Hierarchical navigable small world (HNSW) is a powerful algorithm used in computer science and information retrieval systems to efficiently search large datasets. It addresses the challenge of finding the nearest neighbors of a given data point in a high-dimensional space by organizing the data in a vector database.
Before diving into HNSW, it's important to understand the foundational concept of a navigable small world graph, since it is the building block of HNSW.
Table of contents
- How small world networks and skip lists improve search precision
- Background of HNSW
- Key concepts in HNSW
- How to build an HNSW
- Search process
- Graph structure
- Use cases of HNSW
- How to build a HNSW
- Conclusion
How small world networks and skip lists improve search precision
A navigable small world graph is a network structure where most points, or "nodes," are connected in a way that allows for efficient movement between any two points with only a few steps. This characteristic, known as the "small world" property, means that even in large networks, it takes only a limited number of jumps to connect distant nodes. Think of it as a social network: Although you may have thousands of friends, you can often reach someone across the globe through just a few mutual acquaintances. This structure is essential for systems like social media and communication networks, where moving quickly between points is a priority. However, to make searches even more efficient, particularly in massive datasets, additional layering is sometimes introduced.
This is where skip lists come in. A skip list is a layered data structure that speeds up searches by organizing information so that higher layers provide broad, approximate connections, while lower layers contain specific, detailed links. This layered setup allows searches to bypass unnecessary steps, “skipping” over parts of the dataset to hone in on relevant information quickly.
HNSW graphs combine both the small world property and the skip list’s hierarchical layering. The algorithm takes advantage of the structure's gradation by using the higher layers for rapid, coarse-grained exploration, while the finer, lower layers handle detailed searches. By optimizing the path toward the most similar nodes, based on a data structure and distance metric among neighboring nodes, HNSW enables efficient, precise navigation through massive datasets. This combination of coarse-to-fine search capability makes HNSW a powerful tool for complex, high-dimensional search tasks that traditional algorithms may struggle to perform.
Background of HNSW
Hierarchical navigable small worlds are used for high-dimensional similarity search and stand out due to their ability to efficiently find the nearest neighbors in large, multi-dimensional datasets. Hierarchical navigable small worlds were first introduced in a 2016 HNSW paper and have multiple implementations, including one in the Apache Lucene project.
HNSW operates by creating a multi-layered graph structure where each layer is a simplified, navigable, small world network. This structure allows for remarkably quick and accurate searches, even in vast, high-dimensional data spaces, mainly by use of skip lists. Its foundations relate to approximate nearest neighbors (ANN). ANNs are often used in vector similarity search and can be split into three distinct categories: trees, hashes, and graphs. HNSW can be more specifically categorized as a proximity graph, in which two vertices are linked based on their proximity (closer vertices are linked).
Key concepts in HNSW
HNSW is the result of a fusion between two algorithms: skip list and navigable small world. To comprehend HNSW, familiarity with these constituent algorithms is essential. Let's delve into the intricacies of both skip list and small world.
What is a skip list?
As the name implies, the skip list draws inspiration from the linked list data structure and can be viewed as an extension thereof. Conceived by David Pugh in 1990, the skip list serves as an optimized alternative to traditional linked lists.
The necessity for skip lists arises from the O(n) search time complexity of a linked list, which may not be optimal for scenarios prioritizing swift execution. Hence, a more efficient linked-list algorithm becomes imperative. Skip list boasts an anticipated time complexity of O(log n), significantly outperforming linked lists in random access scenarios. With a layered structure featuring multiple nodes at each level, the worst-case space complexity is O(n log n), where n represents the number of nodes at the bottom-most level in a skip list.
