Die Retrieval Augmented Generation (RAG) ist ein beliebtes Framework für generative KI, das die Fähigkeiten von Large Language Models (LLMs) durch die Einbindung relevanter, aktueller Informationen während des Generierungsprozesses erweitert. Dieser Ansatz ermöglicht es LLMs, ihr vorab erlerntes Wissen durch aktuelle, domänenspezifische Daten zu ergänzen. RAG ist eine kostengünstige Lösung, um ein LLM für spezifische Anwendungsfälle anzupassen, ohne dass das gesamte Modell teuer und zeitaufwendig feinabgestimmt oder neu trainiert werden muss.
Retrieval Augmented Generation für eine intelligentere KI
Retrieval Augmented Generation ermöglicht es Unternehmen, allgemeine große Sprachmodelle für spezialisierte Anwendungen zu nutzen, ohne teure, speziell trainierte Modelle zu benötigen. RAG geht die grundlegenden Einschränkungen dieser Modelle direkt an, indem es Abfragen mit aktuellen, domänenspezifischen Informationen anreichert, um die Generierungsfähigkeiten zu verbessern. Dadurch können Unternehmen Echtzeitinformationen, proprietäre Datensätze und spezielle Dokumentationen einbeziehen, die nicht Teil des ursprünglichen Modelltrainings sind. Durch die transparente Bereitstellung von Nachweisen mit Antworten verbessert RAG das Vertrauen und reduziert das Risiko von Halluzinationen.
Was sind Large Language Models?
LLMs sind eine Form der künstlichen Intelligenz, die darauf ausgelegt ist, menschlich anmutende Texte zu verstehen und zu generieren. Als fortgeschrittene Anwendung der Verarbeitung natürlicher Sprache (NLP) können LLMs Muster, Strukturen und Grammatik aus riesigen Mengen von Trainingsdaten lernen, sodass sie kohärente Antworten auf Benutzeranfragen generieren können. Die Stärke von LLMs liegt in ihrer Fähigkeit, eine Vielzahl von Aufgaben zur Spracherzeugung auszuführen, ohne dass ein aufgabenspezifisches Training erforderlich ist. Dadurch sind sie vielseitige Werkzeuge für Anwendungen wie Chatbots, Übersetzungen, die Erstellung von Inhalten und Zusammenfassungen.
Die Grenzen von Large Language Models
Ein Large Language Model ist ein komplexes neuronales Netz, das durch die Analyse großer Trainingsdatensätze lernt. Diese Modelle erfordern erhebliche Rechenressourcen, was ihre Entwicklung extrem teuer und zeitaufwendig macht. Darüber hinaus stellt die spezialisierte Infrastruktur, die für die Bereitstellung und Wartung benutzerdefinierter LLMs erforderlich ist, eine erhebliche finanzielle Hürde dar, sodass nur gut ausgestattete Unternehmen mit erheblichen technologischen Investitionen darauf zugreifen können.
LLMs sind großartig darin, Fragen zu historischen Inhalten zu beantworten, aber ihr Wissen ist durch die Grenzen ihrer Trainingsdaten eingeschränkt. Dies macht sie weniger effektiv für Anfragen, die aktuelles Wissen erfordern, da sie Anfragen zu aktuellen Ereignissen nicht ohne eine erneute Modellierung beantworten können.
Ebenso können LLMs keine Fragen zu unternehmensinternen Dokumenten oder anderen bereichsspezifischen Datensätzen beantworten, die nur für ein bestimmtes Unternehmen gelten. Diese Einschränkung stellt Unternehmen, die KI-Technologien nutzen möchten, die tiefgreifendes, spezialisiertes Wissen erfordern, das auf ihre Bedürfnisse zugeschnitten ist, vor große Herausforderungen.
Diese Einschränkungen verdeutlichen eine weitere Herausforderung von LLMs: Halluzinationen. Ohne überprüfbare Informationen können Sprachmodelle überzeugende, plausibel klingende, vollständig erfundene Antworten generieren. Diese Tendenz, überzeugende, aber falsche Informationen zu produzieren, birgt erhebliche Risiken für Anwendungen, die Genauigkeit und Zuverlässigkeit erfordern.

Vorteile der Retrieval Augmented Generation
RAG ist aufgrund seiner relativ einfachen Architektur in Verbindung mit erheblichen Leistungsverbesserungen beliebt geworden.
