chave de partição para uma partição padrão - partição nula.
Considere o seguinte ao escolher uma chave de partição:
As chaves de partição devem ser um destes tipos:
String,ObjectID,LongouUUID.Os clientes do App Services nunca devem modificar o valor da partição diretamente. Você não pode usar nenhum campo que os clientes possam modificar como chave de partição.
As chaves de partição usam o mesmo nome de campo em todos os documentos sincronizados. A chave de partição não deve colidir com nenhum nome de campo no modelo de qualquer objeto.
Exemplo
Os seguintes esquemas demonstram chaves de partição naturais e sintéticas:
O campo
owner_idé uma chave natural porque já faz parte do modelo de dados do aplicativo.O campo
_partitioné uma chave sintética porque seu único objetivo é servir como uma chave de partição.
Um aplicativo só pode especificar uma única chave de partição, mas qualquer um destes campos pode funcionar dependendo do seu caso de uso:
{ "title": "note", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "text" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "text": { "bsonType": "string" } } } { "title": "notebook", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "notes" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "notes": { "bsonType": "array", "items": { "bsonType": "objectId" } } } }
Altere uma chave de partição
A chave de partição do seu aplicativo é uma parte central do modelo de dados de um aplicativo habilitado para sincronização. Quando você define uma chave de partição na configuração de sincronização, não é possível reatribuir posteriormente o campo da chave. Se você precisar alterar uma chave de partição, será necessário encerrar a sincronização. Em seguida, você pode habilitá-lo novamente com a nova chave de partição. No entanto, isso exige que todos os aplicativos do cliente redefinam e sincronizem dados em novos domínios.
Aviso
Restaurar a sincronização após encerrar a sincronização
Quando você encerra e reativa o Atlas Device Sync, os clientes não podem mais sincronizar. Seu cliente deve implementar um manipulador de redefinição de cliente para restaurar a sincronização. Este manipulador pode descartar ou tentar recuperar alterações não sincronizadas.
Valor da partição
Um valor de partição é um valor do campo chave de partição para um determinado documento. Documentos com o mesmo valor de partição pertencem à mesma partição. Eles sincronizam com o mesmo arquivo de Realm e compartilham permissões de acesso aos dados no nível do usuário.
O valor de uma partição é o identificador para seu domínio sincronizado correspondente. Você especifica o valor da partição quando a abre como um domínio sincronizado no cliente. Se você alterar um valor de partição no Atlas, o App Services interpretará a alteração como duas operações:
Uma exclusão da partição antiga.
Uma inserção na nova partição.
Aviso
Se você alterar o valor da partição de um documento, perderá as alterações não sincronizadas do lado do cliente no objeto.
Ativar sincronização baseada em partição
Antes de começar
Você precisará do seguinte para ativar a sincronização baseada em partição:
Um aplicativo do App Services. Para saber como criar um aplicativo, consulte Criar um Aplicativo.
Uma fonte de dados do Atlas vinculada. Para saber como adicionar uma fonte de dados, consulte Vincular uma fonte de dados.
Procedimento
Navegue até a tela de configuração de sincronização
Para definir as regras do Device Sync e ativar o Device Sync para seu aplicação, navegue até a tela de configuração do Device Sync através do menu de navegação esquerdo.
Observação
As Regras de Sincronização Não Podem ser Alteradas
Você define as regras do Device Sync ao mesmo tempo em que habilita o Device Sync. Depois que o Device Sync estiver habilitado, você não poderá alterar as regras do Device Sync do seu aplicativo, a menos que encerre o Device Sync e o reative com novas regras.

Escolher uma chave de partição
A chave de partição do Device Sync é um campo em cada documento sincronizado que mapeia cada documento para um realm do lado do cliente. As regras do Device Sync se aplicam ao nível da partição, portanto, é particularmente importante considerar seu modelo de dados e padrões de acesso. Para ver mais informações sobre chaves de partição e como escolher uma, consulte Partições.
Observação
A chave de partição pode ser obrigatória ou opcional. Se o campo da chave de partição for opcional, todos os documentos do MongoDB que excluam a chave de partição ou tenham um valor nulo para a chave de partição serão enviados para a partição nula. Se o campo da chave de partição for obrigatório, o Device Sync ignorará todos os documentos do MongoDB que não tenham um valor válido para a chave de partição. Recomendamos uma chave de partição obrigatória, a menos que você queira sincronizar dados pré-existentes com valores de partição inválidos ou ausentes de uma coleção do MongoDB.
Definir permissões de leitura e escrita
A seção Define Permissions permite que você defina expressões JSON que os Serviços de Aplicativo avaliam dinamicamente para determinar as permissões de leitura e escrita de um usuário para os dados em uma determinada partição.
As expressões de regra do Device Sync têm acesso a %%user, que é resolvida para o usuário que abriu a região, e %%partition, que resolve para o valor da chave de partição da região. Você também pode usar operadores, incluindo %function, para lidar com casos mais complexos. Para obter exemplos, consulte Permissões baseadas em funções.
Após determinar como decidir as permissões de leitura e escrita de um usuário para uma determinada partição, defina as expressões JSON correspondentes nas entradas Read e Write.
Verifique os comportamentos de configuração avançada padrão
Expanda a seção Advanced Configuration.