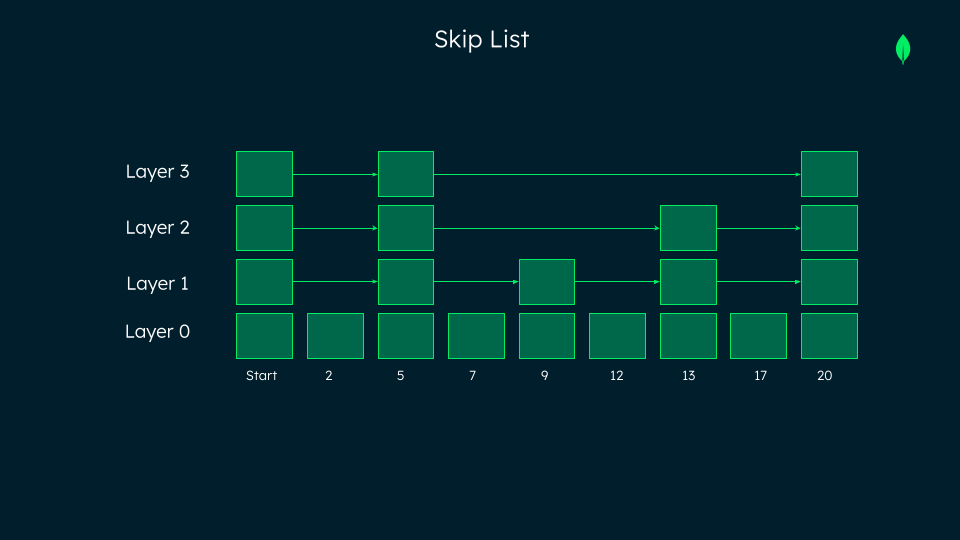
What is the concept of a hierarchical navigable small world?
The concept of a hierarchical navigable small world refers to a structured and organized network or system that allows users to easily navigate through complex information hierarchies. It is a method for organizing and presenting information in a way that makes it easy to find and access specific content.
The small world property in HNSW refers to the ability to reach any data point in the dataset from any other data point using a small number of hops based on an entry point. By carefully organizing the data points and creating connections between them, HNSW ensures that the search process can efficiently traverse the dataset, even in high-dimensional spaces.

How to build an HNSW
HNSW graphs enable efficient approximate nearest neighbor (ANN) search through a multi-layered graph structure. This approach leverages the power of graph theory to navigate large datasets quickly and accurately by creating a hierarchical system where each level acts as a simplified overview of the one below it.
Building an HNSW involves three major steps: constructing the HNSW index, querying vectors, and performing vector searches.
HNSW index
Creating an HNSW index involves these steps:
Forming the hierarchy
Level assignment
Elements are randomly assigned levels, with fewer elements at higher levels. The level distribution follows an exponentially decaying probability. This randomization ensures a balanced structure that can handle dynamic datasets efficiently.
Layer construction
The probabilistic tiering in HNSW, where nodes distribute across different layers like skip lists, is governed by a parameter typically denoted as mL. This parameter determines the likelihood of a node appearing in successive layers, with the probability decreasing exponentially as the layers ascend. Each layer is a proximity graph of elements at that level, allowing logarithmic complexity scaling. Higher layers provide a broader overview, while lower layers offer finer details.
Adding elements
Greedy search
New elements start from the top layer, connecting to the nearest neighbors down through each level. The maximum number of connections per element (M) and the dynamic list size (efConstruction) are key parameters that control the quality and efficiency of the index. These parameters ensure that each element is well-connected, improving the search performance.
Optimization
Heuristic selection
This ensures diverse, effective connections, balancing the graph. This heuristic examines candidate connections and keeps those that maintain the graph's overall connectivity.
Scale separation
Scale separation separates links by distance to improve navigation, starting from the upper layers with longer links and refining the search at lower layers with shorter links. This separation enhances the efficiency of the search process.
Searching in HNSW
Start at the top
Begin the search from a random, high-level entry point.
Greedy descent
Move through layers, always heading toward the closest neighbor to the query vector before descending to the next level. This approach allows the algorithm to quickly narrow down the search space and move in the direction of the query vector, moving to increasingly dense graphs each time a descent occurs.
Refinement
As you descend, the search becomes more precise, efficiently finding the nearest neighbors.The lower layers refine the search results, ensuring high accuracy.
HNSW’s hierarchical approach, combined with careful parameter tuning, significantly boosts search efficiency, especially in high-dimensional data.
Each of the trajectories traversed from the top level entry point to the closest vector at the bottom level represents one candidate exploration. The search parameter efSearch, called numCandidates in the $vectorSearch interface, controls the number of entry points/trajectories that are explored. Increasing this increases the likelihood that the top k vectors closest to the query vectors are discovered.
Insertions and deletions in the HNSW graph ensure its dynamic adaptability and robustness in handling high-dimensional datasets based on entry points and distance metrics. When a new node is added for the graph construction, the algorithm first determines its position in the hierarchical structure depending on where the node appears and the maximum number of nodes. This process involves identifying the pre-defined entry point for the node based on the probabilistic tiering governed by the parameter mL.