Kosteneffizient
RAG ermöglicht es Unternehmen, vorab trainierte Modelle für allgemeine Zwecke für spezielle Anwendungen zu nutzen, ohne die Kosten für die Entwicklung maßgeschneiderter Modelle tragen zu müssen. Durch eine effektive Abfrage werden die API-Kosten gesenkt, indem sichergestellt wird, dass nur die erforderlichen Informationen enthalten sind, um für LLMs zu optimieren, die pro Token abrechnen.
Domänenanpassung
RAG ermöglicht es Unternehmen, vorab trainierte Modelle durch die Integration spezialisierter Wissensbibliotheken an bestimmte Bereiche anzupassen. Dadurch können Modelle ohne benutzerdefiniertes Modelltraining Antworten zu firmeneigener und branchenspezifischer Dokumentation generieren. Eine Feinabstimmung kann ähnliche Vorteile bieten, erfordert jedoch deutlich mehr Zeit, Kosten und Wartung.
Einblicke in Echtzeit
RAG ermöglicht Large Language Models den Zugriff auf und die Generierung von Antworten unter Verwendung aktueller Informationen, indem es dynamisch aktuelle Daten aus externen Quellen abruft. Dadurch werden die Wissensbeschränkungen statischer Trainingsdatensätze überwunden, sodass Modelle Einblicke in aktuelle Ereignisse und aufkommende Trends bieten können.
Transparenz
RAG verbessert die Zuverlässigkeit der KI-Antworten, indem es Quellenzitate und Belege für generierte Inhalte bereitstellt. Durch die Verknüpfung jeder Antwort mit spezifischen Quellen in der Wissensdatenbank ermöglicht RAG den Benutzern, die Herkunft und Richtigkeit der Informationen zu überprüfen, wodurch das Risiko von Halluzinationen verringert und Vertrauen in KI-generierte Ergebnisse aufgebaut wird.
Anpassungsfähigkeit
Ein entscheidender Vorteil von RAG ist die einfache Anpassungsfähigkeit an neue, hochmoderne Modelle. Wenn es Fortschritte bei Sprachmodellen oder Abruftechniken gibt, können Unternehmen neuere Modelle einführen oder Abrufstrategien ändern, ohne das gesamte System überarbeiten zu müssen. Diese Flexibilität stellt sicher, dass ein RAG-System mit der neuesten Technologie Schritt halten kann.
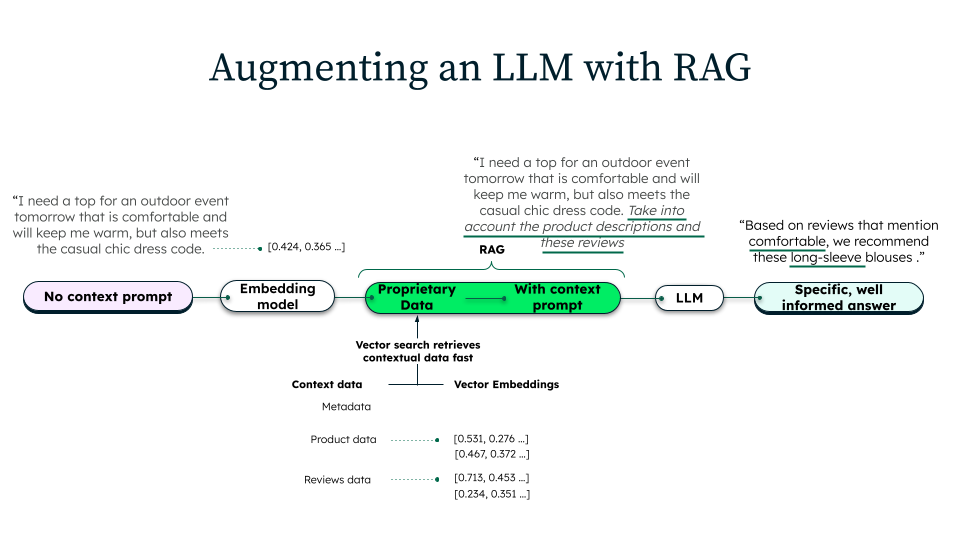
Wie funktioniert Retrieval Augmented Generation?
RAG besteht aus drei verschiedenen Phasen: Aufnahme, Abruf und Erzeugung.
