Die Digitalisierung sollte das Archivproblem lösen. Seiten scannen, optische Zeichenerkennung (OCR) nutzen, Stichwortsuche aktivieren – fertig. Doch Jahrzehnte und Millionen von Dollar später bleiben die meisten Zeitungsarchive für ernsthafte Forschung im Wesentlichen unbrauchbar.
Man stelle sich eine große US-amerikanische Zeitung vor, deren gedruckte Ausgaben eingescannt und den Abonnenten zur Verfügung gestellt werden. Für Forscher, die nach historischen Rohstoffpreistrends suchen, hat die Digitalisierung fast nichts verändert – sie blättern immer noch manuell durch Tausende von Ausgaben. Der Engpass liegt nicht in der Archivierung, sondern im Abrufen der Daten.
OCR hat erwartungsgemäß Schwierigkeiten mit jahrhundertealtem Zeitungspapier: abgenutztes Papier, ungewöhnliche Schriftarten, komplexe Layouts. Das eigentliche Problem ist jedoch das, wofür OCR nie entwickelt wurde: die in Diagrammen, Graphen und Datenvisualisierungen eingebettete Bedeutung. Diese visuellen Artefakte – oft der analytisch wertvollste Inhalt – bleiben für Suchsysteme völlig unsichtbar.
Museen und Archive weltweit berichten von ähnlichen Mustern. Eine Institution erreichte durch Flachbettscanner, spezielle Halterungen und umfassende Qualitätssicherungsprozesse eine nahezu perfekte OCR-Genauigkeit. Doch das grundlegende Problem bleibt bestehen: Die Stichwortsuche kann nicht die semantische Vielfalt liefern, die für Langzeitanalysen, Trendidentifikation oder vergleichende Forschung über Jahrzehnte hinweg erforderlich ist.
Der multimodale KI-Durchbruch
Der Wechsel von OCR plus Suche zu multimodalen Vektoreinbettungen steht für mehr als nur eine verbesserte Genauigkeit. Es handelt sich um ein anderes Modell dessen, was „suchbar“ bedeutet.
voyage-multimodal-3.5 (das letzte Woche veröffentlicht wurde!) interpretiert Text und Bilder direkt aus Scans und bildet ganze Seiten in dichte semantische Vektoren ab. Beispielsweise vektorisiert voyage-multimodal-3.5 multimodale Daten effektiv, um wichtige semantische Funktionen aus Tabellen, Grafiken, Abbildungen, Folien, PDFs und mehr optimal zu erfassen. Dies ermöglicht Abfragen nach Bedeutung, Kontext oder visuellem Konzept – nicht nur nach exakten Schlüsselwörtern. Entscheidend ist, dass diese Modelle den semantischen Gehalt statistischer Visualisierungen verstehen und Wirtschaftsdiagramme für Anfragen wie „Inflationstrends in den 1970er Jahren“ liefern, selbst wenn kein erläuternder Text vorhanden ist.
Die Auswirkungen reichen über den Datenabruf hinaus. Zum ersten Mal werden Archive zu Datensätzen, die man tatsächlich analysieren kann. Forscher können nachvollziehen, wie sich die Berichterstattung über die Kernenergie von der politischen Debatte zum wissenschaftlichen Konsens entwickelt hat – und feststellen, ob diese Veränderungen zuerst in Leitartikeln oder in investigativen Beiträgen erschienen sind. Sie können nachverfolgen, wie sich die Verwendung von Wirtschaftsdiagrammen von Jahrzehnt zu Jahrzehnt verändert hat oder wie erneuerbare Energien von einer Randnotiz zum dominanten Thema auf den Titelseiten geworden sind.
Das ist nicht nur eine bessere Suche. Das ist der Unterschied zwischen einer statischen Sammlung und einer Forschungsinfrastruktur.
Semantische Suche in großem Maßstab
MongoDB Atlas Vector Search mit dem multimodal-3-Modell von Voyage AI ermöglicht die Beantwortung von Forschungsfragen, die mit der herkömmlichen Stichwortsuche nicht beantwortet werden können. Anstatt herauszufinden, wo der Begriff „erneuerbare Energie“ auftaucht, können Forscher entdecken, wie sich die visuelle und textliche Darstellung des Themas über Jahrzehnte entwickelt hat. Sie können die Berichterstattung auf den Titelseiten mit redaktionellen Kommentaren vergleichen, die Einführung von Datenvisualisierungen verfolgen und Verschiebungen in der Darstellungsweise erkennen.
Abbildung 1. Referenzarchitektur für die Suche in historischen Archiven.
