Modern vehicles act as distributed computing systems and generate terabytes of telemetry. However, the majority of after-sales diagnostic and repair workflows still depend on static documentation and basic keyword search. In 2025, J.D. Power reported that 12% of repairs are not completed correctly on the first visit.1 These repeat repairs increase costs, reduce workshop throughput, and erode customer trust.
A major contributor to this problem is the fragmentation of useful data. Diagnostic knowledge is fragmented across documents, images, software versions, and system dependencies that simple search applications cannot access easily.
To close this gap, leading automotive organizations adopt a unified architecture that combines GraphRAG (the Relationship Engine) and Multimodal RAG (the Visual Engine). This architecture is powered by MongoDB Atlas as a single operational data platform.
Figure 1. Unified Vector, Graph and Multimodal Architecture for Automotive Diagnostics on MongoDB Atlas.
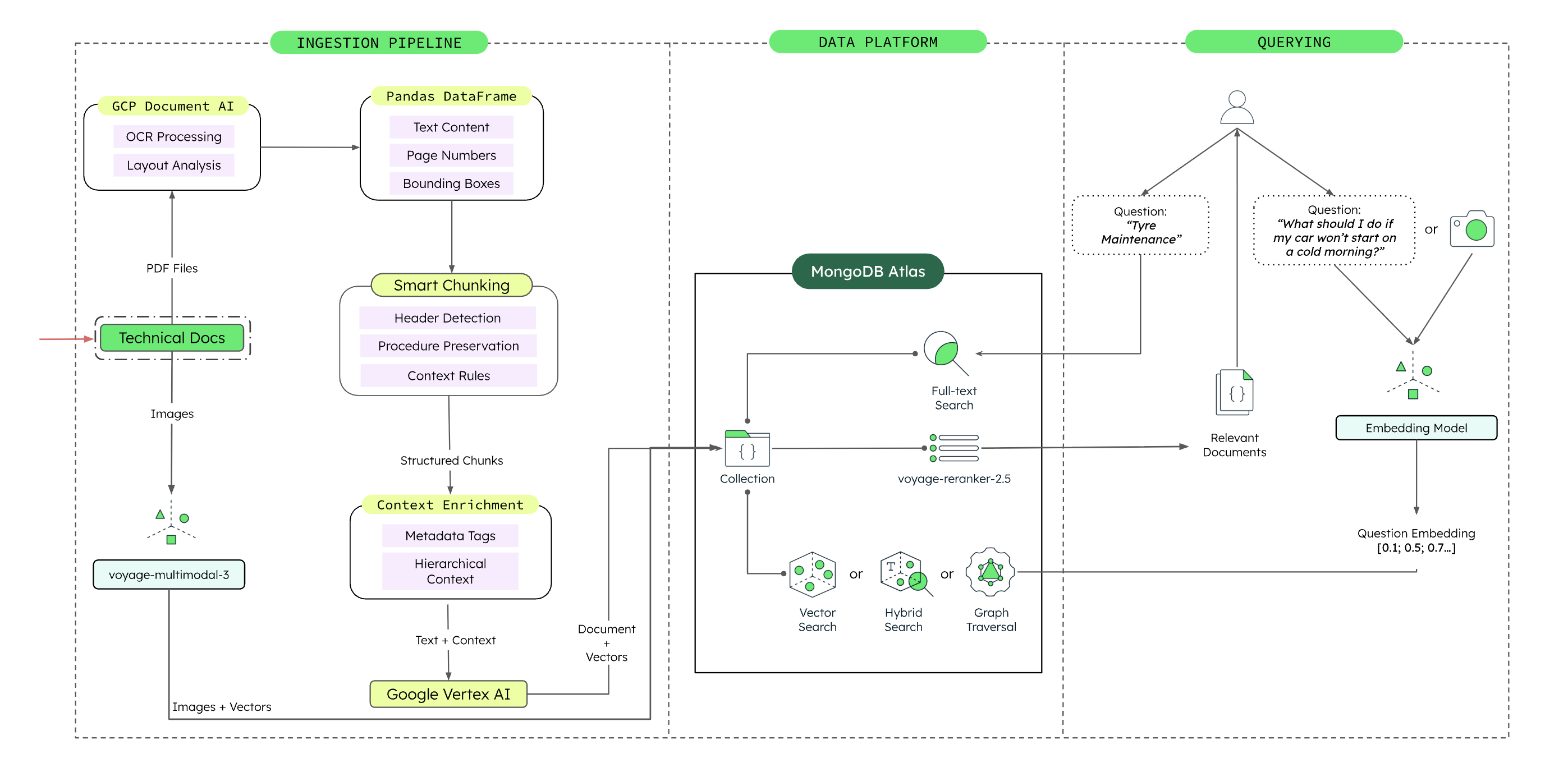
This architecture shows how technical documents, images, embeddings, and system relationships are ingested, stored, and queried through a single MongoDB Atlas-based platform.