Aplicativos de Serviços de Aplicativos fornecem recursos avançados de otimização que são habilitados por padrão:
Se quiser alterar o período de tempo que um cliente pode ficar offline, você pode fazer isso na seção Advanced Configuration .
Obtenha a versão mais recente da sua aplicação
Obtenha uma cópia local dos arquivos de configuração do seu aplicativo. Para obter a versão mais recente do seu aplicativo, execute o seguinte comando:
appservices pull --remote="<Your App ID>"
Você também pode exportar uma cópia dos arquivos de configuração do aplicativo da interface do usuário ou com a API Admin. Para saber como, consulte Exporte um aplicativo.
Adicionar uma configuração de sincronização
Você pode habilitar a sincronização para um único cluster vinculado em seu aplicativo.
O aplicativo App Services tem um diretório sync onde você pode encontrar o arquivo de configuração de sincronização. Se você ainda não tiver ativado o Sync, esse diretório estará vazio.
Adicione um config.json semelhante a:
{ "type": "partition", "state": <"enabled" | "disabled">, "development_mode_enabled": <Boolean>, "service_name": "<Data Source Name>", "database_name": "<Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> }
Escolher uma chave de partição
A chave de partição de sincronização é um campo em cada documento sincronizado que mapeia cada documento para um realm do lado do cliente. As regras de sincronização se aplicam ao nível da partição, portanto, é particularmente importante considerar seu modelo de dados e padrões de acesso. Para ver mais informações sobre chaves de partição e como escolher uma, consulte Partições.
Observação
A chave da partição pode ser obrigatória ou opcional. Se o campo da chave da partição for opcional, todos os documentos do MongoDB que excluam a chave da partição ou tenham um valor nulo para a chave da partição serão enviados para a partição nula. Se o campo da chave da partição for obrigatório, o Device Sync ignorará todos os documentos do MongoDB que não tenham um valor válido para a chave da partição. Recomendamos uma chave da partição obrigatória, a menos que você queira sincronizar dados pré-existentes com valores de partição inválidos ou ausentes de uma coleção do MongoDB .
Depois de decidir qual campo usar, atualize sync.partition com o nome do campo da chave da partição no campo key e o tipo de chave da partição no campo type , semelhante a:
{ ... "partition": { "key": "owner_id", "type": "string", "permissions": { "read": {}, "write": {} } } ... }
Definir permissões de leitura e escrita
O App Services permite definir expressões JSON que avalia dinamicamente sempre que um usuário abre um Realm para determinar se o usuário tem permissões de leitura ou gravação para dados na partição.
As expressões de regra de sincronização têm acesso a %%user, que é resolvida para o usuário que abriu o Realm, e %%partition, que resolve para o valor da chave da partição do Realm. Você também pode usar operadores, incluindo %function, para lidar com casos mais complexos. Para obter exemplos, consulte Permissões de sincronização.
Depois de determinar como decidir as permissões de leitura e escrita de um usuário para uma determinada partição, defina as expressões JSON correspondentes nos campos read e write do partition.permissions, semelhantes a:
{ ... "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { "$or": [ { "%%user.id": "%%partition" }, { "%%user.custom_data.shared": "%%partition" } ] }, "write": { "%%user.id": "%%partition" } } } ... }
Especificar valores para otimização de sincronização
A Sincronização fornece recursos que permitem otimizar o desempenho da sincronização e melhorar o processo de recuperação de dados no cliente. Esses recursos são representados por configurações adicionais:
client_max_offline_daysis_recovery_mode_disabled
Você pode definir um valor numérico para client_max_offline_days. Quando você ativa a sincronização por meio da interface do usuário do App Services, o valor padrão é 30, que representa 30 dias.
Para obter mais informações, consulte: Tempo máximo offline do cliente.
O Modo de Recuperação permite que a Sincronização tente recuperar dados que ainda não foram sincronizados quando ocorre uma reinício do cliente . Quando você ativa a sincronização por meio da interface do usuário do App Services, o modo de recuperação é ativado por padrão. Recomendamos ativar o Modo de recuperação para o tratamento automático de reinício do cliente . Se você desativou o modo de recuperação e deseja reativá-lo, defina is_recovery_mode_disabled como false.
Para obter mais informações, consulte: Recuperar alterações não sincronizadas.
{ "type": "partition", "state": "enabled", "development_mode_enabled": true, "service_name": "mongodb-atlas", "database_name": "my-test-database", "partition": { ... }, "client_max_offline_days": 30, "is_recovery_mode_disabled": false }
Implemente a configuração de sincronização
Agora que você definiu a configuração de sincronização, incluindo as permissões de leitura e escrita, você pode distribuir suas alterações para começar a sincronizar dados e aplicar regras de sincronização.
Para implementar suas alterações, importe a configuração do aplicativo para o App Services App:
appservices push --remote="<Your App ID>"
Selecione um cluster para sincronizar
Você pode habilitar a sincronização para um único cluster vinculado em seu aplicativo.
Você precisará do arquivo de configuração de serviço do cluster para configurar a sincronização. Você pode encontrar o arquivo de configuração listando todos os serviços por meio da API de administrador:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
Identifique o serviço cuja configuração você precisa atualizar para habilitar a sincronização. Se você aceitou os nomes padrão ao configurar seu aplicativo, este deverá ser um serviço cujo name seja mongodb-atlas e type seja mongodb-atlas. Você precisa _id deste serviço.
