La numérisation était censée résoudre le problème des archives. Il suffisait de scanner les pages, d'exécuter la Reconnaissance Optique de Caractères (OCR), d'activer la recherche par mots-clés, et la tâche était terminée. Pourtant, des décennies et des millions de dollars plus tard, la plupart des archives des journaux restent essentiellement inutilisables pour des recherches sérieuses.
Prenons l'exemple d'un grand journal américain dont toutes les éditions imprimées sont numérisées et mises à la disposition des abonnés. Pour les chercheurs qui s'intéressent aux tendances historiques des prix des matières premières, la numérisation n'a pratiquement rien changé : ils continuent à feuilleter à la main des milliers d'éditions. Le goulot d'étranglement n'est pas dans la conservation — mais dans la récupération des données.
Comme on pouvait s'y attendre, l'OCR a du mal à traiter les journaux papier vieux de plusieurs décennies : papier dégradé, polices de caractères inhabituelles, mises en page complexes. Mais le problème est bien plus profond car l'OCR n'a jamais été conçue pour traiter les unités de sens intégrées dans les diagrammes, les graphiques et les visualisations de données. Ces artefacts visuels — souvent le contenu le plus précieux sur le plan analytique — restent totalement invisibles pour les systèmes de recherche.
Les musées et les archives du monde entier font état de tendances similaires. Une institution a atteint une précision OCR quasi parfaite grâce à des scanners à plat, des berceaux de numérisation spécialisés et des processus d'assurance qualité exhaustifs. Pourtant, le problème fondamental persiste : la recherche par mots-clés ne peut pas fournir la richesse sémantique nécessaire pour une analyse longitudinale, l'identification de tendances ou la recherche comparative sur plusieurs décennies.
La percée de l'IA multimodale
Le passage de l'OCR plus la recherche aux intégrations vectorielles multimodales représente un changement plus fondamental qu'une simple amélioration de la précision. C'est un modèle différent de ce que signifie pouvoir effectuer une recherche au sein d'un document.
voyage-multimodal-3.5 (qui a été publié la semaine dernière !) interprète le texte et les images directement à partir de scans, en mappant des pages entières dans des vecteurs sémantiques denses. Par exemple, voyage-multimodal-3.5 vectorise efficacement les données multimodales afin de mieux capturer les caractéristiques sémantiques clés à partir de tableaux, de graphiques, de figures, de diapositives, de PDF, etc. Cela permet de lancer des requêtes basées sur le sens, le contexte ou un concept visuel, et pas seulement des correspondances exactes de mots-clés. De manière cruciale, ces modèles comprennent le contenu sémantique des visualisations statistiques, faisant apparaître des diagrammes pour des requêtes telles que « tendances de l’inflation dans les années 1970 » même lorsqu’aucun texte explicatif n’existe.
Les implications vont au-delà de la récupération. Pour la première fois, les archives deviennent des ensembles de données que l'on peut réellement analyser. Les chercheurs peuvent mesurer le changement dans la couverture de l’énergie nucléaire, du débat politique au consensus scientifique — et déterminer si ces changements sont apparus en premier dans des éditoriaux ou des articles d’investigation. Ils peuvent suivre l'évolution des graphiques économiques d'une décennie à l'autre, ou le passage des énergies renouvelables de quelques mentions marginales à la une des journaux.
Il ne s'agit pas seulement d'améliorer la recherche. Il s'agit de faire la distinction entre une collection statique et une infrastructure de recherche.
Recherche sémantique à grande échelle
MongoDB Atlas Vector Search avec le modèle multimodal-3 de Voyage AI permet de répondre à des questions que la recherche par mots-clés traditionnelle ne peut pas résoudre. Au lieu de trouver où apparaît le terme « énergie renouvelable », les chercheurs peuvent découvrir le changement du traitement textuel et visuel de ce sujet au fil des années. Ils peuvent comparer la couverture en une avec les commentaires éditoriaux, suivre l'introduction de visualisations de données et identifier les changements dans le cadrage.
Figure 1. Architecture de référence pour la recherche dans les archives historiques.
