Réimaginer le chemin vers l'approbation réglementaire
Un rapport d’étude clinique (CSR) joue un rôle crucial dans le processus de développement de tout nouveau médicament. Il s’agit d’un document exhaustif qui présente la méthodologie, l’exécution, les résultats et les analyses d’un essai clinique. L’objectif principal du rapport est de fournir un compte rendu détaillé de l’essai clinique, qui permet aux autorités réglementaires, aux professionnels de santé et aux autres parties prenantes, telles que les chercheurs et les équipes juridiques, d’évaluer l’efficacité et la sécurité d’un nouveau produit pharmaceutique.
Décrivant les efforts et le temps nécessaires à la production d’un rapport d’étude clinique, Louise Lind Skov déclare : « La production d’un rapport d’étude clinique (CSR) prend généralement environ 12 semaines, impliquant une équipe multidisciplinaire de statisticiens, de scientifiques et de rédacteurs techniques. Chaque jour de retard signifie que les patients ne reçoivent pas les traitements dont ils ont besoin et que l’entreprise ne peut pas commencer à récupérer ses coûts de R&D. »
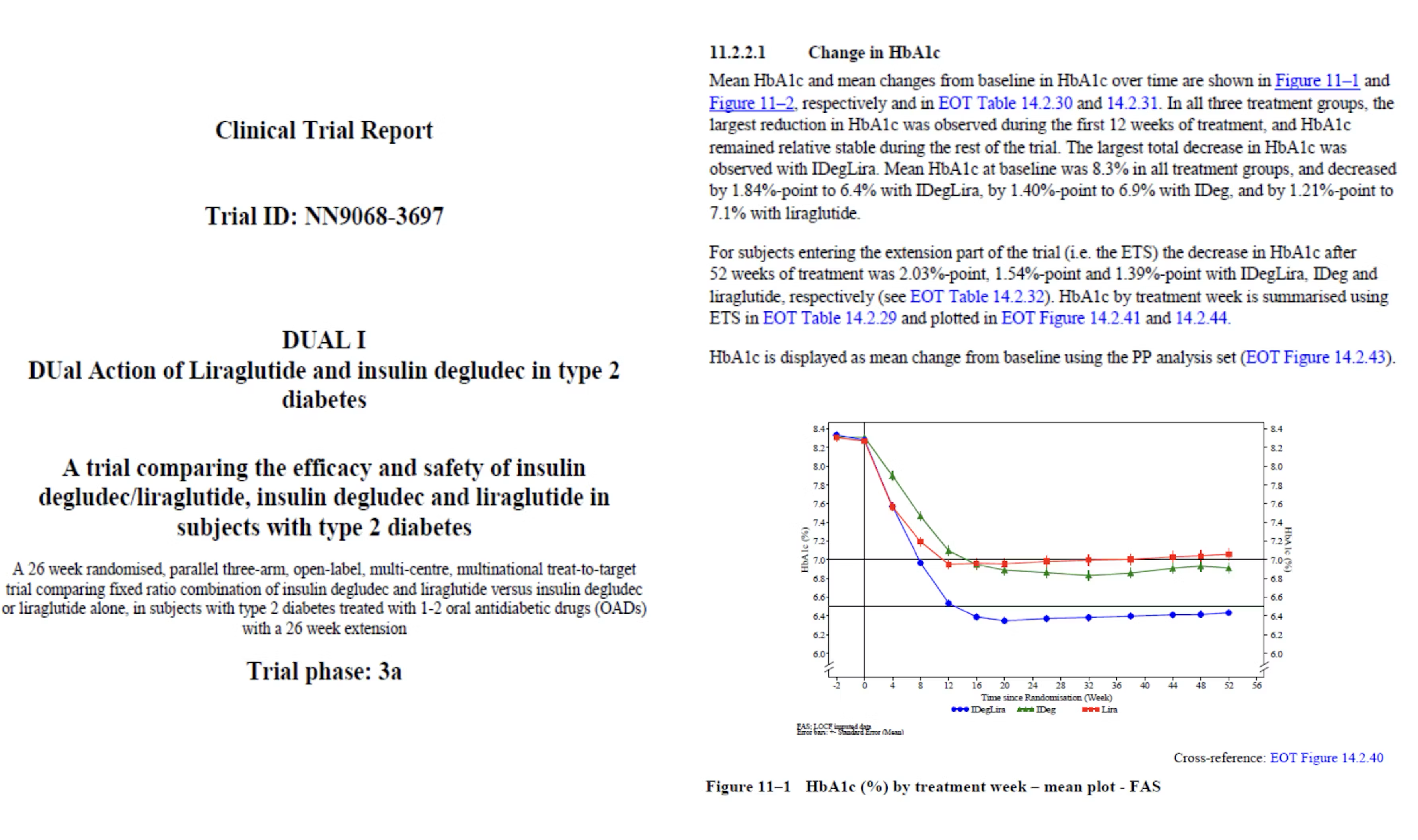
Le processus débute par l’analyse statistique des données d’essais cliniques recueillies sur le terrain, produisant des résultats tels que des tableaux et des graphiques. Les rédacteurs techniques extraient puis fusionnent ces données avec les modèles de rapport utilisés dans la soumission réglementaire. Des processus d’assurance qualité approfondis sont nécessaires pour garantir que toutes les données du rapport de plus de 100 pages sont cohérentes, complètes et conformes aux normes réglementaires.