Agora você pode obter o arquivo de configuração para este serviço:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services/{MongoDB_Service_ID}/config \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
Após obter a configuração, adicione o objeto sync com a seguinte configuração de modelo:
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
Escolher uma chave de partição
A chave de partição de sincronização é um campo em cada documento sincronizado que mapeia cada documento para um realm do lado do cliente. As regras de sincronização se aplicam ao nível da partição, portanto, é particularmente importante considerar seu modelo de dados e padrões de acesso. Para ver mais informações sobre chaves de partição e como escolher uma, consulte Partições.
Você pode obter uma lista de todas as chaves de partição válidas e seus tipos correspondentes por meio da API de administrador:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/sync/data?service_id=<MongoDB Service ID> \ -X GET \ -h 'Authorization: Bearer <Valid Access Token>'
Observação
A chave da partição pode ser obrigatória ou opcional. Se o campo da chave da partição for opcional, todos os documentos do MongoDB que excluam a chave da partição ou tenham um valor nulo para a chave da partição serão enviados para a partição nula. Se o campo da chave da partição for obrigatório, o Device Sync ignorará todos os documentos do MongoDB que não tenham um valor válido para a chave da partição. Recomendamos uma chave da partição obrigatória, a menos que você queira sincronizar dados pré-existentes com valores de partição inválidos ou ausentes de uma coleção do MongoDB .
Depois de decidir qual campo usar, atualize sync.partition com o nome do campo da chave da partição no campo key e o tipo de chave da partição no campo type .
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
Definir permissões de leitura e escrita
O App Services permite definir expressões JSON que avalia dinamicamente sempre que um usuário abre um Realm para determinar se o usuário tem permissões de leitura ou gravação para dados na partição.
As expressões de regra de sincronização têm acesso a %%user, que é resolvida para o usuário que abriu o Realm, e %%partition, que resolve para o valor da chave da partição do Realm. Você também pode usar operadores, incluindo %function, para lidar com casos mais complexos. Para obter exemplos, consulte Permissões de sincronização.
Após determinar como decidir as permissões de leitura e escrita de um usuário para uma determinada partição, defina as expressões JSON correspondentes nos campos read e write do sync.partition.permissions.
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": <Boolean>, "database_name": "<Database Name>", "partition": { "key": "owner_id", "type": "string", "permissions": { "read": { "$or": [ { "%%user.id": "%%partition" }, { "%%user.custom_data.shared": "%%partition" } ] }, "write": { "%%user.id": "%%partition" } } }, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> } ... }
Especificar valores para otimização de sincronização
A Sincronização fornece recursos que permitem otimizar o desempenho da sincronização e melhorar o processo de recuperação de dados do cliente . Esses recursos são representados por configurações adicionais:
client_max_offline_daysis_recovery_mode_disabled
Você pode definir um valor numérico para client_max_offline_days. Quando você ativa a sincronização por meio da interface do usuário do App Services, o valor padrão é 30, que representa 30 dias.
Para obter mais informações, consulte: Tempo máximo offline do cliente.
O Modo de Recuperação permite que a Sincronização tente recuperar dados não sincronizados quando ocorre uma reinício do cliente . Quando você ativa a sincronização por meio da interface do usuário do App Services, o modo de recuperação é ativado por padrão. Recomendamos ativar o Modo de recuperação para o tratamento automático de reinício do cliente . Para ativar o Modo de Recuperação, defina is_recovery_mode_disabled como false.
Para obter mais informações, consulte: Recuperar alterações não sincronizadas.
{ ... "sync": { "type": "partition", "state": "enabled", "development_mode_enabled": true, "database_name": "my-test-database", "partition": { ... }, "client_max_offline_days": 30, "is_recovery_mode_disabled": false } ... }
Implemente a configuração de sincronização
Agora que você definiu a configuração de sincronização, incluindo as permissões de leitura e escrita, você pode distribuir suas alterações para começar a sincronizar dados e aplicar regras de sincronização.
Para implementar suas alterações, envie uma solicitação de API de administração que atualize a configuração do cluster com sua configuração de sincronização:
curl https://services.cloud.mongodb.com/api/admin/v3.0/groups/{GROUP_ID}/apps/{APP_ID}/services/{MongoDB_Service_ID}/config \ -X PATCH \ -h 'Authorization: Bearer <Valid Access Token>' \ -d @/sync/config.json
Regras e permissões baseadas em partição
Sempre que um usuário abre um domínio sincronizado a partir de um aplicativo cliente, o App Services avalia as regras do seu aplicativo e determina se o usuário tem permissões de leitura e gravação para a partição. Os usuários devem ter permissão de leitura para sincronizar e ler dados em um domínio e devem ter permissão de gravação para criar, modificar ou excluir objetos. A permissão de gravação implica em permissão de leitura, portanto, se um usuário tiver permissão de gravação, também terá permissão de leitura.
Comportamento da Sincronização baseada em partição
As regras de sincronização aplicam-se a partições específicas e são acopladas ao modelo de dados da sua aplicação pela chave de partição. Considere o seguinte comportamento ao projetar seus esquemas para garantir que você tenha granularidade de acesso aos dados apropriada e não vaze informações confidenciais acidentalmente.
