Se suponía que la digitalización resolvería el problema del fichero. Escanee las páginas, ejecute el reconocimiento óptico de caracteres (OCR), active la búsqueda por palabras clave y listo. Sin embargo, décadas y millones de dólares después, la mayoría de los archivos periodísticos siguen siendo esencialmente inutilizables para una investigación seria.
Piense en un gran periódico estadounidense con todas las ediciones impresas escaneadas y disponibles para los suscriptores. Para los investigadores que buscan las tendencias históricas de los precios de las materias primas, la digitalización casi no ha cambiado nada: todavía están hojeando miles de ediciones manualmente. El cuello de botella no es la conservación—es la recuperación.
Como era de esperar, el OCR tiene problemas con el papel de periódico centenario: papel degradado, tipos de letra inusuales, diseños complejos. Pero el problema más profundo es lo que el OCR nunca fue diseñado para gestionar: el significado incrustado en gráficas, grafos y visualizaciones de datos. Estos artefactos visuales —a menudo el contenido más valioso analíticamente— permanecen completamente invisibles para los sistemas de búsqueda.
Los museos y archivos de todo el mundo informan patrones similares. Una institución logró una precisión casi perfecta del OCR mediante escáneres de cama plana, cunas especializadas y exhaustivos procesos de control de calidad. Sin embargo, el problema de fondo persiste: la búsqueda de palabras clave no puede ofrecer la riqueza semántica necesaria para el análisis longitudinal, la identificación de tendencias o la investigación comparativa a lo largo de décadas.
El gran avance de la IA multimodal
El cambio de OCR más búsqueda a **vector embeddings** multimodales representa algo más fundamental que la mejora de la precisión. Es un diferente model de lo que significa "que se pueda buscar".
voyage-multimodal-3.5 (que se lanzó la semana pasada) interpreta el texto y las imágenes directamente a partir de escaneos, mapeando páginas enteras en vectores semánticos densos. Por ejemplo, voyage-multimodal-3.5 vectoriza de forma eficaz los datos multimodales para capturar de la mejor manera las características semánticas clave de tablas, gráficos, figuras, diapositivas, archivos PDF y mucho más. Esto activa query por significado, contexto o concepto visual, no solo por coincidencias exactas de palabras clave. Fundamentalmente, estos models entienden el contenido semántico de las visualizaciones estadísticas y muestran gráficas económicas para consultas como "tendencias de inflación en la década de 1970", incluso cuando no existe un text explicativo.
Las implicaciones van más allá de la recuperación. Por primera vez, los archivos se convierten en datasets que realmente puede analizar. Los investigadores pueden medir cómo evolucionó la cobertura de la energía nuclear desde el debate político hasta el consenso científico—y determinar si estos cambios aparecieron primero en editoriales o reportajes de investigación. Pueden rastrear cómo el uso de gráficas económicas cambió década tras década, o cómo las energías renovables pasaron de menciones marginales a dominio de primera página.
No se trata sólo de una mejor búsqueda. Es la diferencia entre una colección estática y una infraestructura de investigación.
Búsqueda semántica a gran escala
El model multimodal-3 de MongoDB Atlas Vector Search con Voyage AI permite preguntas de investigación que la búsqueda tradicional por palabras clave no puede responder. En lugar de encontrar dónde aparece "energía renovable", los investigadores pueden descubrir cómo evolucionó el tratamiento visual y textual del tema durante décadas. Pueden comparar la cobertura de portada con los comentarios editoriales, rastrear la introducción de visualizaciones de datos e identificar cambios en el encuadre.
Figura 1. Arquitectura de referencia para la búsqueda en ficheros históricos.
