Reimaginando el camino hacia la aprobación regulatoria
Un informe de estudio clínico (CSR) desempeña un papel fundamental en el proceso de desarrollo de cualquier nuevo medicamento. Sirve como un documento exhaustivo que recoge la metodología, la ejecución, los resultados y los análisis de un ensayo clínico. El propósito principal del informe es ofrecer un relato detallado del ensayo médico, asegurando que las autoridades reguladoras, los profesionales de la salud y otras partes interesadas, como investigadores y equipos legales, puedan evaluar la eficacia y seguridad de un nuevo producto farmacéutico.
Al explicar el tiempo y el esfuerzo necesarios para producir un informe de estudio clínico, Skov dice: «Por lo general, un CSR tarda alrededor de 12 semanas en compilarse, involucrando a un equipo multidisciplinario de estadísticos, científicos y autores técnicos». "Cada día de retraso significa que los pacientes no reciben los tratamientos que necesitan y la empresa no puede comenzar a recuperar sus costos de I+D”
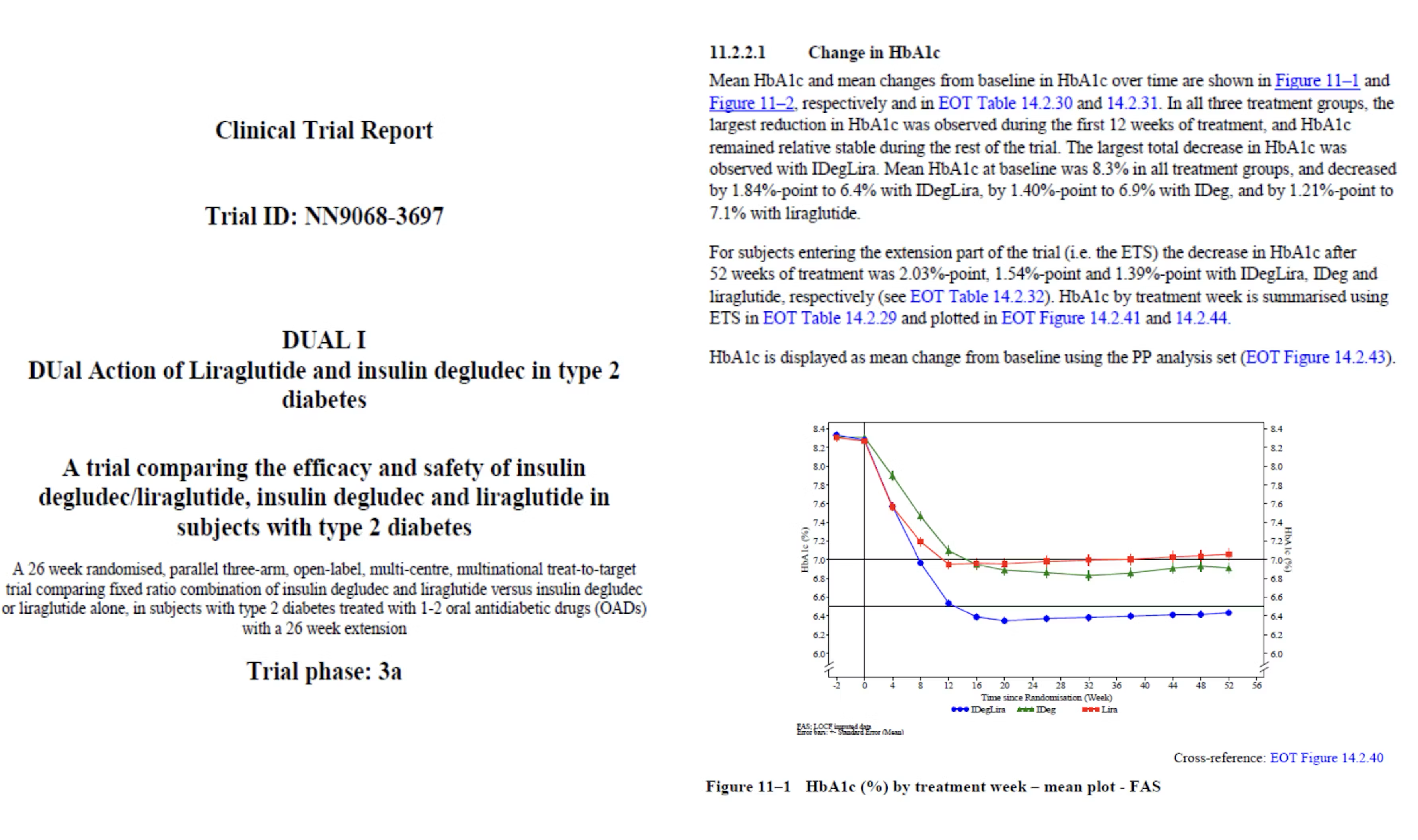
El proceso comienza con el análisis estadístico de los datos de los ensayos clínicos recopilados en el campo, creando resultados como tablas y figuras. Luego, los autores técnicos extraen y fusionan estos datos con las plantillas de informes que se utilizan en la presentación regulatoria. Se requieren procesos exhaustivos de aseguramiento de calidad (QA) para asegurar que todos los datos en el informe de más de 100 páginas sean consistentes, completos y cumplan con los estándares regulatorios.