As regras de sincronização se aplicam dinamicamente com base no usuário. Um usuário pode ter acesso total de leitura e escrita a uma partição, enquanto outro usuário tem apenas permissões de leitura ou não consegue acessar totalmente a partição. Você controla essas permissões definindo expressões JSON.
As regras de sincronização se aplicam igualmente a todos os objetos em uma partição. Se um usuário tiver permissão de leitura ou gravação para uma determinada partição, ele poderá ler ou modificar todos os campos sincronizados de qualquer objeto na partição.
As permissões de gravação exigem permissões de leitura, portanto, um usuário com acesso de gravação a uma partição também tem acesso de leitura, independentemente das regras de permissão de leitura definidas.
Permissões de sincronização baseadas em partições
O App Services impõe permissões de leitura e gravação dinâmicas e específicas do usuário para proteger os dados em cada partição. Você define permissões com expressões de regra JSON que controlam se um determinado usuário leu ou gravou acesso aos dados em uma determinada partição. Os Serviços de apps avaliam as permissões de um usuário sempre que abrem um domínio sincronizado.
Dica
Suas expressões de regra podem utilizar expansões JSON como %%partition e %%user para determinar dinamicamente as permissões de um usuário com base no contexto de sua solicitação.
Conceitos chave
Permissões de leitura
Um usuário com permissões de leitura para uma determinada partição pode visualizar todos os campos de qualquer objeto no domínio sincronizado correspondente. As permissões de leitura não permitem que um usuário modifique os dados.
Permissões de Escrita
Um usuário com permissões de escrita para uma determinada partição pode modificar o valor de qualquer campo de qualquer objeto no domínio sincronizado correspondente. As permissões de gravação exigem permissões de leitura, portanto, qualquer usuário que possa modificar dados também pode visualizá-los antes e depois de serem modificados.
Estratégias de permissão
Importante
Os relacionamentos não podem abranger partições
Em um aplicativo que usa sincronização baseada em partições, um objeto só pode ter um relacionamento com outros objetos na mesma partição. Os objetos podem existir em bancos de dados e coleções diferentes (dentro do mesmo cluster), desde que o valor da chave de partição corresponda.
Você pode estruturar suas expressões de permissão de leitura e gravação como um conjunto de estratégias de permissão que se aplicam à sua estratégia de partição. As estratégias a seguir descrevem abordagens comuns que você pode adotar para definir permissões de leitura, gravação e sincronização para seu aplicativo.
Permissões globais
Você pode definir permissões globais que se aplicam a todos os usuários para todas as partições. Essa é, em essência, uma opção para não implementar permissões específicas do usuário em favor de permissões universais de leitura ou gravação que se aplicam a todos os usuários.
Para definir uma permissão global de leitura ou escrita, especifique um valor booleano ou uma expressão JSON que sempre avalia para o mesmo valor booleano.
Exemplo | Descrição | |
|---|---|---|
| A expressão true significa que todos os usuários têm as permissões de acesso fornecidas para todas as partições. | |
| A expressão false significa que nenhum usuário tem as permissões de acesso fornecidas para quaisquer partições. | |
| Esta expressão sempre é avaliada como true, então é efetivamente o mesmo que especificar diretamente true. |
Permissões para partes específicas
Você pode definir permissões que se aplicam a uma partição específica ou a grupos de partições especificando explicitamente seus valores de partição.
Exemplo | Descrição | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Esta expressão significa que todos os usuários têm permissões de acesso para dados com um valor de partição de "Public". | |||||||||
| Esta expressão significa que todos os usuários têm permissões de acesso
fornecidas para dados com qualquer um dos valores de partição especificados. |
Permissões para usuários específicos
Você pode definir permissões que se aplicam a um usuário específico ou a um grupo de usuários especificando explicitamente seus valores de ID.
Exemplo | Descrição | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Esta expressão significa que o usuário com id "5f4863e4d49bd2191ff1e623" tem as permissões de acesso fornecidas para dados em qualquer partição. | |||||||||
| Esta expressão significa que qualquer usuário com um dos valores de ID de usuários
especificados possui as permissões de acesso para dados em qualquer partição. |
Permissões baseadas em dados do usuário
Você pode definir permissões que se aplicam aos usuários com base em dados específicos definidos em seu documento de dados de usuário personalizados, campos de metadados ou outros dados de um provedor de autenticação.
Exemplo | Descrição | |
|---|---|---|
| Esta expressão significa que um usuário leu o acesso a uma partição se o valor da partição estiver listado no campo readPartitions de seus dados de usuário personalizados. | |
| Essa expressão significa que um usuário tem acesso de gravação a uma partição se o valor da partição estiver listado no campo data.writePartitions de seu objeto de usuário. |
Regras de função
Você pode definir permissões dinâmicas complexas avaliando uma função que retorna um valor booleano. Isso é útil para esquemas de permissão que exigem que você acesse sistemas externos ou outra lógica personalizada que você não pode expressar somente em expressões JSON.
Exemplo | Descrição | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Essa expressão chama a função canReadPartition e passa no valor da partição como primeiro e único argumento. A função procura as permissões do usuário para a partição de uma collection do MongoDB e, em seguida, retorna um booleano que indica se o usuário pode ler dados na partição solicitada. |
Migrar regras de sincronização baseada em partição para as regras do App Services
Se você migrar seu aplicativo de Partition-Based Sync para o Flexible Sync, suas regras de acesso a dados também precisarão ser migradas.