The process of removing a node from vector databases involves the careful updating of connections or deleted elements, particularly in its neighbors, across multiple layers of the hierarchy based on linked lists among the current code, next layer, or top layer. This is crucial to maintain the structural integrity and navigability of the graph in terms of the search complexity while the algorithm traverses within the vector database.
Here is an example for a Python implementation:
Search process
At the core of the HNSW method lies a hierarchical organization of data points into a graph structure. Points at higher levels act as shortcuts to quickly reach similar points in lower levels, reducing the search space. These processes underscore the adaptability of HNSW, making it a robust choice for dynamic, high-dimensional similarity search applications.
By leveraging the properties of hierarchical structures and the small world phenomenon, HNSW significantly reduces the number of distance calculations required, making it ideal for applications where quick responses are crucial, such as recommendation systems or similarity-based search.
HNSW is highly scalable and can handle large datasets efficiently. Its query performance allows for dividing the data into smaller sets, enabling parallel processing and better resource utilization given their entry point. HNSW can effectively handle both low-dimensional and high-dimensional spaces, making it a versatile algorithm applicable to various domains for similarity search.
Tuning your HNSW search
Several algorithms are used in HNSW to optimize memory usage, improve search accuracy, and enhance both search performance and speed. To further refine search outcomes, increasing the number of candidates considered during the search can help balance between latency (processing time) and recall (accuracy). By evaluating a larger pool of candidates, recall can be improved at the cost of slightly higher latency, allowing users to prioritize accuracy as needed.
Another technique, prefiltering, can also improve search efficiency by narrowing the search space. In prefiltering, an initial candidate list is generated through a filtering step before the HNSW search begins, helping to streamline the process and reduce unnecessary computations.
Compared to brute force methods, HNSW stands out as a scalable and efficient solution for similarity searches in vector databases, largely due to its use of skip lists. This combination of tailored algorithms and hierarchical structures enables HNSW to handle large, high-dimensional datasets with significantly greater speed and precision than traditional search approaches.
Graph structure
As discussed earlier, HNSW builds on the small world property, where most nodes can be reached through just a few hops, making search efficient even in large datasets.
In HNSW, each point is connected to others within its level and to higher levels, creating a hierarchical structure. This graph stores connections and metadata like nearest neighbors and distances, aiding in pattern analysis. Additional data structures, such as priority queues or hash tables, help streamline tasks like insertion and deletion.
Insertions and deletions play pivotal roles in maintaining the dynamic adaptability and robustness of the graph, particularly when dealing with high-dimensional datasets, given their memory consumption. Leveraging cosine similarity as a metric for measuring distances between nodes, the HNSW creates efficient insertions and deletions among top layer and next layer to find the optimal value, reinforcing its capability for dynamic and accurate nearest neighbor searches in high-dimensional datasets as well as considering memory usage or memory footprint.
Insertions
Upon introducing a new node to the graph, the algorithm orchestrates its placement within the hierarchical structure. This involves identifying the entry layer for the node through a probabilistic tiering mechanism governed by the parameter mL. Commencing from that layer, the insertion process establishes connections for the new node with the M closest neighbors within that layer.
If a neighboring node surpasses Mmax connections, excess connections are pruned. The node then progresses to the subsequent layer in a similar manner, continuing until it reaches the bottom node, where Mmax0 denotes the maximum connectivity.
Deletions
The removal of a node from the graph entails meticulous updates to connections, particularly among its neighbors, spanning multiple layers of the hierarchy. This meticulous process is vital for preserving the structural integrity and navigability of the graph.
Different HNSW implementations may employ diverse strategies to safeguard connectivity within each layer, ensuring that no nodes are orphaned or disconnected from the graph. This approach safeguards the ongoing efficiency and reliability of the graph for nearest neighbor searches.
Both insertion and deletion operations within HNSW are crafted for efficiency while upholding the hierarchical and navigable characteristics of the graph—essential elements for the algorithm's swift and precise nearest neighbor search capabilities. These processes underscore HNSW's adaptability, positioning it as a resilient choice for dynamic, high-dimensional similarity search applications.
Use cases of HNSW
Hierarchical navigable small world has gained significant attention in various fields due to its versatility and effectiveness. Implementing a query vector based on HNSW can bring several benefits to businesses.