Part I: The relationship engine (GraphRAG)
In modern vehicles, a mechanical symptom often originates in software. Traditional Retrieval-Augmented Generation treats service content as disconnected text chunks. This approach ignores system behavior, dependencies, and failure chains, which leads to the chain reaction problem.
Consider a common No Fault Found (NFF) scenario where a technician replaces a flickering infotainment screen, only to find the screen was healthy. The root cause was actually a software race condition in a gateway module on the Controller Area Network (CAN) bus. Standard vector search fails here because it measures semantic similarity—viewing screen flicker as unrelated to a gateway module update—rather than system relationships. Consequently, technicians optimize locally by replacing visible components while the systemic fault remains unresolved. Organizations require a diagnostic approach that understands relationships, not just words.
Model causality with MongoDB and GraphRAG
GraphRAG overlays a knowledge graph on top of the unstructured and semi-structured data. Instead of only retrieving relevant documents, the application retrieves connected entities and their relationships.
MongoDB’s flexible document model and the $graphLookup stage lets users store and traverse these relationships next to the source content. These relationships capture how vehicles actually behave, not how manuals are written. For example, relationships can be represented as:
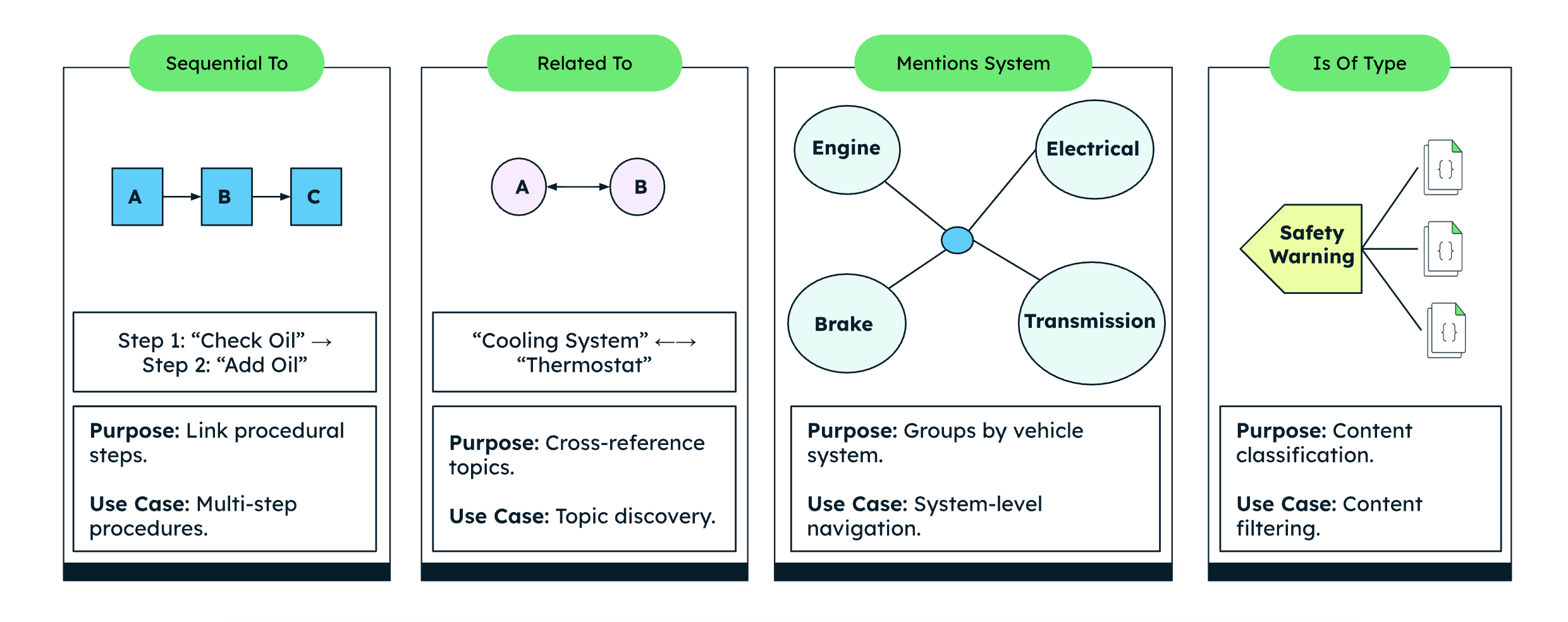
SEQUENTIAL_TO:
Step A must occur before Step B.