Algumas estratégias de Sincronização baseada em partição não podem ser convertidas diretamente em regras do App Services. Talvez seja necessário migrar manualmente as permissões que incluem:
%functionoperador.Regras de função não são compatíveis com a Flexible Sync e não podem ser migradas.
%%partitionexpansão.As regras de App Services não têm uma expansão equivalente para
%%partition, portanto, não podem ser migradas.%or,%not,%nor,%andexpansões.Essas permissões podem funcionar, mas há nuances suficientes para que você as teste para garantir o comportamento esperado. Testar novas permissões não funcionará no aplicativo que você está migrando. Você precisará de um novo aplicativo para testar as permissões migradas manualmente.
Consulte a lista de expansões compatíveis com Sincronização flexível para todas as expansões suportadas.
Você também deve verificar o Guia de permissões do Device Sync para obter mais informações sobre como trabalhar com permissões.
Estratégias de partição
Uma estratégia de partição é um padrão chave/valor para dividir objetos em partições. Casos de uso diferentes exigem diferentes estratégias de partição. Você pode compor estratégias de partição no mesmo aplicativo para formar uma estratégia maior. Isso permite lidar com casos de uso arbitrariamente complexos.
Qual estratégia usar depende do modelo de dados e padrões de acesso do seu aplicativo. Considere um aplicativo com dados públicos e privados. Você pode colocar alguns dados, como anúncios, em uma partição pública. Você pode restringir outros dados, como informações pessoais, a usuários privilegiados.
Ao desenvolver uma estratégia de partição, considere:
Segurança de dados: os usuários podem precisar de diferentes permissões de acesso de leitura e gravação a subconjuntos de dados. Considere as permissões que os usuários precisam para os tipos de documento. Um usuário tem as mesmas permissões para todos os documentos em uma partição.
Capacidade de armazenamento: Seus aplicativos clientes podem ter armazenamento limitado no dispositivo em alguns dispositivos e plataformas. Uma estratégia de partição deve levar em conta as limitações de armazenamento. Certifique-se de que o usuário possa armazenar seus dados sincronizados em seu dispositivo.
Dica
Combinar estratégias
Você pode usar um nome de chave de partição como _partition com uma string de query como valor. Isso permite que você use várias estratégias no mesmo aplicativo. Por exemplo:
_partitionKey: "user_id=abcdefg" _partitionKey: "team_id=1234&city='New York, NY'"
Você pode usar funções e expressões de regras para analisar a string. A sincronização pode determinar se um usuário tem acesso a uma partição com base na estratégia combinada.
Estratégia de firehose
Uma estratégia de partição firehose agrupa todos os documentos em uma única partição. Com essa estrutura, todos os usuários sincronizam todos os dados do seu aplicativo em seus dispositivos. Essa abordagem é funcionalmente uma decisão de não fazer a partição de dados. Isso funciona para aplicativos básicos ou pequenos conjuntos de dados públicos.
Segurança de dados. Todos os dados são públicos para clientes com um domínio que usa a partição. Se um usuário tiver acesso de leitura ou escrita à partição, ele poderá ler ou escrever qualquer documento.
Capacidade de armazenamento. Cada usuário sincroniza todos os documentos na partição. Todos os dados devem estar dentro da sua limitação de armazenamento mais restritiva. Use essa estratégia somente quando os conjuntos de dados forem pequenos e não aumentarem rapidamente.
Uma maneira de criar uma firehose é definir a chave de partição como um campo opcional. Não inclua um valor para este campo em nenhum documento. O App Services mapeia qualquer documento que não inclua um valor de partição para a partição nula.
Você também pode definir um valor de partição estática. Isso ocorre quando o valor da partição não muda com base no usuário ou nos dados. Por exemplo, regiões em todos os clientes poderiam usar o valor de partição "MyPartitionValue".
Exemplo
Uma aplicação permite que os usuários naveguem por pontuações e estatísticas
de jogos locais de beisebol do ensino médio. Considere os seguintes documentos nas collections
games e teams:
collection games: [ { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } ] collection teams: [ { name: "Brook Ridge Miners" } { name: "Southside Rockets" } { name: "Uptown Bombers" } ]
O número total de jogos é pequeno. Um pequeno número de equipes locais joga apenas alguns jogos por ano. A maioria dos dispositivos pode baixar todos os dados do jogo para facilitar o acesso offline. Neste caso, a estratégia de firehose é apropriada. Os dados são públicos e os documentos não precisam de uma chave de partição.
A estratégia mapeia as coleções para os seguintes domínios:
realm null: [ Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Team { name: "Brook Ridge Miners" } Team { name: "Southside Rockets" } Team { name: "Uptown Bombers" } ]
Estratégia de usuário
Uma estratégia de partição de usuário agrupa documentos privados para cada usuário. Esses documentos vão para uma partição específica desse usuário. Isso funciona quando cada documento tem um proprietário e ninguém mais precisa dos dados. Um nome de usuário ou ID que identifica o proprietário cria uma chave de partição natural.
Segurança de dados. Os dados em uma partição de usuário são específicos para um determinado usuário. Podem conter informações privadas do usuário. Cada usuário sincroniza apenas sua própria partição. Outros usuários não podem acessar documentos na partição.