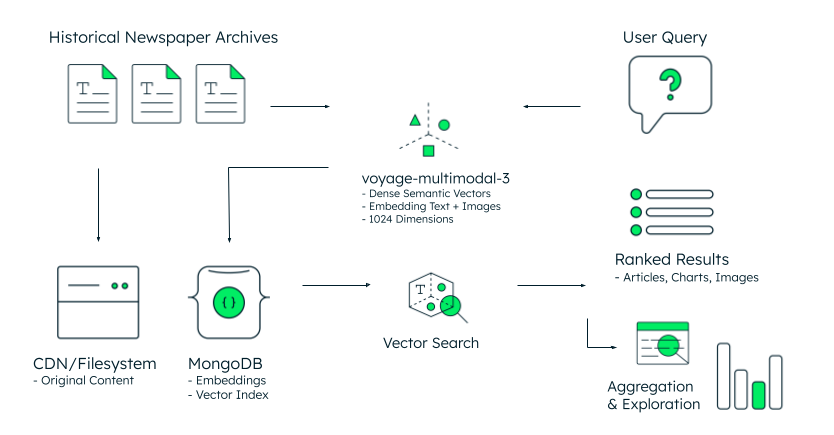
La arquitectura sigue un flujo de trabajo sencillo, como se ilustra en la figura 1. Los archivos históricos de periódicos—almacenados como contenido original en una CDN o sistema de archivos—se procesan a través del último model multimodal de Voyage AI, que genera 1024-dimensional vector embeddings tanto a partir de texto como de imágenes. MongoDB almacena estas incrustaciones junto con los metadatos en un modelo orientado a documentos unificado, lo que elimina la complejidad de sincronización de los almacenes de vectores separados.
Cuando un investigador consulta "debates sobre el transporte público desde la década de 1970 hasta la de 1990", el sistema procesa esa pregunta en un vector semántico utilizando el mismo modelo voyage-multimodal-3.5. La búsqueda vectorial de MongoDB compara este vector de query con millones de incrustaciones archivadas, recuperando artículos, gráficos e imágenes relevantes basados en la similitud conceptual en un espacio de alta dimensión, no en la coincidencia de palabras clave. Los resultados se clasifican por relevancia semántica y muestran contenido que comparte significado incluso cuando los términos exactos difieren.
La etapa final permite la agregación y la exploración: los investigadores pueden analizar patrones de frecuencia a lo largo del tiempo, segmentar los resultados por fecha de publicación o tipo de sección y crear visualizaciones estadísticas a partir de los resultados clasificados. El marco de agregación de MongoDB puede ayudar a gestionar esta capa analítica: fácil e intuitiva de implementar, potente para agregar valor incremental a los datos recuperados.
Los nodos de búsqueda dedicados de MongoDB proporcionan aislamiento de cargas de trabajo, escalando la infraestructura de búsqueda vectorial de forma independiente de las cargas operativas de bases de datos. Cuando existen metadatos estructurados —fechas de publicación, etiquetas de sección u otros atributos catalogados— la búsqueda híbrida de MongoDB combina similitud semántica con filtros tradicionales en una sola query, refinando los resultados sin sacrificar el poder semántico.
Hoja de ruta para líderes de TI
Comenzar con una colección piloto de 10,000 a 20,000 páginas tiene sentido, pero los criterios de selección importan más que el volumen. Las colecciones deben abarcar diversos tipos de contenido: artículos, anuncios, gráficas, infografías y, potencialmente, video. El objetivo es validar si los model multimodal y la búsqueda vectorial pueden presentar con precisión tanto contenido textual como visual mediante queries semánticas.
Métricas de éxito que merece la pena rastrear: recall de recuperación superior al 90 % en todos los Content-Type, reducción de los costos de mano de obra manual, aceleración de los flujos de trabajo de investigación y aumentos medibles en la interacción con el fichero. Las oportunidades de ganancia a través de licencias de API y la monetización de activos visuales son indicadores secundarios: dependen primero de demostrar el valor de la investigación.
La cuestión estratégica no es si modernizar los ficheros. Depende de si su organización ve los archivos como colecciones estáticas que deben preservarse, o como sistemas de conocimiento dinámicos que pueden generar valor continuo. La IA multimodal y la búsqueda vectorial permiten lo último, pero solo si la infraestructura subyacente soporta flujos de trabajo analíticos, no solo la recuperación.
Esta no es una mejora incremental. Es un cambio de categoría en lo que pueden hacer los ficheros digitalizados.
Próximos pasos
Visite la página web de medios y entretenimiento y obtenga más información sobre el rol de MongoDB en la industria de los medios.
Lea el blog voyage-multimodal-3 para aprender cómo Voyage AI habilita incrustaciones para text, imágenes y capturas de pantalla.
Explore la MongoDB Solutions Library para descubrir las mejores prácticas, plantillas listas para usar y orientación de expertos para crear aplicaciones potentes.
Descubre cómo las empresas han innovado con MongoDB con estas historias de éxito de clientes.