Den Weg zur behördlichen Zulassung neu überdenken
Ein klinischer Studienbericht (Clinical Study Report, CSR) spielt eine entscheidende Rolle im Entwicklungsprozess für jedes neue Medikament. Er dient als umfassendes Dokument, das die Methodik, Durchführung, Ergebnisse und Analysen einer klinischen Studie dokumentiert. Der Hauptzweck des Berichts besteht darin, einen detaillierten Überblick über die medizinische Studie zu geben, damit Aufsichtsbehörden, Fachkräfte im Gesundheitswesen und andere Interessengruppen wie Forscher und Rechtsteams die Wirksamkeit und Sicherheit eines neuen Arzneimittels beurteilen können.
Skov erklärt den Zeit- und Arbeitsaufwand für die Erstellung eines klinischen Studienberichts und sagt: „Ein CSR benötigt in der Regel etwa 12 Wochen zur Erstellung und erfordert die Mitarbeit eines multidisziplinären Teams aus Statistikern, Wissenschaftlern und Fachautoren. Jeder Tag der Verzögerung bedeutet, dass die Patienten nicht die benötigten Behandlungen erhalten und das Unternehmen nicht mit der Amortisierung seiner Forschungs- und Entwicklungskosten beginnen kann.“
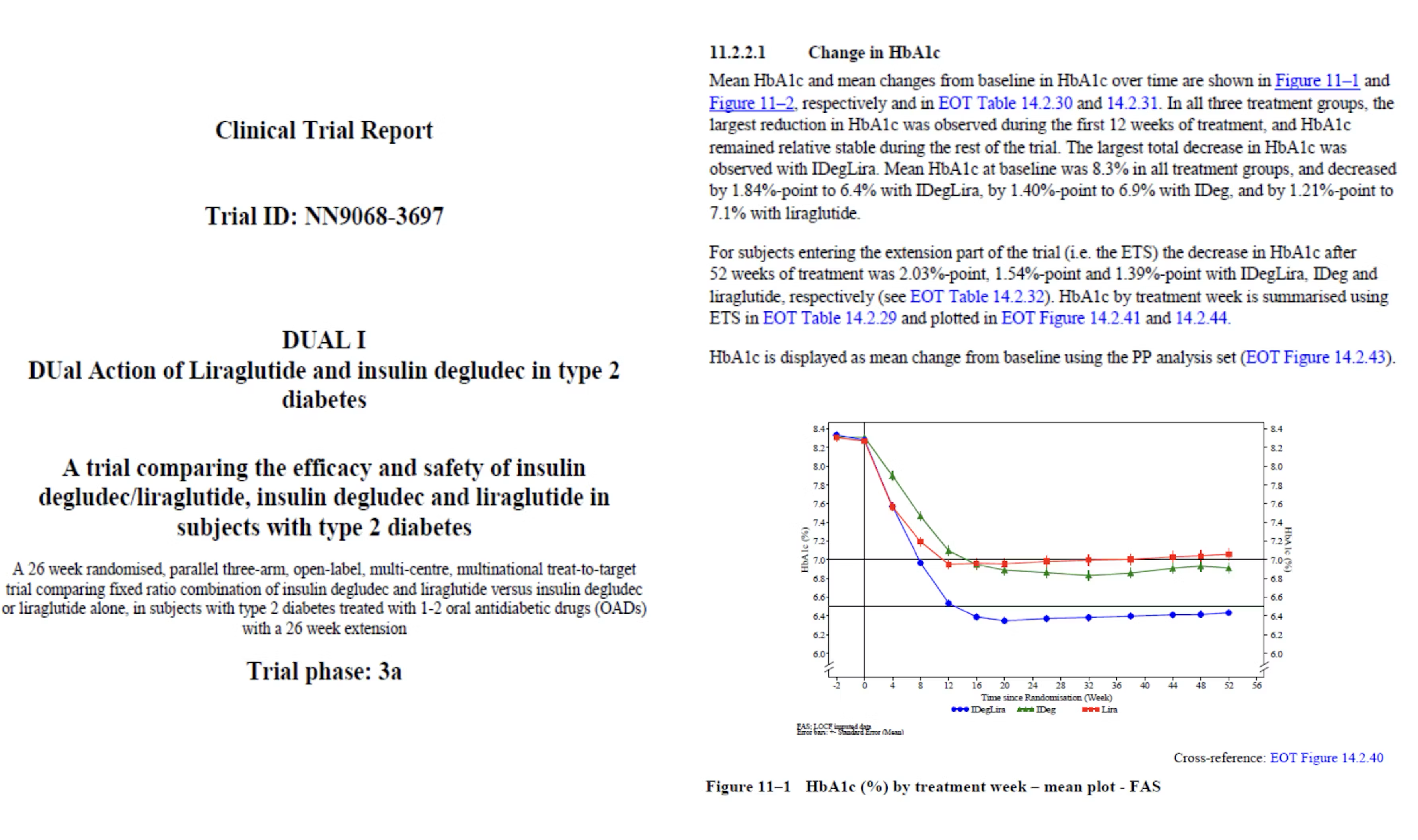
Der Prozess beginnt mit der statistischen Analyse der vor Ort gesammelten Daten aus klinischen Studien, woraus Tabellen, Grafiken und andere Ergebnisse erstellt werden. Fachautoren extrahieren dann diese Daten und integrieren sie in die Berichtsvorlagen, die für die Einreichung bei den Regulierungsbehörden verwendet werden. Um sicherzustellen, dass alle Daten im über 100-seitigen Bericht konsistent, umfassend und den regulatorischen Standards entsprechend sind, sind umfangreiche Qualitätssicherungsprozesse erforderlich.