Capacidade de armazenamento. Cada usuário sincroniza apenas dados de sua própria partição. Seus dados devem atender às restrições de armazenamento do dispositivo. Use esta estratégia somente quando cada usuário tiver uma quantidade gerenciável de dados.
Exemplo
Um aplicativo de streaming de música armazena dados sobre playlists e classificações de músicas para cada
usuário. Considere os seguintes documentos nas coleções playlists e ratings:
collection playlists: [ { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ] collection ratings: [ { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ]
Todo documento inclui o campo owner_id. Esta é uma boa chave de partição para uma estratégia de partição de usuário. Naturalmente, ele mapeia documentos para usuários individuais. Isso limita os dados de cada dispositivo a playlists e classificações para o usuário do dispositivo.
Os usuários têm acesso de leitura e gravação ao seu domínio de usuário. Contém listas de reprodução que eles criaram e classificações que deram às músicas.
Todo usuário tem acesso de leitura ao realm para o valor de partição
PUBLIC. Ele contém playlists que estão disponíveis para todos os usuários.
A estratégia mapeia as coleções para os seguintes domínios:
realm dog_enthusiast_95: [ Playlist { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Playlist { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Rating { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } Rating { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ] realm cat_enthusiast_92: [ Playlist { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } Rating { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } ] realm PUBLIC: [ Playlist { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } Playlist { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ]
Estratégia de equipe
Uma estratégia de partição de equipe agrupa documentos privados compartilhados por uma equipe de usuários. Uma equipe pode incluir funcionários de uma loja ou membros de uma banda. Cada equipe tem uma partição específica para esse grupo. Todos os usuários da equipe compartilham acesso e propriedade dos documentos da equipe.
Segurança de dados. Os dados em uma partição de equipe são específicos da equipe. Eles podem conter dados restritos à equipe, mas não a um membro dela. Cada usuário sincroniza partições com as equipes às quais pertence. Os usuários que não pertencem a uma equipe não podem acessar documentos na partição dela.
Capacidade de armazenamento: cada usuário só sincroniza dados de suas próprias equipes. Os dados das equipes de um usuário devem se ajustar às restrições de armazenamento do dispositivo. Use essa estratégia quando os usuários pertencerem a um número gerenciável de equipes. Se os usuários pertencem a muitas equipes, os realms combinados podem conter muitos dados. Talvez seja necessário limitar o número de partições da equipe sincronizadas por vez.
Exemplo
Um aplicativo permite que os usuários criem projetos para colaborar com outros usuários. Considere os seguintes documentos nas coleções projects e tasks:
collection projects: [ { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } { name: "API", owner_id: "api-team", task_ids: [ ... ] } ] collection tasks: [ { status: "complete", owner_id: "api-team", text: "Import dependencies" } { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } { status: "todo", owner_id: "api-team", text: "Write tests" } { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ]
Todo documento inclui o campo owner_id. Esta é uma boa chave
de partição para uma estratégia de partição de equipe. Naturalmente, ele mapeia documentos para
equipes individuais. Isso limita os dados em cada dispositivo. Os usuários têm apenas
projetos e tarefas relevantes para eles.
Os usuários têm acesso de leitura e escrita a partições de propriedade de equipes onde são membros.
Os dados armazenados em uma coleção do
teamsouuserspodem mapear os usuários para membros da equipe:collection teams: [ { name: "cli-team", member_ids: [ ... ] } { name: "api-team", member_ids: [ ... ] } ] collection users: [ { name: "Joe", team_ids: [ ... ] } { name: "Liz", team_ids: [ ... ] } { name: "Matt", team_ids: [ ... ] } { name: "Emmy", team_ids: [ ... ] } { name: "Scott", team_ids: [ ... ] } ]
A estratégia mapeia as coleções para os seguintes domínios:
realm cli-team: [ Project { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } Task { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } Task { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ] realm api-team: [ Project { name: "API", owner_id: "api-team", task_ids: [ ... ] } Task { status: "complete", owner_id: "api-team", text: "Import dependencies" } Task { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } Task { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } Task { status: "todo", owner_id: "api-team", text: "Write tests" } ]
Estratégia de canal
Uma estratégia de partição de canal agrupa documentos de um tópico ou domínio comum. Cada tópico ou domínio tem sua própria partição. Os usuários podem optar por acessar ou assinar canais específicos. Um nome ou ID pode identificar esses canais em uma lista pública.
Segurança de dados. Os dados em uma partição de canal são específicos de um tópico ou área. Os usuários podem optar por acessar esses canais. Você pode limitar o acesso de um usuário a um subconjunto de canais. Você pode impedir que os usuários acessem os canais completamente. Quando o usuário tem permissão de leitura ou escrita para um canal, ele pode acessar qualquer documento na partição.
Capacidade de armazenamento. Os usuários podem optar por sincronizar dados de qualquer canal permitido. Todos os dados dos canais de um usuário devem se ajustar às restrições de armazenamento do dispositivo. Use essa estratégia para dividir conjuntos de dados públicos ou semiprivados. Essa estratégia divide conjuntos de dados que não se encaixam nas restrições de armazenamento.