L’arrivée de l’IA générative a offert à l’équipe de Mme Skov de Novo Nordisk l’opportunité de réaliser des gains d’efficacité significatifs dans la production de CSR. C’est ainsi qu’est né NovoScribe.
NovoScribe : construit sur une base solide d'Amazon Bedrock, de LangChain et de MongoDB Atlas Vector Search
Dans le cadre du lancement du projet NovoScribe à la mi-2023 l’équipe de Louise Lind Skov a dû entièrement repenser son workflow. Tirant parti de la génération augmentée par récupération pour expérimenter la compilation dynamique du CSR, l’équipe a mis au point des grands modèles de langage (LLM) de pointe exploitant à la fois les résultats statistiques des essais cliniques et les embeddings vectoriels des modèles de rapport.
Les expériences se sont révélées fructueuses en quelques semaines. NovoScribe a produit des CSR plus rapidement et avec plus de précision, nécessitant moins de ressources que les méthodes manuelles précédentes. NovoScribe était prêt pour une utilisation en masse.
Tobias Kröpelin, responsable technique de NovoScribe et spécialiste de la programmation statistique chez Novo Nordisk, explique la pile d'IA générative qui alimente NovoScribe. « Chaque modèle de base a ses propres forces et faiblesses, c'est pourquoi nous expérimentons généralement avec une variété de modèles d'intégration et de génération pour chaque rapport que nous compilons. »