Mit der Einführung von generativer KI erkannte Skovs Team bei Novo Nordisk die Möglichkeit, die Effizienz bei der Erstellung von CSRs erheblich zu steigern. Und so entstand NovoScribe.
NovoScribe: Auf einem soliden Fundament von Amazon Bedrock, LangChain und MongoDB Atlas Vector Search aufgebaut
Mit dem Start des Projekts Mitte 2023 hat das Team von Skov seinen Arbeitsablauf mit NovoScribe neu gestaltet. Es experimentierte mit der dynamischen Erstellung des CSR, indem es die Retrieval Augmented Generation nutzte, um modernste Large Language Models (LLMs) sowohl mit statistischen Ergebnissen aus klinischen Studien als auch mit Vektoreinbettungen von Berichtsvorlagen zu versorgen.
Innerhalb weniger Wochen erwiesen sich die Experimente als erfolgreich. NovoScribe erstellte CSRs schneller und präziser und benötigte weniger Ressourcen als die vorherigen manuellen Methoden. NovoScribe war bereit für den Einsatz.
Tobias Kröpelin, Tech Lead für NovoScribe und Statistical Programming Specialist bei Novo Nordisk, erklärt den generativen KI-Stack, der NovoScribe unterstützt. „Jedes Foundation-Modell hat seine eigenen Stärken und Schwächen. Daher experimentieren wir in der Regel mit einer Vielzahl verschiedener Einbettungs- und Generierungsmodelle für jeden Bericht, den wir erstellen.“
