A digitalização deveria resolver o problema dos arquivos. Escaneie as páginas, execute o reconhecimento ótico de caracteres (OCR), habilite a pesquisa por palavra-chave — pronto. No entanto, décadas e milhões de dólares depois, a maioria dos arquivos de jornais permanece essencialmente inutilizável para pesquisas sérias.
Considere um grande jornal dos EUA com todas as edições publicadas digitalizadas e disponíveis para os assinantes. Para os pesquisadores que procuram tendências históricas dos preços das matérias-primas, a digitalização não mudou quase nada — eles ainda estão folheando milhares de edições manualmente. O gargalo não é a preservação — é a recuperação.
O OCR tem dificuldades previsíveis com papel de imprensa antigo: papel degradado, tipos de fonte incomuns, layouts complexos. Mas a questão mais profunda é o que o OCR nunca foi projetado para lidar: o significado incorporado em gráficos, grafos e visualizações de dados. Esses artefatos visuais — frequentemente o conteúdo de maior valor analítico — permanecem completamente invisíveis para os sistemas de pesquisa.
Museus e arquivos em todo o mundo relatam padrões semelhantes. Uma instituição alcançou uma precisão de OCR quase perfeita por meio de scanners de mesa, suportes especializados e processos exaustivos de controle de qualidade. No entanto, o problema fundamental persiste: a pesquisa por palavra-chave não pode fornecer a riqueza semântica necessária para análise longitudinal, identificação de tendências ou pesquisa comparativa ao longo de décadas.
O avanço da IA multimodal
A mudança do OCR com pesquisa para vector embeddings multimodais representa algo mais fundamental do que a precisão aprimorada. É um model diferente do que "pesquisável" significa.
voyage-multimodal-3.5 (que foi lançada na semana passada!) interpreta texto e imagens diretamente de digitalizações, mapeando páginas inteiras em vetores semânticos densos. Por exemplo, voyage-multimodal-3.5 efetivamente vetoriza dados multimodais para melhor capturar os principais recursos semânticos de tabelas, gráficos, figuras, slides, PDFs e muito mais. Isso permite consultas por significado, contexto ou conceito visual, não apenas correspondências exatas de palavras-chave. Acima de tudo, esses model entendem o conteúdo semântico das visualizações estatísticas, exibindo gráficos econômicos para consultas como "tendências de inflação na década de 1970" mesmo quando não existe text explicativo.
As implicações se estendem além da recuperação. Pela primeira vez, os arquivos se tornam datasets que você pode realmente analisar. Os pesquisadores podem medir como a cobertura da energia nuclear evoluiu do debate político ao consenso científico — e identificar se essas mudanças apareceram primeiro em editoriais ou reportagens investigativas. Eles podem acompanhar como o uso de gráficos econômicos mudou década a década, ou como a energia renovável passou de menções periféricas para o domínio da primeira página.
Esta não é apenas uma pesquisa melhor. É a diferença entre uma coleção estática e uma infraestrutura de pesquisa.
Pesquisa semântica em escala
O MongoDB Atlas Vector Search com o model multimodal-3 da Voyage AI possibilita responder a perguntas de pesquisa que a busca tradicional por palavras-chave não consegue responder. Em vez de encontrar onde a "energia renovável" aparece, os pesquisadores podem descobrir como o tratamento visual e textual do tópico evoluiu ao longo de décadas. Eles podem comparar a cobertura da primeira página com os comentários editoriais, acompanhar a introdução de visualizações de dados e identificar mudanças no enquadramento.
Figura 1. Arquitetura de referência para pesquisa em arquivos históricos.