Example: “Perform smoke test” → sequential to → “Inspect vacuum hose routing.”
CAUSES / LEADS_TO:
Models fault propagation across systems.
Example: “Thermostat failure” → causes → “ECU over-temperature fault.”
COMPATIBLE_WITH:
Links parts, firmware versions, and specific VIN ranges.
Example: “Gateway module v3.2” → compatible with → “VIN range X123–X999.”
By storing these relationships in MongoDB alongside Diagnostic Trouble Codes (DTCs), service procedures, wiring diagrams, and field reports, the application uses $graphLookup to traverse the dependency graph. Instead of only answering What mentions screen flicker?, the system identifies which modules interact with the screen on a specific VIN, or which software versions correlate with known flicker issues. GraphRAG turns a simple text query into a context-aware diagnostic path that reflects the real system of systems nature of modern vehicles.
Figure 2. Some relationship types for Knowledge Graph construction.
Part II: The visual engine (Multimodal RAG)
Even when relationships are known, many diagnostics fail because critical knowledge is stored as images. As experienced master technicians retire, workshops rely more on a digital-native workforce. This workforce expects intuitive, visual tools rather than dense text manuals. This includes service knowledge living in non-text content, such as wiring diagrams, exploded component views, torque patterns, and connector layouts.
Traditional search engines ignore or underutilize this visual information.
The search limitation
Traditional text-only search often fails in scenarios where visual context is key. For example, if a technician searches for a blue connector location but the manual contains only an unlabelled photo, the search engine returns no results. This requires the technician to manually scan documents, which slows down Fixed Right First Time (FRFT) performance.
Interleaved retrieval with multimodal RAG
Multimodal RAG adds vision capabilities to the organization’s retrieval stack. Embedding models such as Voyage AI’s voyage-multimodal-3.5 process interleaved data. This data consists of documents that mix text and images to generate embeddings for both.
With MongoDB Atlas as the organization's document store and vector database, the application stores text, images, and embeddings in a single document. While using Atlas Vector Search ($vectorSearch) to find matches across modalities. This enables visual verification workflows where a technician takes a photo of a part, and the system matches that image against stored diagrams and annotated screenshots. Instead of guessing, the technician receives the matched component along with exploded views, torque specs, and wiring paths.
Figure 3. Multimodal retrieval with voyage-multimodal-3.5.

Part III: The unified architecture
GraphRAG and Multimodal RAG deliver value on their own, but the real advantage appears when combined on a unified data architecture. Scattering data and AI stacks across multiple point solutions—separate systems for vectors, graphs, and image storage—introduces significant complexity and operational risk. This fragmentation often leads to schema drift, out-of-sync indexes when manuals change, extra latency from cross-system joins, and higher operational overhead. In safety-critical maintenance, where engineering, service, and IT teams own different parts of the stack, such stale or inconsistent information is unacceptable.
The unified advantage with MongoDB Atlas
MongoDB Atlas consolidates documents, vectors, graph-like traversals, and rich metadata in a single operational data store.
Document model
MongoDB Atlas consolidates documents, vectors, graph-like traversals, and rich metadata in a single operational data store. Using a flexible JSON-like document model, the application stores unstructured text, structured fields (such as DTC codes and VINs), vector embeddings, relationship data, and image metadata in one place. This flexibility allows the AI solution to evolve without disruptive migrations; when adding a new relationship type, embedding model, or content source, you simply add fields rather than redesigning a rigid schema.