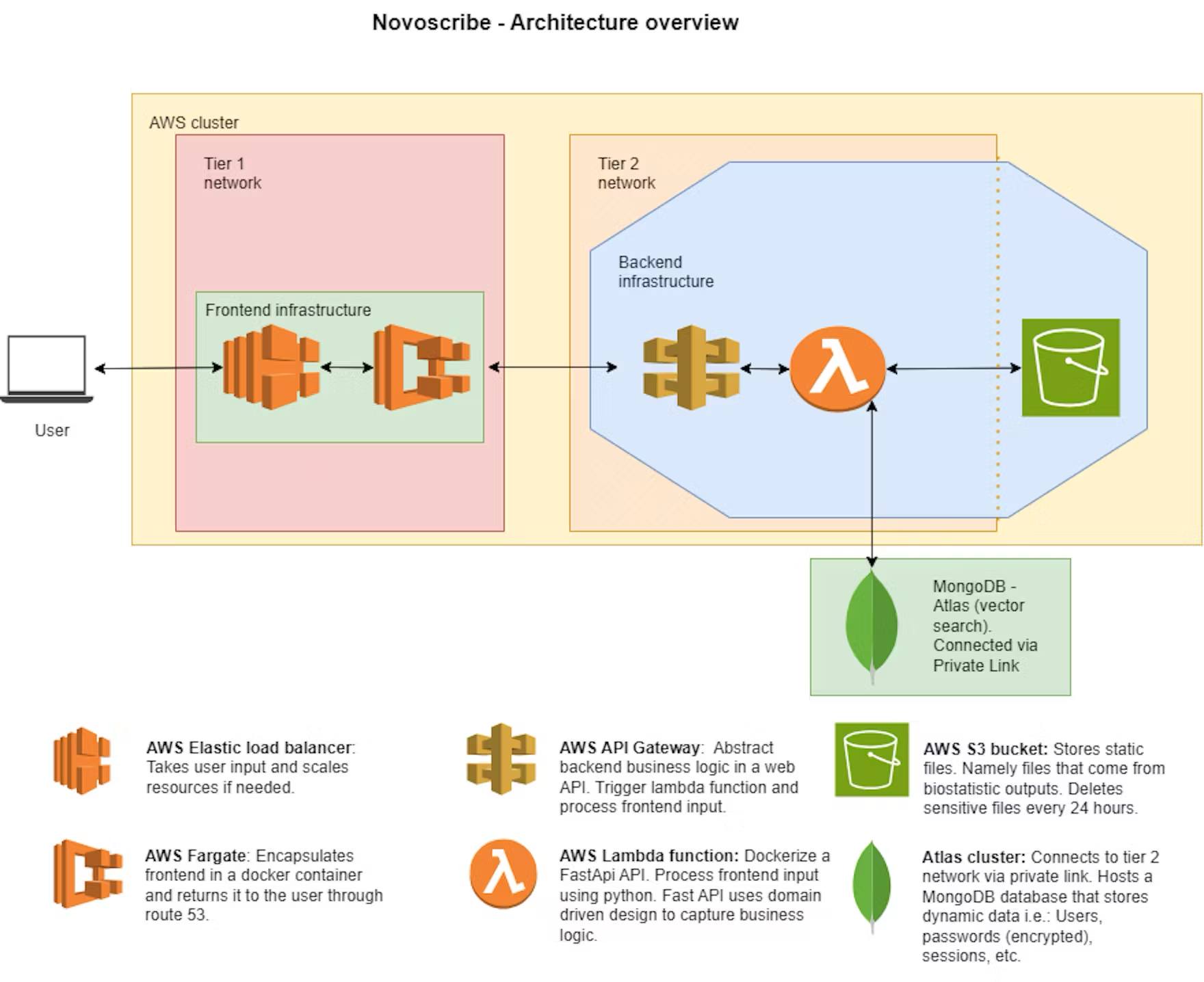
NovoScribe nutzt die von Amazon Bedrock gehosteten Foundation-Modelle Claude 3 und Titan sowie die firmeneigene private Instanz von ChatGPT. Mit dem Entwicklungs- und Orchestrierungs-Framework LangChain kann das Team schnell und einfach zwischen Modellen wechseln, ohne den Anwendungscode ändern zu müssen. Mithilfe von Retrieval Augmented Generation (RAG) werden die Modelle mit Berichtsdaten und Vektoreinbettungen versorgt, die von MongoDB Atlas Vector Search verwaltet werden.
NovoScribe generiert validierten Text basierend auf definierten Inhaltsregeln und statistischen Ausgaben. Atlas Vector Search berechnet die Ähnlichkeit jedes Textausschnitts mit den relevanten Statistiken. In Kombination mit den LLM-Ausgaben wird der CSR erstellt. Durch die Nutzung von Atlas Vector Search wird der relevante Text mit hoher Präzision und Genauigkeit ausgewählt. Die vollständige Herkunft aller Quellen wird angegeben, sodass die Autoren die Genauigkeit verifizieren können, wodurch wochenlange Schreib- und Überarbeitungsprozesse entfallen.
„Das Besondere an MongoDB Atlas ist, dass wir native Vektoreinbettungen des Berichts direkt neben allen zugehörigen Textausschnitten und Metadaten speichern können“, erklärt Kröpelin. „So können wir sehr leistungsstarke und komplexe Abfragen schnell ausführen. Für jede Vektoreinbettung können wir filtern, aus welchem Quelldokument sie stammt, wer sie verfasst hat und wann sie erstellt wurde.“



.svg)