Exemplo
Um aplicativo permite que os usuários criem salas de chat com base em tópicos. Os usuários podem pesquisar e ingressar em canais de qualquer tópico de seu interesse. Considere estes documentos nas coleções chatrooms e messages:
collection chatrooms: [ { topic: "cats", description: "A place to talk about cats" } { topic: "sports", description: "We like sports and we don't care who knows" } ] collection messages: [ { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
Todo documento inclui o campo topic. Esta é uma boa chave de partição para uma estratégia de partição de canal. Naturalmente, ele mapeia documentos para canais individuais. Isso reduz os dados em cada dispositivo. Os dados contêm apenas mensagens e metadados para os canais escolhidos pelo utilizador.
Os usuários têm acesso de leitura e escrita a salas de bate-papo onde estão inscritos. Os usuários podem alterar ou excluir qualquer mensagem - mesmo as enviadas por outros usuários. Para limitar as permissões de escrita, você pode conceder aos usuários acesso somente leitura. Em seguida, manipule o envio de mensagens com uma função sem servidor.
Armazene os canais inscritos do usuário na coleção
chatroomsouusers:collection chatrooms: [ { topic: "cats", subscriber_ids: [ ... ] } { topic: "sports", subscriber_ids: [ ... ] } ] collection users: [ { name: "Joe", chatroom_ids: [ ... ] } { name: "Liz", chatroom_ids: [ ... ] } { name: "Matt", chatroom_ids: [ ... ] } { name: "Emmy", chatroom_ids: [ ... ] } { name: "Scott", chatroom_ids: [ ... ] } ]
A estratégia mapeia as coleções para os seguintes domínios:
realm cats: [ Chatroom { topic: "cats", description: "A place to talk about cats" } Message { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } Message { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } ] realm sports: [ Chatroom { topic: "sports", description: "We like sports and we don't care who knows" } Message { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } Message { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } Message { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
Estratégia de região
Uma estratégia de partição de região agrupa documentos relacionados a um local ou região. Cada partição contém documentos específicos para essas áreas.
Segurança de dados. Os dados são específicos para uma determinada área geográfica. Você pode limitar o acesso de um usuário à região atual. Como alternativa, conceda acesso aos dados região por região.
Capacidade de armazenamento. As necessidades de armazenamento variam dependendo do tamanho e dos padrões de uso da região. Os usuários só podem sincronizar dados em sua própria região. Os dados de qualquer região devem caber nas restrições de armazenamento de um dispositivo. Se os usuários sincronizarem várias regiões, partição em subregiões menores. Isso ajuda a evitar a sincronização de dados desnecessários.
Exemplo
Um aplicativo permite que os usuários pesquisem restaurantes próximos e façam pedidos a partir de seus menus. Considere os seguintes documentos na coleção restaurants:
collection restaurants: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
Todo documento inclui o campo city. Esta é uma boa chave de partição para uma estratégia de partição de região. Naturalmente, mapeia documentos para áreas físicas específicas. Isso limita os dados a mensagens e metadados para a cidade atual de um usuário. Os usuários têm acesso de leitura aos restaurantes em sua região atual. Você pode determinar a região do usuário em sua lógica de aplicativo.
A estratégia mapeia as coleções para os seguintes domínios:
realm New York, NY: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } ] realm Chicago, IL: [ { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
Estratégia de bucket
Uma estratégia de partição de bucket agrupa documentos por intervalo. Quando os documentos variam ao longo de uma dimensão, uma partição contém um subintervalo. Considere intervalos de blocos baseados em tempo. Os gatilhos movem documentos para novas partições quando eles estão fora do intervalo de armazenamento.
Segurança de dados. Limite os usuários a ler ou gravar somente intervalos específicos. Os dados podem fluir entre blocos. Considere acessar permissões para um documento em todos os possíveis blocos.
Capacidade de armazenamento. As necessidades de armazenamento variam de acordo com o tamanho e os padrões de uso de cada bucket. Considere quais blocos os usuários precisam acessar. Limite o tamanho dos compartimentos para que se ajustem às restrições de armazenamento de um dispositivo. Se os usuários sincronizarem muitos compartimentos, divida-os em compartimentos menores. Isso ajuda a evitar a sincronização de dados desnecessários.
Exemplo
Uma aplicação de IoT mostra visualizações em tempo real de leituras de sensores várias vezes por segundo. Os buckets derivam do número de segundos desde a entrada da leitura. Considere estes documentos na collection readings:
collection readings: [ { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
Todo documento inclui o campo bucket. Este campo mapeia documentos para intervalos de tempo específicos. O dispositivo de um usuário contém apenas leituras de sensores para a janela que ele visualiza.
Os usuários têm acesso de leitura às leituras do sensor para qualquer bucket de tempo.
Os sensores usam aplicativos clientes com acesso de gravação para fazer upload de leituras.
A estratégia mapeia as coleções para os seguintes domínios:
realm 0s<t<=60s: [ Reading { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } ] realm 60s<t<=300s: [ Reading { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } Reading { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
Ingestão de dados
A ingestão de dados é uma funcionalidade da Sincronização flexível e não pode ser habilitada em aplicativos que usam a Sincronização baseada em partição.
