Vehicle manuals have become dense, multimodal knowledge bases: prose, diagrams, annotated photographs, safety notices, feature descriptions, and variant-specific instructions. For Mahindra & Mahindra, the challenge was not only to make that content searchable, but to make it useful inside the ownership journey.
VehicleGPT is the AI-powered assistant Mahindra ships inside its mobile app, answering natural-language questions about vehicle features, controls, warning symbols, and manual content. Various industries have explored owner-facing AI assistance over product manuals, but few automotive OEMs have rolled it out at the breadth Mahindra has pursued—across every passenger vehicle brand in the portfolio and the complete set of trim variants under each. Mahindra moved early on the idea that this kind of structured, manual-grounded help belongs inside the app the driver already uses.
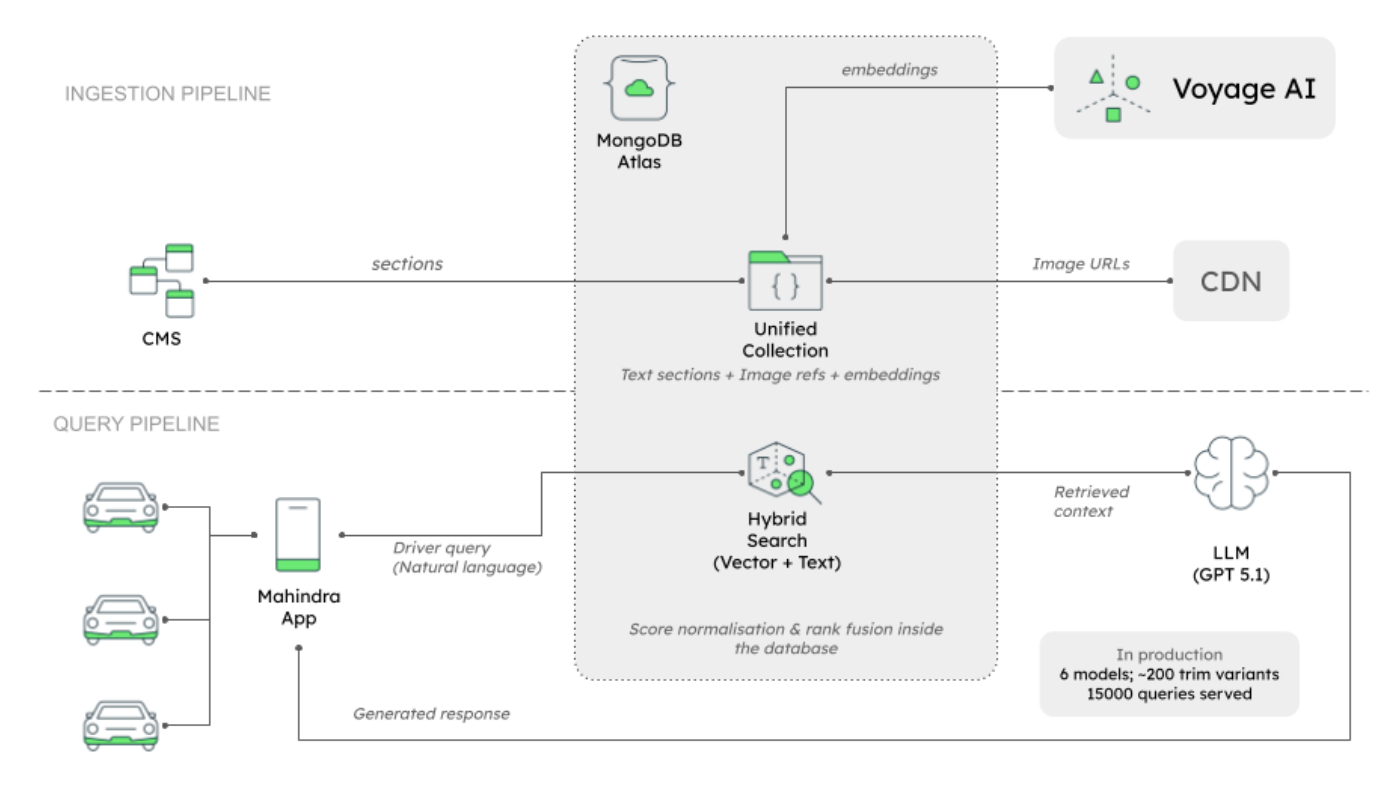
The system runs on MongoDB Atlas, uses Voyage AI’s multimodal-3 model for embeddings, generates answers with GPT-5.1, and uses MongoDB hybrid search for retrieval. It has served more than 15,000 customer queries in production.
Two things made MongoDB Atlas a natural fit for this work. The first is the document model, which let Mahindra represent each manual section, its image metadata, and its vehicle applicability as a single retrieval-ready unit, rather than context scattered across relational tables. The second is that Atlas brings together, in one unified platform, the pieces an AI application needs: operational data, Vector Search, Atlas Search, and conversation history. Without it, the team would have had to integrate and keep a multiservice stack in sync.
The product decision was important: keep help inside the app that customers already use. For a driver, that means a dashboard symbol, unfamiliar control, or feature question can be answered while the driver already manages the vehicle. For Mahindra, it’s a step toward an ownership experience where the vehicle and the digital support around it can keep improving after purchase.
Figure 1. VehicleGPT architecture.