Unified querying and orchestration
MongoDB’s Aggregation Operations lets you build end-to-end workflows in a single pipeline. For example, you can:
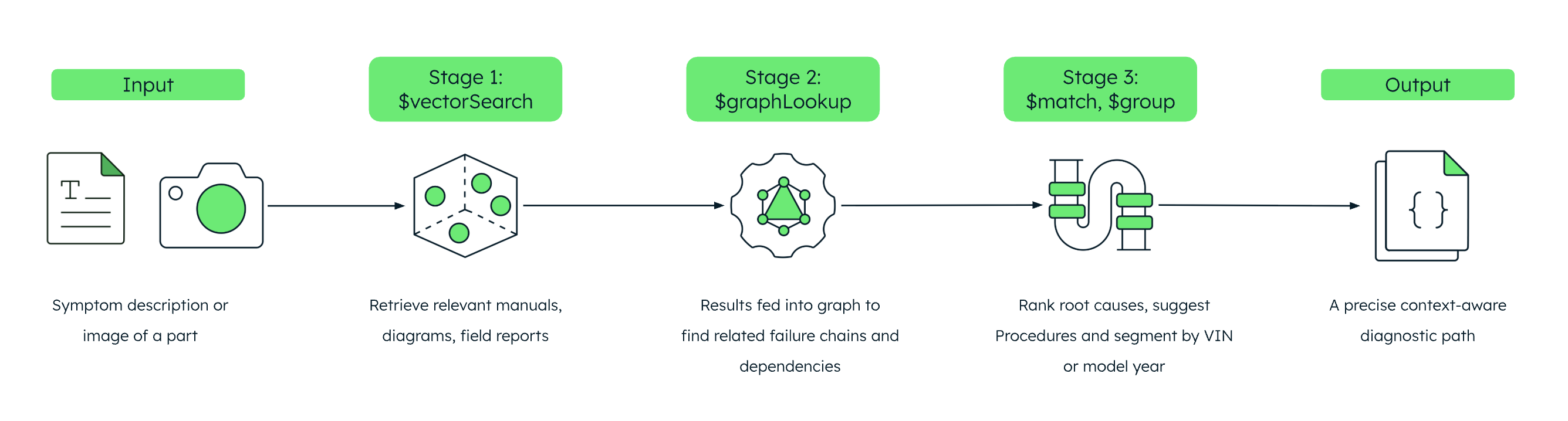
Use $vectorSearch to retrieve the most relevant manuals, diagrams, and field reports for a description or image of a symptom.
Feed those results into $graphLookup to traverse engineering relationships and failure chains.
Apply additional stages such as $match, $group, and $project to rank root causes, suggest procedures, or segment by VIN or model year.
The platform orchestrates the entire retrieval and reasoning layer in one query path. This keeps diagnostic logic auditable, repeatable, and suitable for safety-critical environments.
Figure 4. End-to-end orchestration in a single MongoDB query pipeline.
The future technician workflow
By building a unified GraphRAG and multimodal RAG architecture on MongoDB Atlas, organizations move from passive search to guided, intelligent workflows. Consider a technician facing a System Too Lean error:
Graph layer: The system identifies that a lean condition is strongly associated with vacuum leaks and prioritizes diagnosis for this VIN based on historical data.
Multimodal layer: The system surfaces the exact vacuum hose routing diagram for this specific engine variant so the technician can visually trace components.
Logic and sequence layer: Based on stored SEQUENTIAL_TO relationships, the system recommends the appropriate smoke test procedure and lists validation steps in order.
Instead of hunting through PDFs and disconnected systems, the technician receives an interactive, system-aware diagnostic path that aligns with real-world vehicle behavior. The technician spends less time searching and more time fixing the vehicle.
Conclusion: from search to solution
As vehicles become more software-defined and complex, traditional text search and static manuals no longer support efficient diagnostics. The constraint is not data volume. It is the ability to retrieve and reason over relationships, modalities, and context.
By building a unified GraphRAG and Multimodal RAG architecture on MongoDB Atlas, organizations reduce NFF rates, improve FRFT performance, and preserve institutional knowledge.
MongoDB Atlas provides a single, flexible unified database platform to store, relate, and retrieve all diagnostic knowledge—including textual, structural, and visual content. This approach transforms operations from a simple data store into a diagnostic intelligence platform. It allows technicians to move from search to solution in every repair.
Related Resources
1 Source: J.D. Power (March 2025)