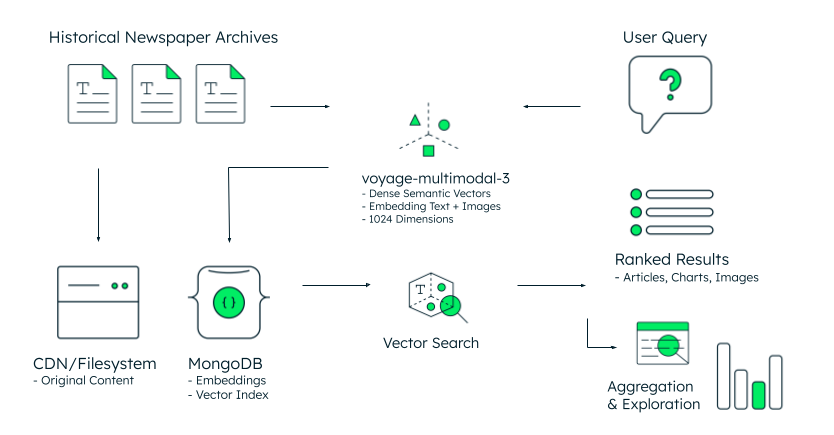
Die Architektur folgt einem einfachen Arbeitsablauf, wie in Abbildung 1 dargestellt. Historische Zeitungsarchive – die als Originalinhalte in einem CDN oder Dateisystem gespeichert sind – werden durch das neueste multimodale Modell von Voyage AI verarbeitet, das 1024-dimensionale Vektoreinbettungen sowohl aus Text als auch aus Bildern erzeugt. MongoDB speichert diese Einbettungen zusammen mit Metadaten in einem einheitlichen Dokumentenmodell und eliminiert damit die Synchronisierungskomplexität separater Vektorspeicher.
Wenn ein Forscher „Debatten über den öffentlichen Nahverkehr in den 1970er–1990er Jahren“ abfragt, verarbeitet das System diese Frage in einen semantischen Vektor unter Verwendung desselben voyage-multimodal-3.5-Modells. Die Vektorsuche von MongoDB vergleicht diesen Abfragevektor mit Millionen archivierter Einbettungen und ruft relevante Artikel, Diagramme und Bilder auf der Grundlage konzeptioneller Ähnlichkeit im hochdimensionalen Raum ab – nicht auf der Grundlage von Stichwortübereinstimmung. Die Ergebnisse werden nach semantischer Relevanz sortiert und zeigen Inhalte mit ähnlicher Bedeutung, selbst wenn die genauen Begriffe abweichen.
Die letzte Phase ermöglicht Aggregation und Erkundung: Forscher können Häufigkeitsmuster im Zeitverlauf analysieren, Ergebnisse nach Veröffentlichungsdatum oder Abschnittstyp segmentieren und statistische Visualisierungen aus den gerankten Ergebnissen erstellen. Das Aggregations-Framework von MongoDB kann dabei helfen, diese analytische Ebene zu bewältigen. Es ist einfach und intuitiv zu implementieren und bietet leistungsstarke Funktionen, um den abgerufenen Daten einen zusätzlichen Wert zu verleihen.
Die dedizierten Suchknoten von MongoDB bieten Workload-Isolation und Skalierung der Vektor-Suchinfrastruktur unabhängig von den betrieblichen Datenbanklasten. Wenn strukturierte Metadaten vorhanden sind – Veröffentlichungsdaten, Abschnittsbezeichnungen oder andere katalogisierte Attribute – kombiniert die hybride Suche von MongoDB semantische Ähnlichkeit mit traditionellen Filtern in einer einzigen Abfrage und verfeinert so die Ergebnisse, ohne die semantische Aussagekraft zu beeinträchtigen.
Roadmap für IT-Führungskräfte
Es macht Sinn, mit einer Pilotkollektion von 10.000 bis 20.000 Seiten zu beginnen – aber die Auswahlkriterien sind wichtiger als der Umfang. Die Sammlungen sollten verschiedene Inhaltstypen umfassen: Artikel, Anzeigen, Diagramme, Infografiken und gegebenenfalls Videos. Ziel ist es, zu überprüfen, ob multimodale Modelle und die Vektorsuche sowohl textuelle als auch visuelle Inhalte durch semantische Abfragen genau aufzeigen können.
Erfolgskennzahlen, die es zu verfolgen gilt: Abrufrate über 90 % bei allen Inhaltsarten, Reduzierung der manuellen Arbeitskosten, Beschleunigung der Recherche-Workflows und messbare Steigerungen der Archivnutzung. Umsatzmöglichkeiten durch API-Lizenzierung und Monetarisierung visueller Assets sind sekundäre Indikatoren – sie hängen davon ab, dass zunächst der Wert der Forschung nachgewiesen wird.
Die strategische Frage ist nicht, ob Archive modernisiert werden sollen. Es geht darum, ob Ihre Organisation Archive als statische Sammlungen betrachtet, die es zu bewahren gilt, oder als dynamische Wissenssysteme, die einen fortlaufenden Wert generieren können. Multimodale KI und Vektorsuche ermöglichen Letzteres – aber nur, wenn die umgebende Infrastruktur analytische Arbeitsabläufe und nicht nur die Datenabfrage unterstützt.
Das ist keine schrittweise Verbesserung. Es ist eine kategorische Verschiebung dessen, was digitalisierte Archive leisten können.
Wie geht es weiter?
Besuchen Sie die Webseite „Medien und Unterhaltung“ und erfahren Sie mehr über die Rolle von MongoDB in der Medienbranche.
Lesen Sie das Blog Voyage-multimodal-3, um zu erfahren, wie Voyage AI Einbettungen für Text, Bilder und Screenshots ermöglicht.
Entdecken Sie die MongoDB Solutions Library, um Best Practices, einsatzbereite Vorlagen und fachkundige Anleitung für die Entwicklung leistungsstarker Anwendungen zu erhalten.
Erfahren Sie anhand dieser Erfolgsgeschichten von Kunden, wie Unternehmen mit MongoDB Innovationen umgesetzt haben.