重新构想通往监管批准的路径
临床研究报告(CSR)在任何新药研发进程中都起着举足轻重的作用。这份综合性文档记录了临床试验的方法、实施情况、研究成果和分析结论。报告的主要目的是说明医学试验的详细情况,确保监管机构、医务人员和其他利益相关者(如研究人员和法律团队)能够评估新药的有效性和安全性。
在解释编写临床研究报告所需的时间和精力时,Skov 说道:“一份 CSR 的编写通常需要大约 12 周的时间,需要由统计学家、科研人员和技术作者组成的多学科团队共同完成。每延迟一天,就意味着患者无法得到所需的治疗,公司也无法开始收回其研发成本。”
该流程的第一步是对在字段中收集的临床试验数据进行统计分析,创建表格和图形等输出文档。然后,技术作者将这些数据提取出来,并与监管报批文件中使用的报告模板进行整合。为确保这份长达 100 多页的报告中所有数据的一致性、完整性且符合监管标准,必须实施全面的质量保证 (QA) 流程。
随着生成式人工智能的到来,Novo Nordisk 的 Skov 团队看到了在撰写 CSR 报告方面显著提高效率的机会。因此,NovoScribe 诞生了。
NovoScribe:基于 Amazon Bedrock、LangChain 和 MongoDB Atlas Vector Search 的坚实基础构建
Skov 的团队在 2023 年年中启动了该项目,并使用 NovoScribe 重新设计了其工作流程。他们尝试利用 RAG 动态编译 CSR,以使用临床试验的统计输出结果和报告模板的向量嵌入来驱动最先进的大型语言模型 (LLM)。
短短数周内,实验即取得成功。NovoScribe 生成 CSR 的速度更快,准确度更高,而且所需资源较传统人工方法更少。NovoScribe 已经具备了商业化应用的条件。
NovoScribe 技术主管兼统计编程专家 Tobias Kröpelin 解释了为 NovoScribe 提供技术支持的生成式人工智能堆栈。“每个基础模型都有其优缺点,因此我们通常会针对编写的每份报告尝试各种不同的嵌入和生成模型。”
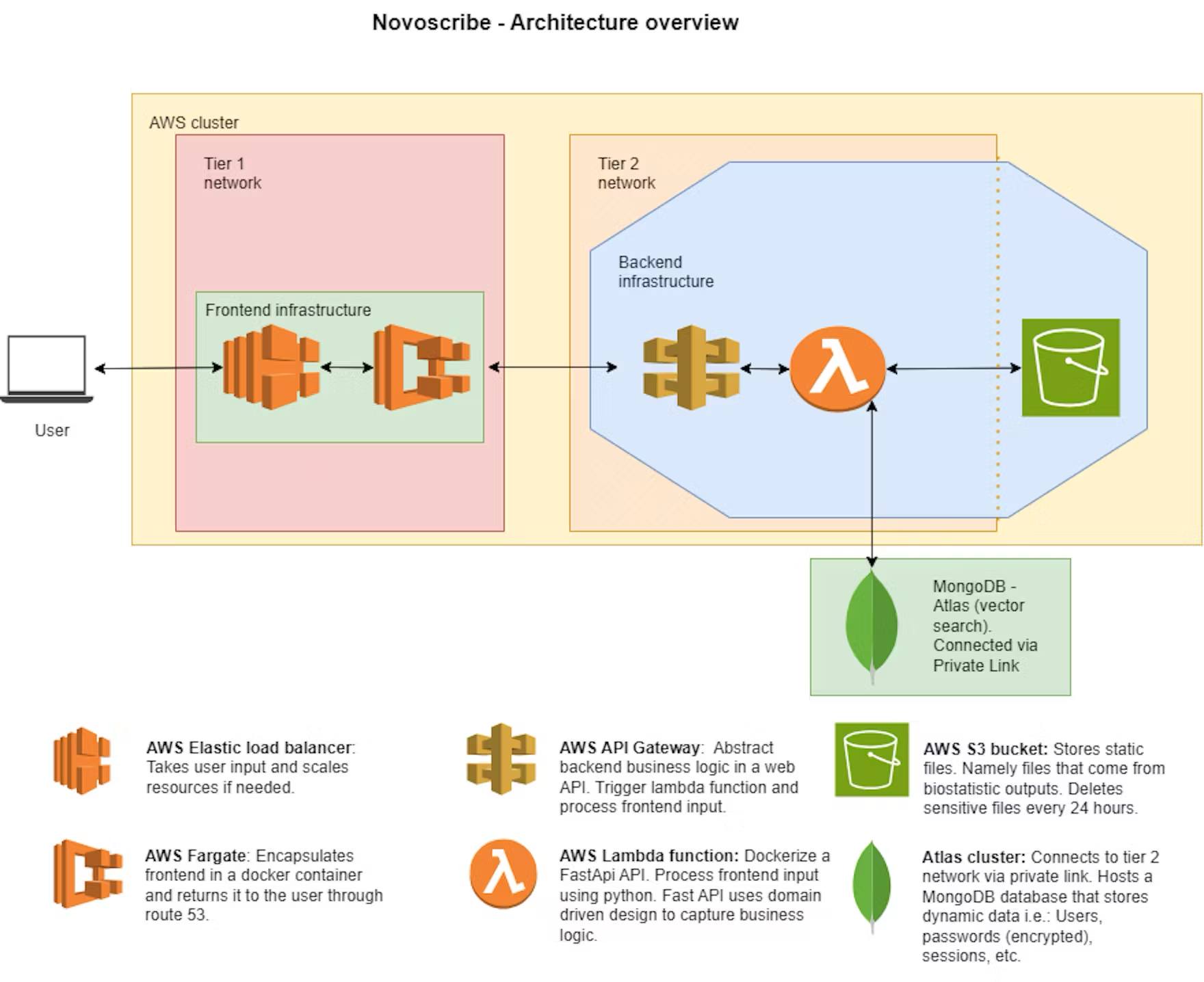
NovoScribe 使用由 Amazon Bedrock 托管的 Claude 3 和 Titan 基础模型,以及该公司自己的 ChatGPT 私有实例。借助 LangChain 开发及编排框架,该团队可以快速轻松地在模型之间切换,而无需更改任何应用程序代码。基于 RAG,模型所获取的数据源包括 MongoDB Atlas Vector Search 管理的报告数据和向量嵌入。
NovoScribe 根据定义的内容规则及统计输出结果生成已验证文本,而 Atlas Vector Search 计算每个文本代码片段与相关统计数据的相似度。这与 LLM 的输出结果相结合,产生了 CSR 草稿。借助 Atlas Vector Search,系统能够以高精度和准确度筛选相关文本。所有数据来源的完整谱系都已呈现,使报告作者能够验证准确性,从而节省数周的撰写与审校时间。
Kröpelin 表示:“MongoDB Atlas 的最大优势在于,我们可以将报告的原生向量嵌入与所有相关文本代码片段和元数据一起存储。”“这使得我们可以快速运行功能强大且复杂的查询。对于每个向量嵌入,我们可以筛选其来源的源文档、撰写人员及时间。”







.svg)