Datenerfassung
Während der Aufnahme bereiten Unternehmen ihre Wissensdatenbank für den Abruf vor. Die Quelldaten werden aus verschiedenen Quellen wie internen Dokumentationen, Datenbanken oder externen Ressourcen zusammengetragen. Diese Dokumente werden dann bereinigt, formatiert und in kleinere, handhabbare Einheiten aufgeteilt. Jeder Abschnitt wird mithilfe eines Einbettungsmodells, das die semantische Bedeutung des Textes erfasst, in eine Vektordarstellung umgewandelt. Diese Vektoren werden in Vektordatenbanken gespeichert, die eine effiziente semantische Suche und Abfrage ermöglichen.
Informationsgewinnung
Wenn ein Benutzer eine Anfrage sendet, ruft das System vor der Generierung den relevanten Kontext ab. Die Abfrage wird in eine Vektordarstellung umgewandelt, wobei dasselbe Einbettungsmodell verwendet wird, das auch bei der Aufnahme verwendet wurde. Die Vektorsuche durchsucht die Datenbank nach den semantisch ähnlichsten Dokumentenblöcken zur Suchanfrage. Zusätzliche Filter-, Ranking- oder Neugewichtungsverfahren können angewendet werden, um sicherzustellen, dass nur die relevantesten Informationen abgerufen werden, wodurch die Genauigkeit der endgültigen Antwort verbessert wird.
Erzeugung
Sobald der relevante Kontext abgerufen wurde, wird eine erweiterte Eingabeaufforderung erstellt, die die ursprüngliche Eingabeaufforderung, dieselben abgerufenen Passagen und spezifische Anweisungen verwendet. Das LLM verarbeitet diese Eingabe, um eine Antwort zu generieren, die sein vorab trainiertes Wissen mit dem abgerufenen Inhalt verknüpft. Dieser Ansatz stellt sicher, dass die Antwort durch externe Datenquellen untermauert und auf die Absicht des Benutzers abgestimmt ist, was zu einer genaueren Antwort führt.
Anwendungsfälle aus der Industrie für die Retrieval Augmented Generation
RAG wird bereits branchenübergreifend eingesetzt, um das transformative Potenzial von Large Language Models und KI zu erschließen.
- Fertigung: Ergänzen Sie LLMs mit Gerätehandbüchern und Wartungsprotokollen, um Echtzeit-Betriebsanleitungen bereitzustellen. RAG ermöglicht Technikern den schnellen Zugriff auf präzise Informationen über Maschinen, wodurch Ausfallzeiten reduziert und die Leistung der Geräte verbessert werden.
- Kundensupport: Nutzen Sie interne Dokumentation, Produktleitfäden und den Supportverlauf, um Probleme zu diagnostizieren. RAG hilft Support-Teams dabei, hilfreiche Inhalte sofort abzurufen, wodurch die Reaktionszeiten verkürzt und die Lösungsraten beim ersten Kontakt verbessert werden, um effizient auf Kundenanfragen zu reagieren.
- Gesundheitswesen: Medizinische Forschung, klinische Richtlinien und Patientenakten werden synthetisiert, um diagnostische Entscheidungen und Behandlungsempfehlungen zu unterstützen. Retrieval Augmented Generation ermöglicht Fachkräften im Gesundheitswesen den Zugriff auf aktuelles medizinisches Wissen und bietet gleichzeitig transparente, evidenzbasierte Einblicke.
- Finanzdienstleistungen: Regulatorische Dokumente, Marktberichte und Compliance-Richtlinien integrieren, um die Anlageforschung, Risikobewertung und Einhaltung gesetzlicher Vorschriften zu unterstützen. RAG ermöglicht es Finanzanalysten, komplexe, aktuelle Finanzinformationen schnell abzurufen und zu analysieren.
- Softwareentwicklung: Überprüfen Sie Dokumentationen und Code-Schnipsel, um Entwickler beim Schreiben von Code zu unterstützen. RAG kann auch beim Debugging helfen, indem es mögliche Lösungen auf der Grundlage ähnlicher Probleme aus der Vergangenheit vorschlägt und so die Produktivität und Qualität verbessert.
Schlüsselkonzepte für die Retrieval Augmented Generation
Chunking
Chunking ist ein Bestandteil des Datenerfassungsprozesses, der die Systemgenauigkeit erhöht und gleichzeitig die Kosten senkt. Dabei werden große Inhaltsblöcke in kleinere, handhabbare Segmente unterteilt, um sie für den Abruf vorzubereiten. Das Ziel besteht darin, aussagekräftige und vollständig kontextualisierte Abschnitte zu erstellen, die genügend Informationen enthalten, um nützlich zu sein, und gleichzeitig Redundanzen zu minimieren.