It not only improves user experience by providing intuitive navigation, reducing search time, and increasing user engagement, but also helps to optimize content discoverability, as search engines can better understand the organization and relevance of information. Let’s explore some of the applications and use cases where HNSW has proven to be valuable:
Image retrieval
HNSW has been extensively used in image retrieval systems, as it provides a fast and scalable solution for searching high-dimensional feature vectors representing images. By constructing an HNSW graph, images can be efficiently indexed, and nearest neighbors can be retrieved with sub-linear time complexity. This enables real-time image search applications, such as reverse image search engines and content-based image retrieval systems.
Natural language processing (NLP)
In natural language processing, HNSW has shown promising results in semantic search and document similarity tasks. By representing text documents as high-dimensional vectors, HNSW facilitates efficient retrieval of semantically related documents. This has applications in document clustering, recommendation systems, and question-answering systems, where finding similar documents or generating relevant responses is crucial.
Music recommendation
HNSW has been successfully employed in music recommendation systems, where the goal is to suggest songs or playlists based on user preferences. By representing songs as feature vectors capturing their audio characteristics, HNSW enables fast retrieval of similar songs. With its efficient vector database and multi-layer structure, HNSW can handle large music collections and quickly provide recommendations based on users' listening history or preferences.
Anomaly detection
Anomaly detection is an essential task in various domains, including fraud detection, cybersecurity, and network monitoring. By constructing an HNSW graph using a representative feature space, anomalies can be detected by measuring distances or similarities to the nearest neighbors. HNSW's ability to handle large-scale datasets and perform approximate nearest neighbor search significantly improves the efficiency and accuracy of anomaly detection systems.
Recommendation systems
HNSW has been utilized in collaborative filtering algorithms to efficiently find similar users or items based on their features or rating vectors. By constructing an HNSW graph, similarity-based recommendations can be generated with sub-linear time complexity, enabling real-time personalized recommendations in large-scale systems. This application of HNSW enhances the accuracy and scalability of recommendation systems.
How to build a HNSW
If you're considering implementing a query vector based on HNSW, follow these steps:
- Assess your content and identify the multilayer structure that makes sense for your information.
- Create main categories and subcategories, ensuring a logical organization.
- Design a navigation system that allows users to easily transition between categories and subcategories.
- Implement a search functionality that enables users to find specific content quickly.
- Regularly review and update the hierarchical structure to ensure it remains effective.
While creating a HNSW can bring significant benefits, there are challenges to consider for implementing your vector search. Ensuring a logical and intuitive organization, avoiding information overload, and maintaining simplicity while accommodating complexity can be difficult when implementing your vector search.
It is essential to conduct user testing and gather feedback to identify potential issues and make necessary improvements for ensuring a high-quality query vector. Regular evaluation and optimization are key to overcoming challenges and ensuring an optimal user experience.
Several tools and technologies can aid in creating navigable small world graphs. Content management systems like WordPress offer plugins and themes that provide hierarchical navigation functionalities. Additionally, user experience (UX) design tools like Adobe XD and Sketch can assist in designing and prototyping user-friendly interfaces. Utilizing these resources can simplify the creation and maintenance of HNSW indexes. To optimize SEO with navigable small world graphs, consider the following tips:
- Use descriptive and keyword-rich headings for each category and subcategory.
- Create a clear URL structure that reflects the hierarchy of the content.
- Implement internal linking between related categories and subcategories.
- Ensure fast page loading speed by optimizing images and minimizing code.
- Regularly update and optimize content to ensure its relevance and usefulness.
Conclusion
A HNSW has the potential to greatly enhance user experience, improve content discoverability, and boost SEO efforts. By implementing a logical and intuitive hierarchical structure, businesses can make it easier for users to navigate complex information and increase customer satisfaction. Vector databases and vector search solutions often use HNSW algorithms. For example, MongoDB Atlas Vector Search uses the hierarchical navigable small worlds algorithm to perform the semantic search. You can use Atlas Vector Search support for ANN queries to search for results similar to a selected product, search for images, etc.
Investing time and effort into understanding and implementing a HNSW-based solution can lead to significant growth opportunities for your business.
Learn more about HNSW and leverage the power of MongoDB Atlas Vector Search for performing semantic search with ANN queries that use the HNSW algorithm.