Con la llegada de la IA generativa, el equipo de Skov en Novo Nordisk vio la oportunidad de impulsar eficiencias significativas en la producción de informes de responsabilidad corporativa (CSRs). Y así nació NovoScribe.
NovoScribe: construido sobre una base sólida de Amazon Bedrock, LangChain y MongoDB Atlas Vector Search
Al iniciar el proyecto a mediados de 2023, el equipo de Skov reimaginó su flujo de trabajo con NovoScribe. Experimentaron con la compilación dinámica del CSR aprovechando la generación aumentada de recuperación para activar modelos de lenguaje de gran tamaño (LLM) de última generación utilizando tanto los resultados estadísticos de los ensayos clínicos como las incrustaciones vectoriales de las plantillas de informes.
En unas pocas semanas, los experimentos demostraron ser exitosos. NovoScribe produjo CSRs de forma más rápida y precisa, y requirió menos recursos que los métodos manuales anteriores. NovoScribe estaba listo para el momento de máxima audiencia.
Tobias Kröpelin, líder técnico de NovoScribe y especialista en programación estadística en Novo Nordisk, explica la pila de IA generativa que impulsa NovoScribe. «Cada modelo de base tiene sus propias fortalezas y debilidades, por lo que normalmente experimentamos con una variedad de modelos de incrustación y generación para cada informe que compilamos»