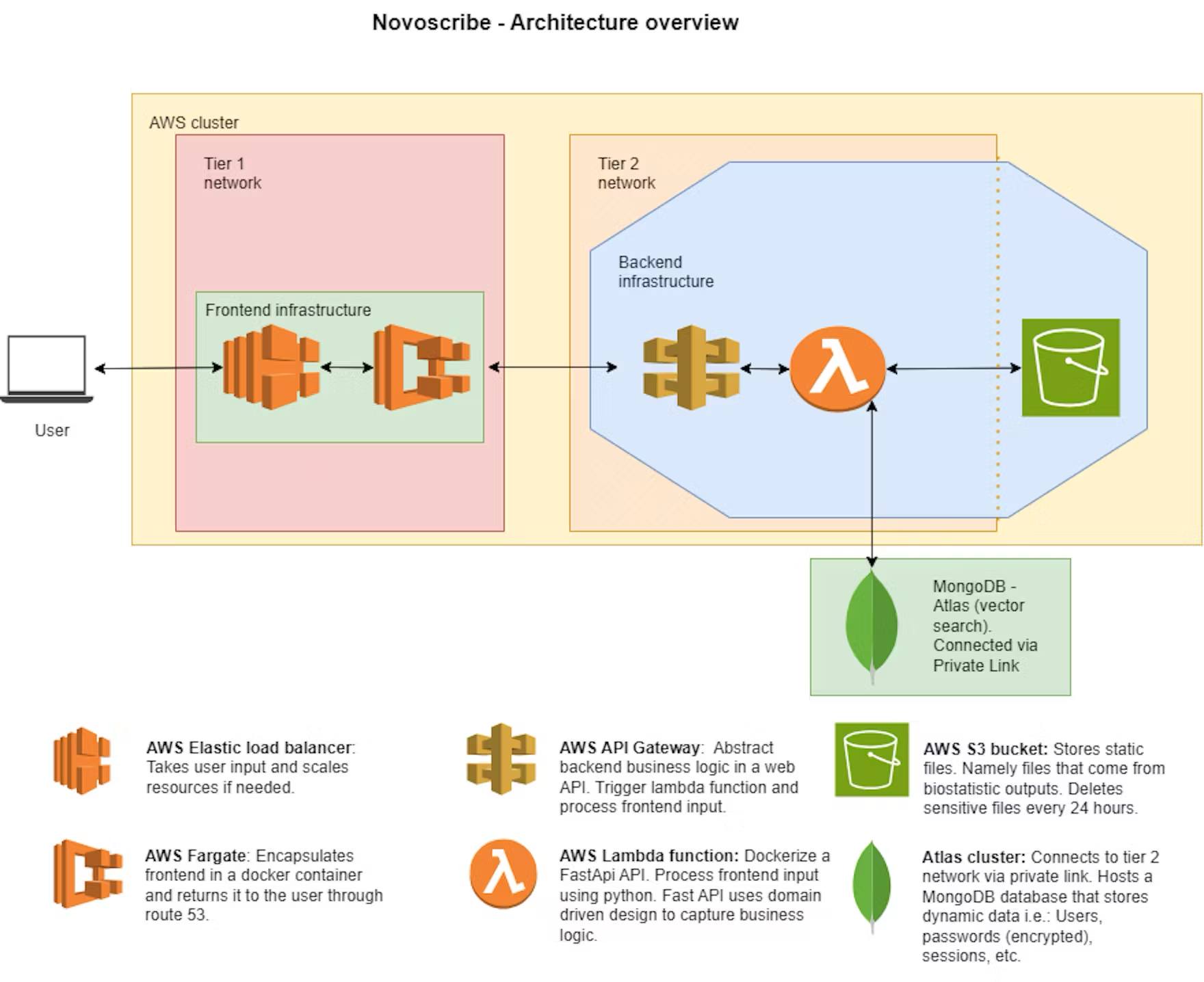
NovoScribe utilise les modèles de fondation Claude 3 et Titan hébergés par Amazon Bedrock, ainsi que sa propre instance privée de ChatGPT. Grâce au framework de développement et d’orchestration LangChain, l’équipe peut passer d’un modèle à l’autre rapidement et facilement, sans avoir à modifier le code de l’application. Grâce à la RAG, les modèles sont alimentés par des données de rapport et des embeddings vectoriels gérés par MongoDB Atlas Vector Search.
NovoScribe génère des textes validés selon des règles de contenu définies et des résultats statistiques, tandis qu’Atlas Vector Search calcule la similarité de chaque extrait de texte avec les statistiques correspondantes. Le tout, combiné à la sortie préliminaire du CSR, constitue le LLM. L’utilisation d’Atlas Vector Search assure une sélection du texte pertinent de manière extrêmement précise. La lignée complète de toutes les sources est présentée, permettant aux auteurs de vérifier l’exactitude et d’éviter des semaines de rédaction et de révisions.
« Ce qui est formidable avec MongoDB Atlas, c’est que nous pouvons stocker des embeddings vectoriels natifs du rapport directement avec tous leurs extraits de texte et métadonnées associés », déclare M. Kröpelin. « Nous pouvons ainsi exécuter des requêtes très puissantes et complexes rapidement. Pour chaque embedding vectoriel, nous pouvons filtrer en fonction du document source dont il provient, qui l’a rédigé et quand. »



.svg)