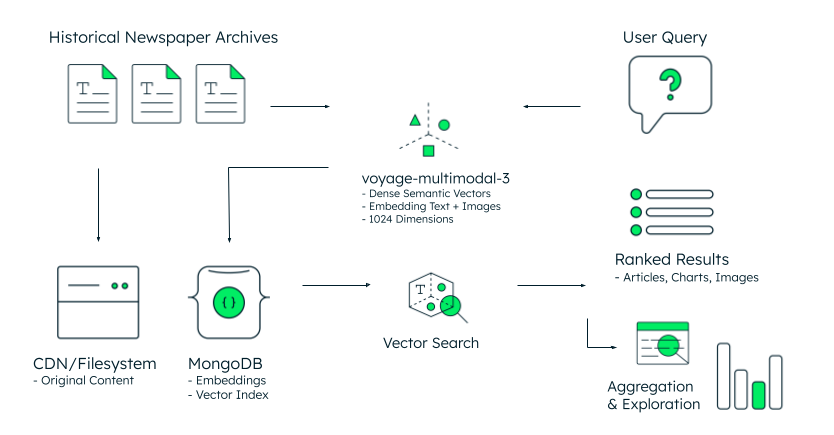
L'architecture suit un flux de travail simple, comme illustré dans la figure 1. Les archives historiques de journaux – stockées en tant que contenu d'origine dans un CDN ou un système de fichiers – sont traitées par le dernier modèle multimodal de Voyage AI, qui génère des intégrations vectorielles en 1024 dimensions à partir du texte et des images. MongoDB stocke ces intégrations aux côtés des métadonnées dans un document model unifié, éliminant ainsi la complexité de synchronisation des dépôts de vecteurs séparés.
Lorsqu’un chercheur effectue une requête sur « les débats sur les transports publics des années 1970 aux années 1990 », le système traite cette question en un vecteur sémantique utilisant le même modèle voyage-multimodal-3.5. La recherche vectorielle de MongoDB compare ce vecteur de requête à des millions d’intégrations archivées, récupérant des articles, graphiques et images pertinents en se basant sur la similarité conceptuelle dans un espace à haute dimension, et non sur la correspondance de mots-clés. Les résultats sont classés par pertinence sémantique, mettant en avant le contenu qui partage un sens même lorsque les termes exacts diffèrent.
La dernière étape permet l’agrégation et l’exploration : les chercheurs peuvent analyser les schémas de fréquence dans le temps, segmenter les résultats par date de publication ou type de section, et construire des visualisations statistiques à partir des résultats classés. Le framework d'agrégation de MongoDB peut aider à traiter cette couche analytique car il est facile et intuitif à implémenter, et ajoute de la valeur incrémentielle aux données récupérées.
Les nœuds de recherche dédiés de MongoDB permettent d'isoler la charge de travail, en assurant la mise à l'échelle de l'infrastructure de recherche vectorielle indépendamment des charges de la base de données opérationnelle. Lorsque des métadonnées structurées existent (dates de publication, libellés de sections ou autres attributs catalogués), la recherche hybride de MongoDB combine la similarité sémantique à des filtres traditionnels dans une seule requête, affinant les résultats sans sacrifier la puissance sémantique.
Feuille de route pour les dirigeants SI
Commencer par une collection pilote de 10 000 à 20 000 pages a du sens, mais les critères de sélection sont plus importants que le volume. Les collections doivent inclure divers types de contenu : articles, publicités, graphiques, infographies et éventuellement des vidéos. L'objectif est de confirmer si les modèles multimodaux et la recherche vectorielle peuvent mettre en évidence avec précision à la fois du contenu textuel et visuel grâce aux requêtes sémantiques.
Indicateurs de succès à suivre : un rappel de récupération supérieur à 90 % sur tous les types de contenu, une baisse des coûts de main-d'œuvre manuelle, une accélération des flux de travail de recherche et des augmentations mesurables de l'engagement des archives. Les opportunités de recettes liées aux licences d'API et à la monétisation des actifs visuels sont des indicateurs secondaires : il convient d'abord de prouver la valeur de la recherche.
La question stratégique n'est pas de savoir s'il faut moderniser les archives ou non. Il s'agit de savoir si votre organisation considère les archives comme des collections statiques à conserver ou comme des systèmes de connaissances dynamiques pouvant générer une valeur permanente. L'IA multimodale et la recherche vectorielle permettent cette dernière approche, mais seulement si l'infrastructure environnante prend en charge les flux de travail analytiques, et pas seulement la récupération.
Ce n'est pas une amélioration progressive, mais bien un changement de catégorie des possibilités permises par les archives numérisées.
Pour aller plus loin
Visitez la page web Médias et divertissement pour en savoir plus sur le rôle de MongoDB dans l’industrie des médias.
Lisez le blog Voyage-multimodal-3 pour découvrir comment Voyage AI permet d'intégrer du texte, des images et des captures d'écran.
Explorez la bibliothèque de solutions MongoDB pour découvrir les bonnes pratiques, des modèles prêts à l’emploi et un guide d'experts pour créer des applications puissantes.
Découvrez comment les entreprises ont innové avec MongoDB dans ces Success Stories de nos clients.