Configuração de sincronização baseada em partição
Quando você usa a Sincronização Baseada em Partição, seu aplicativo Atlas App Services usa esta configuração de Sincronização:
{ "type": "partition", "state": <"enabled" | "disabled">, "development_mode_enabled": <Boolean>, "service_name": "<Data Source Name>", "database_name": "<Development Mode Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "last_disabled": <Number>, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> }
Campo | Descrição |
|---|---|
typeString | O modo de sincronização. Há dois modos de sincronização: a sincronização flexível e a antiga sincronização baseada em partição. Opções válidas para uma Sincronização baseada em partição:
|
stateString | O estado atual do protocolo de sincronização do aplicativo. Opções válidas:
|
service_nameString | O nome da fonte de dados do MongoDB a ser sincronizada. Não é possível usar a sincronização com uma instância sem servidor ou instância de banco de dados federado. |
development_mode_enabledBoolean | Se true, o modo de desenvolvimento estiver ativado para o aplicativo. Quando habilitado, o App Services armazena automaticamente objetos sincronizados em um banco de dados específico (especificado em database_name) e espelha os tipos de objetos nos esquemas de coleção desse banco de dados. |
database_nameString | O nome de um banco de dados no cluster sincronizado em que o App Services armazena dados no Modo de Desenvolvimento. O App Services gera automaticamente um esquema para cada tipo sincronizado e mapeia cada tipo de objeto para uma coleção na base de dados. |
partition.keyString | O nome do campo da chave de partição do seu aplicativo. Este campo deve ser definido no esquema para tipos de objeto que você deseja sincronizar. |
partition.typeString | O tipo de valor do campo chave de partição. Deve corresponder ao tipo definido no esquema de objeto. Opções válidas:
|
partition.permissions.readExpression | Uma expressão que avalia para true quando um usuário tem permissão para ler objetos em uma partição. Se a expressão for avaliada como false, o App Services não permitirá ao usuário ler um objeto ou suas propriedades. |
partition.permissions.writeExpression | Uma expressão que é avaliada como true quando um usuário tem permissão para gravar objetos em uma partição. Se a expressão for avaliada como false, o App Services não permitirá ao usuário modificar um objeto ou suas propriedades. A permissão de escrita requer permissão de leitura. Um usuário não pode escrever em um documento que não pode ler. |
last_disabledNumber | A data e a hora em que a sincronização foi pausada ou desativada pela última vez, representada pelo número de segundos desde a época Unix (1 de janeiro de 1970, 00:00:00 UTC). |
client_max_offline_daysNumber | Controla quanto tempo o processo de compactação de back-end aguarda antes de podar agressivamente os metadados que alguns clientes exigem para sincronizar a partir de uma versão antiga de um realm. |
is_recovery_mode_disabledBoolean | Se false, o Modo de Recuperação está habilitado para o aplicativo. Enquanto habilitados, os SDKs de Realm que oferecem suporte a esse recurso tentam recuperar alterações não sincronizadas ao executar uma redefinição de cliente. O modo de recuperação está habilitado por padrão. |
Altere sua configuração de sincronização baseada em partição
Você deve Encerrar a Sincronização de Dispositivos e Reativar a Sincronização de Dispositivos para fazer alterações na Configuração de Sincronização de Dispositivos Baseada em Partição. Enquanto estiver reativando o Atlas Device Sync, você poderá especificar uma nova Chave de Partição ou alterações em suas Permissões de Leitura/Gravação. Fazer alterações na configuração da sincronização de dispositivos ao encerrar e reativar a sincronização de dispositivos acionará uma redefinição do cliente. Para saber mais sobre como lidar com as redefinições do cliente, leia a documentação de redefinição do cliente.
Erros de Sincronização baseada em partição
Os erros a seguir podem ocorrer quando sua aplicação usa a sincronização baseada em partição.
Nome do erro | Descrição |
|---|---|
ErroIllegalRealmPath | Esse erro indica que o cliente tentou abrir um realm com um valor de partição do tipo errado. Por exemplo, você pode ver a mensagem de erro "tentativa de vincular em partição de realm ilegal: esperava-se que a partição tivesse o tipo objectId, mas encontrou string". Para se recuperar desse erro, certifique-se de que o tipo de valor de partição usado para abrir o realm corresponda ao tipo de chave de partição na configuração do Device Sync. |
Compactação de backend
O Atlas Device Sync usa espaço no Atlas cluster sincronizado do seu aplicativo para armazenar metadados para sincronização. Isso inclui um histórico de alterações em cada área. O Atlas App Services minimiza esta utilização de espaço no seu Atlas cluster. A minimização de metadados é necessária para reduzir o tempo e os dados necessários para sincronização.
Os aplicativos que usam a Sincronização Baseada em Partição executam compactação de back-end para reduzir a quantidade de metadados armazenados em um Cluster Atlas. A compactação de backend é um processo de manutenção que é executado automaticamente para todos os aplicativos que usam a Sincronização Baseada em Partição. Usando a compactação, o backend otimiza o histórico de um domínio removendo metadados desnecessários do conjunto de alterações. O processo remove qualquer instrução cujo efeito seja posteriormente substituído por uma instrução mais recente.
Exemplo
Considere o seguinte histórico de realm:
CREATE table1.object1 UPDATE table1.object1.x = 4 UPDATE table1.object1.x = 10 UPDATE table1.object1.x = 42
O histórico a seguir também convergiria para o mesmo estado, mas sem mudanças provisórias desnecessárias:
CREATE table1.object1 UPDATE table1.object1.x = 42
Observação
A Sincronização baseada em partição usa compactação de backend para reduzir o histórico do Device Sync armazenado no Atlas. A Flexible Sync consegue isso com a redução e o máximo de tempo offline do cliente .