Types of database models
One of the fundamental aspects of database architecture is how the data is organized, stored, accessed, and retrieved within a database system.
Broadly, we split the types of database architecture models into two categories:
- Logical: Logical architecture focuses on the abstract representation of data and emphasizes the structure and relationships between the data—for example, a document model, hierarchical model, and object-oriented model.
- Physical: The physical architecture defines how the system is deployed or scaled physically across the infrastructure.
In this section, let’s understand the physical or tier architecture, along with some more modern DBMS architecture models.
The most basic architecture is the client server architecture, which includes one-tier, two-tier, and three-tier architecture. In a client server architecture, there is a client (end user or application) that requests services from the server (backend or database). The server in turn processes the request and returns the appropriate response.
One-tier architecture
In the one-tier architecture, the database, user interface, and application logic all reside on the same machine (local machine) or single server itself. It's typically used for small-scale applications where simplicity and cost-effectiveness are priorities. Because there are no network delays involved, this type of tier architecture is generally a fast way to access data.
Two-tier architecture
In a two-tier architecture, one or more clients connect directly with a database server—for example, a desktop application connecting to a single database hosted on an on-premises database server like an in-house customer relationship management (CRM) that connects to a Microsoft Access database.
Three-tier architecture/N-tier architecture
Most modern web applications use a three-tier architecture. In a three-tier architecture, the clients connect to a backend application server, which in turn connects to the database. The application is split into three or more layers—i.e., a presentation layer, business application layer, and data layer—creating a separation of responsibility. Using this approach ensures more security, scalability, and faster deployment.
Security: Keeping the database connection open to a single back end reduces the risks of being hacked.
Scalability: Because each layer operates independently, it is easier to scale parts of the application.
Faster deployment: Having multiple tiers makes it easier to have a separation of concerns and to follow cloud-native best practices, including better continuous delivery processes.
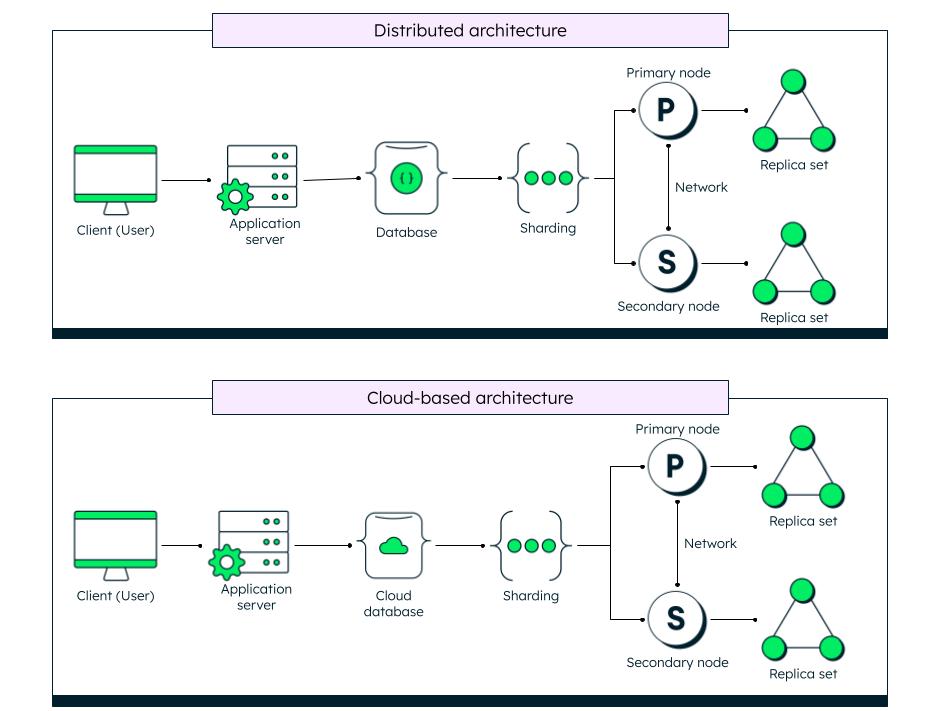
Distributed architecture
Much suited for modern applications, a distributed database architecture distributes the data across multiple nodes, through various methods like replication and sharding, to ensure high availability and fault tolerance.
Cloud-based architecture
Further enhancing the distributed architecture is the cloud-based architecture, where the database acts as a service provided over the cloud and offers more flexibility and scalability, and is cost effective. MongoDB Atlas is a good example of a cloud-based data platform.
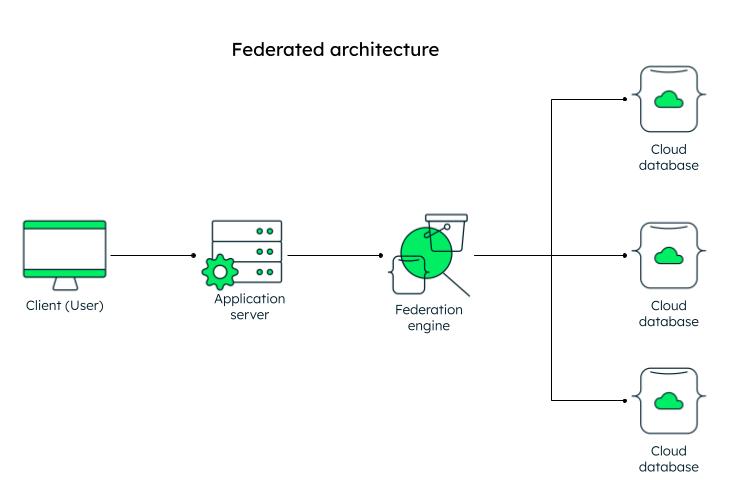
Federated architecture
In a federated architecture, multiple autonomous databases can be integrated into a single view, thus integrating data from multiple diverse sources into one database. MongoDB Atlas provides Data Federation, where you can access and query multiple Atlas databases and get the result into the desired platform.