Shaping manual content for retrieval
Production retrieval augmented generation (RAG) systems often fail or succeed before the model is called. Answer quality depends on whether the system can retrieve the right context, and that depends on how developers shape the source content. Mahindra's team recognized that early and treated retrieval quality, not model selection, as the constraint that would decide whether VehicleGPT became genuinely useful in customers’ hands.
Mahindra’s manual content came from a relational CMS built for authoring and governance, not AI retrieval. Useful context, such as section text, heading hierarchy, image metadata, safety notes, model applicability, and trim relationships lived across multiple tables. Searching one table directly would not have returned enough context, while joining that data at query time would have added latency and application complexity.
VehicleGPT materializes that content into MongoDB documents shaped around retrieval. Each manual section becomes a document with its hierarchy and related fields preserved. Image documents carry authored metadata such as title, description, and keywords, along with a CDN URL for the image itself. Text and image documents can then live in the same collection and move through the same indexing and retrieval path.
This enables MongoDB Atlas to serve as the layer where operational content becomes retrieval-ready content. The application doesn’t have to reconstruct manual context on every query. It retrieves from documents that already reflect the unit of meaning the assistant needs.
The document model also gives Mahindra room to extend the system. VehicleGPT currently uses the English text path of Voyage AI’s multimodal-3 embeddings, and it represents image documents through authored metadata. The same foundation can support future image embeddings, where the model embeds pixels directly, and multilingual retrieval, where a query in one language retrieves content authored in another.
Why hybrid search matters for vehicle manuals
VehicleGPT uses MongoDB hybrid search to combine vector search and text search. In this use case, the combination is central because vehicle manuals contain both user-described concepts and exact technical terms.
Vector search helps when customers don’t know the official name of a feature. Drivers might ask about an “orange engine light,” while the manual refers to a “malfunction indicator lamp.” They might ask how to “fold the back seats,” while the manual uses a more specific feature name. Semantic retrieval helps bridge the gap between customer language and authored manual language.
Text search remains necessary because vehicle manuals also contain exact-match information: part numbers, fault codes, button labels, feature names, variant names, and warning indicator terms. In these cases, semantic similarity alone can introduce noise. The exact string matters.
Without hybrid search in the database, Mahindra’s engineering team would have had to build and maintain that orchestration in the application layer: run separate searches, normalize scores, merge ranked lists, handle documents that appear in only one result set, tune ranking behavior, and keep that logic stable as content evolved.
That extra plumbing would have compounded the complexity already present in the source content. The team first had to assemble the data from multiple CMS tables into useful retrieval documents. If hybrid ranking also lived outside the database, the application would have complexity in two places: content reconstruction and search orchestration.
MongoDB Atlas simplifies that pattern. The team can shape the content once, index it once, and retrieve it using both semantic and lexical signals. MongoDB handles result merging inside the database, so the application can stay focused on the user interaction and answer generation.
Shipping faster without fragmenting the stack
The alternative architecture was a multi-service stack: an operational database, a vector database, and a separate store for conversation history. That approach would have required more integration work at the start and more operational work over time.
MongoDB Atlas consolidated the core data and retrieval requirements into one managed platform. The document model enables Mahindra to ingest CMS-derived content without forcing it into a rigid schema. The team could add new fields as it iterated. Vector search lived directly on the collection, avoiding a separate retrieval system. Hybrid search combined vector and text results without a custom ranking infrastructure in the application.
That consolidation shortened the path to production and reduced the number of systems the team had to keep synchronized. It also made the implementation materially more cost-effective than the alternative transformation-led approach, completing the work at a fraction of the cost without fragmenting the architecture. Just as important, it preserved flexibility: the team can add new document types, image embeddings, service videos, additional metadata, and multilingual content without redesigning the foundation.
VehicleGPT’s RAG service keeps generation separate from retrieval. The service receives retrieved context and passes it to a generation model; the team can change the model behind that interface as better options become available. The retrieval foundation shouldn’t have to be rebuilt every time the generation layer changes.
What this adds up to
VehicleGPT isn’t just an AI-powered assistant for a manual. It is an example of how a production AI application depends on data architecture as much as model choice.
MongoDB Atlas gives Mahindra a document model that can represent manual sections, image metadata, and vehicle applicability together; vector search for semantic retrieval; hybrid search for combining semantic and exact-match signals; and a managed platform that avoids unnecessary service fragmentation.
The result is an assistant that fits the ownership journey: available in the customer app, grounded in vehicle-specific content, and built on an architecture that can extend as new modalities and languages become important.
For Mahindra, that foundation supports more than one feature launch. It reflects a broader bet—one many OEMs are still working toward—that the ownership experience itself can keep improving after the sale, through how customers access, understand, and interact with their vehicles. VehicleGPT is an early expression of that, and Mahindra designed the architecture underneath it to carry the next ones.
The retrieval foundation Mahindra built for VehicleGPT is one you can deploy on MongoDB Atlas today. It requires no separate vector database and no custom hybrid search code, and it features a document model that grows with your content.
Next Steps
Start where it matters most for your use case:
Combine semantic and exact-match retrieval in a single query with the hybrid search tutorial for MongoDB Atlas.
Embed text, images, and other modalities through one pipeline with Voyage AI multimodal embeddings on MongoDB Atlas.
View reference architectures for production RAG, including manual- and document-grounded assistants, in the MongoDB Atlas Architecture Center.