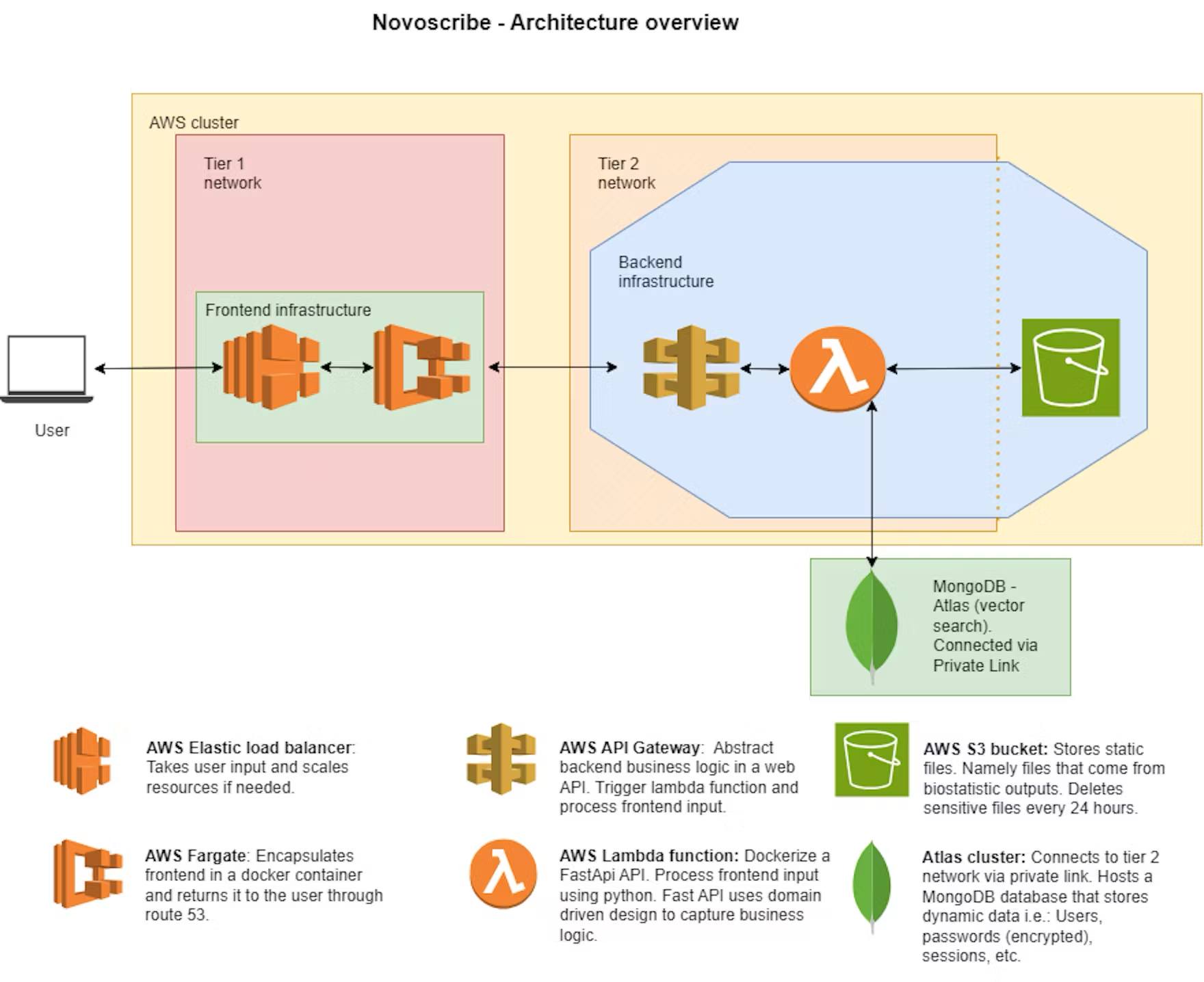
NovoScribe utiliza los modelos de base Claude 3 y Titan alojados por Amazon Bedrock, junto con la propia instancia privada de ChatGPT de la empresa. Con el marco de desarrollo y orquestación LangChain, el equipo puede cambiar entre modelos de forma rápida y sencilla, sin tener que cambiar ningún código de aplicación. Usando RAG, los modelos se sirven con datos de informes e incrustaciones vectoriales gestionadas por MongoDB Atlas Vector Search.
NovoScribe genera texto validado basado en reglas de contenido definidas y resultados estadísticos. Atlas Vector Search calcula la similitud de cada fragmento de texto con las estadísticas relevantes. Esto, combinado con el borrador de salida del LLM, redacta el CSR. Al utilizar Atlas Vector Search, el texto relevante se selecciona con un alto grado de precisión y exactitud. Se presenta el linaje completo de todas las fuentes, lo que permite a los autores verificar la precisión, eliminando semanas de escritura y revisiones.
«Lo mejor de MongoDB Atlas es que podemos almacenar incrustaciones vectoriales nativas del informe junto con todos sus fragmentos de texto y metadatos asociados», dice Kröpelin "Esto significa que podemos ejecutar consultas muy potentes y complejas de manera rápida Para cada incrustación vectorial, podemos filtrar sobre de qué documento de origen proviene, quién lo escribió y cuándo.



.svg)