Table of contents
- Approximate nearest neighbor search: the foundation in AI-powered search technology
- The evolution of search leading to ANN search
- The mechanics of approximate nearest neighbors search
- How ANN search works
- The role of approximate nearest neighbors in vector databases
- Applications leveraging ANN search
- The benefits of ANN search
- MongoDB Atlas Vector Search and ANN search queries
Approximate nearest neighbor search: the foundation in AI-powered search technology
Approximate nearest neighbor (ANN) search — or ANN search — is a type of nearest neighbor search and a technique used in vector databases to find data points closest to a given query point with a certain level of approximation.
Unlike traditional search methods, ANN search is tailored for efficiency, especially in handling high-dimensional data. It finds data points or vectors that share close proximity in distance to a specific query point or vector with a level of approximation that balances accuracy with computational feasibility.
ANN search is particularly valuable in AI and machine learning applications, where handling large and complex datasets is crucial.
For instance, in a music streaming service, ANN can recommend songs that closely match a user's preferences, even if not exactly the same. In medical imaging, it helps in quickly identifying similar diagnostic images, facilitating faster and more accurate diagnoses.
ANN search is a variant of the broader nearest neighbor search algorithms but is uniquely designed for scenarios where speed is as crucial as accuracy. This approach is particularly effective in high-dimensional spaces, which are common in modern AI applications. In such environments, traditional exact nearest neighbor searches can become computationally intensive and less feasible.
This combination of speed and accuracy makes ANN an essential tool in modern data-driven applications.
The evolution of search leading to ANN search
The history of search technology has its roots within the exploration of early information retrieval systems, but the proliferation of search in commercial use cases came about with the advent of the internet through early search engines like AltaVista and Yahoo, which primarily used basic algorithms to index and rank web pages based on keyword frequency. Keyword frequency was somewhat effective, but the algorithm suffers from issues such as keyword stuffing. As the internet evolved, so did search technology, with Google introducing more sophisticated algorithms focusing on page relevance and link analysis to determine the authority and quality of web pages.
As machine learning and artificial intelligence developed, they ushered in a new era of search technology. This included technologies like semantic search, which understands the context and meaning behind queries, and neural network-based approaches for more intuitive and accurate search results.
The mechanics of approximate nearest neighbors search
The concept of approximate nearest neighbor search is similar to K-nearest neighbors (KNN) but with a focus on efficiency and performance in high-dimensional spaces.
ANN search functionality and key concepts
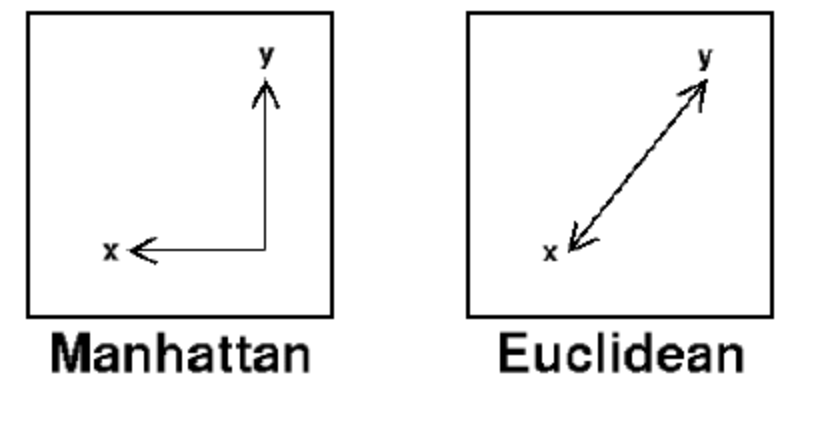
At the heart of ANN search is the principle of finding the closest points or most similar data points to a query point in a dataset. This is achieved using various distance measures, with the most common being Euclidean distance for numeric vectors. The key to ANN's efficiency lies in its use of algorithms such as locality sensitive hashing, which places similar items into the same bucket, thereby reducing search time significantly.
Unlike exhaustive search methods that evaluate every other point in the dataset, ANN employs a more efficient approach. This approach often involves graph-based methods, where data points are nodes in a graph, and the search for nearest neighbors becomes a path-finding problem within this graph. This method not only improves search speed but also ensures better user quality in the results.
One of the challenges in ANN search is avoiding local minimums, which can occur in greedy search algorithms. ANN algorithms are designed to mitigate this by exploring multiple paths or using techniques that go beyond the immediate closest points, ensuring a more comprehensive search result.
Source: improvedoutcomes.com
Incorporating advanced techniques in ANN search
ANN search has been influenced by various solutions and developments from organizations such as the Apache Software Foundation. These influences have led to numerous variants of the ANN algorithm, each tailored to specific types of data and search requirements. For example, in scenarios where the dataset is static, files containing precomputed nearest neighbors can significantly speed up the prediction phase.
The performance of an ANN algorithm depends strongly on the nature of the dataset and the specific requirements of the search task. In large datasets, especially, ANN algorithms efficiently find candidate points for a given query point, narrowing down the field of search and thereby improving speed and efficiency.