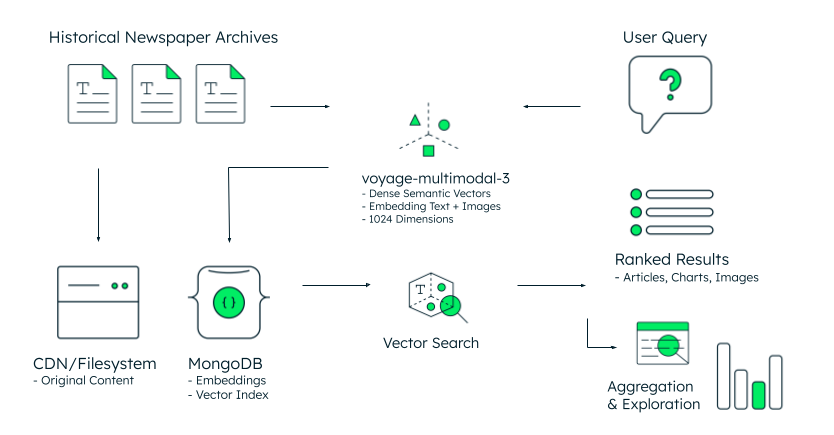
A arquitetura segue um fluxo de trabalho simples, conforme ilustrado na Figura 1. Os arquivos históricos de notícias, armazenados como conteúdo original em um CDN ou sistema de arquivos, são processados por meio do mais recente model multimodal da Voyage AI, que gera 1024-dimensional vector embeddings a partir de texto e imagens. O MongoDB armazena essas embeddings com os metadados em um document model unificado, eliminando a complexidade de sincronização de armazenamentos vetoriais separados.
Quando um pesquisador consulta "debates sobre transporte público dos anos 1970 até os anos 1990", o sistema processa essa pergunta em um vetor semântico usando o mesmo modelo voyage-multimodal-3.5. A pesquisa vetorial do MongoDB compara esse vetor de consulta com milhões de incorporações arquivadas, recuperando artigos, gráficos e imagens relevantes com base na semelhança conceitual em espaço de alta dimensão — não na correspondência de palavras-chave. Os resultados são retornados classificados por relevância semântica, exibindo conteúdo que compartilha o significado mesmo quando os termos exatos diferem.
O estágio final habilita a agregação e exploração: os pesquisadores podem analisar padrões de frequência ao longo do tempo, segmentar os resultados por data de publicação ou tipo de seção e criar visualizações estatísticas a partir dos resultados classificados. A framework de agregação do MongoDB pode ajudar a lidar com essa camada analítica – fácil e intuitiva de implementar, poderosa para adicionar valor incremental aos dados recuperados.
Os nós de pesquisa dedicados do MongoDB fornecem isolamento de carga de trabalho, dimensionamento da infraestrutura de pesquisa vetorial independentemente das cargas do banco de dados operacional. Quando existem metadados estruturados — datas de publicação, etiquetas de seção ou outros atributos catálogos — a pesquisa híbrida do MongoDB combina similaridade semântica com filtros tradicionais em uma única consulta, refinando os resultados sem sacrificar o poder semântico.
Roteiro para líderes de TI
Começar com uma coleção teste de 10.000–20.000 páginas faz sentido — mas os critérios de seleção importam mais do que o volume. As coleções devem abranger diversos tipos de conteúdo: artigos, anúncios, gráficos, infográficos e potencialmente vídeo. O objetivo é validar se os modelos multimodais e a pesquisa vetorial podem revelar com precisão tanto o conteúdo textual quanto visual por meio de consultas semânticas.
Métricas de sucesso que valem a pena acompanhar: recall de recuperação acima de 90% em todos os tipos de conteúdo, redução nos custos de trabalho manual, aceleração dos fluxos de trabalho de pesquisa e aumentos mensuráveis no engajamento dos arquivos. As oportunidades de receita por meio do licenciamento de API e da monetização de ativos visuais são indicadores secundários — eles dependem de comprovar o valor da pesquisa.
A questão estratégica não é modernizar os arquivos. É se a sua organização vê os arquivos como coleções estáticas a serem preservadas, ou como sistemas de conhecimento dinâmicos que podem gerar valor contínuo. A IA multimodal e a pesquisa vetorial permitem isso, mas somente se a infraestrutura ao redor oferecer suporte a fluxos de trabalho analíticos, não apenas à recuperação.
Esta não é uma melhoria incremental. É uma mudança de categoria no que os arquivos digitalizados podem fazer.
Próximos passos
Acesse a página de mídia e entretenimento e aprenda mais sobre a função do MongoDB no setor da mídia.
Leia o blog Voyage-multimodal-3 para aprender como a Voyage AI habilita embeddings para text, imagens e capturas de tela.
Explore a MongoDB Solutions Library para descobrir as melhores práticas, modelos prontos para uso e orientações especializadas para construir aplicações poderosas.
Saiba como as empresas inovaram com o MongoDB com estas histórias de sucesso do cliente.