ANN identifies data points in a dataset that are “approximately” closest to a query point, utilizing different distance metrics such as Euclidean, Manhattan, or Hamming distances, depending on the nature of the data. This approximate approach allows ANN to quickly navigate through large and complex datasets, a task where exact nearest neighbor searches like KNN might be too computationally intensive.
ANN's performance hinges on the selection of appropriate distance metrics and the efficient representation of data points in a multidimensional feature space.
Techniques like dimensionality reduction and feature scaling are often employed to manage the high-dimensional nature of the data and to ensure balanced influence of different features.
For instance, principal component analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) are used to reduce the number of dimensions while preserving the essential characteristics of the data, mitigating issues of sparsity that can hinder search effectiveness.
ANN algorithms are particularly adept at handling real-world scenarios with large datasets where an exact match is not necessary, but a close approximation yields significant value. This makes them ideal for applications like image recognition, where an ANN can rapidly identify images with similar features from a vast dataset, enhancing the efficiency and practicality of searches in large-scale AI applications.
How ANN search works
ANN search operates on the principle of finding data points in a dataset that are "closest" or most similar to a query point. Unlike exact nearest neighbor searches, ANN focuses on speed and efficiency, accepting a small degree of approximation for significantly faster results. This approach is particularly effective in high-dimensional spaces, typical in modern AI applications, where exact matching is computationally intensive.
ANN works by mapping data into a high-dimensional space and quickly identifying points closest to a query point, using an approximation for speed.
A detailed example of ANN in action would be in image recognition systems. Here, ANN can analyze an image, convert it into a vector, and compare it to a database of image vectors. By calculating the distance between these vectors in multidimensional space, ANN efficiently identifies images with similar features or content, facilitating tasks like object recognition or categorizing images based on content similarity.
The role of approximate nearest neighbors in vector databases
When it comes to vector databases, ANN search is particularly significant due to its ability to handle high-dimensional data. Vector databases differ from traditional databases by representing data as vectors in a multidimensional space rather than in rows and columns. This structure is ideal for AI and machine learning applications where data points (vectors) encapsulate complex, multi-attribute information.
ANN algorithms come into play by rapidly identifying vectors that are most similar to a given query vector. They achieve this by calculating the “distance” between vectors in this multidimensional space. This proximity calculation allows for fast retrieval of similar items, making it highly efficient for tasks like image recognition, where each image is a point in this space, and the goal is to find the most visually similar images.
The upshot is that ANN's ability to efficiently navigate and search through this multidimensional vector space makes it a cornerstone technology in modern data-driven applications.

Source: Made with DALL-E.
Applications leveraging ANN search
ANN algorithms excel in handling real-world datasets where an exact match is not as critical as finding a close approximation. This characteristic makes them ideal for a variety of applications:
Image recognition
In computer vision use cases, ANN can rapidly identify images with similar features from a vast dataset. This capability is invaluable in applications such as object recognition or categorizing images based on content similarity.
Music streaming services
For instance, in a music streaming service, ANN can be used to recommend songs that align with a user's preferences, even if they are not an exact match.
Medical imaging
In healthcare, ANN assists in quickly identifying diagnostic images similar to a query, improving the speed and accuracy of patient diagnoses.
The benefits of ANN search
The effectiveness of approximate nearest neighbor search in vector databases is demonstrated by its handling of complex data structures and its adaptability to evolving data sizes. Advantages include:
Effectiveness with high-dimensional data
ANN excels in environments where data spans hundreds or even thousands of dimensions. This capability is crucial in fields like genomics or complex system simulations, where data points are inherently multidimensional and intricate.
Semantic and contextual data interpretation
Beyond just matching exact data points, ANN search delves into the capability of data, understanding and identifying similarities based on context and semantics. This aspect is particularly beneficial in areas like natural language processing or sentiment analysis, where the meaning and context of words or phrases are as important as the data itself.
Scalability for growing data
As datasets grow larger, ANN search maintains its performance, making it a reliable choice for industries and applications where data volume is rapidly expanding, such as social media analytics or real-time market trend analysis. This scalability ensures that as more data is added, the efficiency and speed of the search process are not compromised, facilitating timely and relevant data retrieval even in the vastest datasets. As the volume and scale of data grows, ANN makes a trade-off between accuracy and speed to maintain an efficient level of performance.
ANN's robustness, nuanced understanding, and scalability make it an indispensable tool in modern data-driven decision-making and AI development.
MongoDB Atlas Vector Search and ANN search queries
MongoDB Atlas Vector Search supports ANN queries to search for results and stores vector embeddings alongside original data, streamlining architecture and enhancing developer experience. By harnessing powerful ANN queries, MongoDB Atlas Vector Search facilitates complex searches, including semantic and cross-modal searches, offering a flexible and robust solution for modern AI-driven applications.
As we navigate the data-rich landscape of the digital age, ANN search in vector databases emerges as a key enabler. By offering efficient, scalable, and contextually rich search capabilities, it empowers developers to build advanced, intuitive applications. The future of search technology is not just about matching keywords but understanding the meaning and context of the data, a frontier where ANN search leads the way.
For an in-depth exploration of ANN search and its integration with MongoDB Atlas Vector Search, visit our vector databases page.