Effektives Chunking sorgt für ein ausgewogenes Verhältnis zwischen Granularität und Vollständigkeit, sodass das System relevante Informationen abrufen kann, ohne den LLM mit unnötigen Details zu überladen. Gut strukturierte Blöcke verbessern die Abrufgenauigkeit, reduzieren den Token-Verbrauch und führen zu genaueren und kostengünstigeren Antworten.
Einbettungsmodelle
Einbettungsmodelle wandeln Daten in numerische Darstellungen um, die als Vektoren bezeichnet werden und die semantische Bedeutung erfassen. Dadurch kann das System die Beziehungen zwischen Wörtern, Phrasen und Dokumenten verstehen und die Genauigkeit beim Abrufen relevanter Informationen verbessern.
Bei der Aufnahme verarbeitet das Einbettungsmodell jedes Datenpaket und wandelt es in einen Vektor um, bevor es in einer Vektordatenbank gespeichert wird. Wenn ein Benutzer eine Abfrage sendet, wird diese mithilfe desselben Einbettungsmodells in einen Vektor umgewandelt.
Verschiedene Arten von Einbettungsmodellen unterstützen unterschiedliche Anwendungsfälle. Universelle Modelle eignen sich gut für breite Anwendungsbereiche, während domänenspezifische Modelle auf Branchen wie Recht, Medizin oder Finanzen zugeschnitten sind und die Abrufgenauigkeit in spezialisierten Bereichen verbessern. Multimodale Modelle gehen über die Textverarbeitung hinaus und verarbeiten Bilder, Audio und andere Datentypen, wodurch erweiterte Abruffunktionen ermöglicht werden. Einige Modelle können eine numerische Darstellung von Text erstellen, die direkt mit einem Bild oder Video verglichen werden kann, um eine wirklich fortschrittliche multimodale Abfrage zu ermöglichen.
Semantische Suche
Die semantische Suche verbessert die Informationsbeschaffung, indem sie sich auf die Bedeutung hinter der Anfrage eines Benutzers konzentriert und so die Stichwortsuche erheblich verbessert. Durch Einbettungen werden sowohl Abfragen als auch Dokumente in Vektoren umgewandelt, die die semantische Bedeutung erfassen. Wenn ein Benutzer eine Anfrage einreicht, sucht die Vektordatenbank nach den relevantesten Dokumenten, auch wenn die genauen Suchbegriffe nicht direkt im Inhalt enthalten sind.
Dieser Ansatz ermöglicht ein besseres Verständnis des Kontexts und gewährleistet genauere und relevantere Ergebnisse. Durch die Erkennung von Synonymen, verwandten Konzepten und Wortvariationen verbessert die semantische Suche die Benutzererfahrung und reduziert Mehrdeutigkeiten, sodass Ergebnisse angezeigt werden, die besser zur Absicht des Benutzers passen.
Reranking
Die Reranking-Technik wird eingesetzt, um die Relevanz von Suchergebnissen nach einer ersten Abrufphase zu verbessern. Sobald eine Reihe von Dokumenten abgerufen wurde, ordnet ein Reranking-Modell diese anhand ihrer Relevanz für die Suchanfrage des Benutzers neu. Dieses Modell kann zusätzliche Funktionen wie Dokumentqualität, kontextbezogene Relevanz oder auf maschinellem Lernen basierende Bewertung nutzen, um die Ergebnisse zu verfeinern.
Durch das Reranking können die nützlichsten und kontextbezogen passendsten Informationen priorisiert werden, wodurch die Genauigkeit und die Benutzerzufriedenheit verbessert werden. Dies ist besonders nützlich, wenn die erste Abrufphase eine Vielzahl von Ergebnissen liefern kann, sodass das System die Auswahl verfeinern und die relevantesten Antworten präsentieren kann.
Prompt-Engineering
Beim Prompt Engineering wird der Input, der einem LLM gegeben wird, sorgfältig ausgearbeitet, um den Output in die gewünschte Richtung zu lenken. Durch eine effektive Strukturierung der Eingabeaufforderungen können Sie sicherstellen, dass das Modell genauere, relevantere und angemessenere Antworten generiert. Dieser Prozess umfasst klare Anweisungen, relevante Zusammenhänge und manchmal Beispiele, um dem Modell das Verständnis der Aufgabe zu erleichtern.
Bei der Retrieval Augmented Generation spielt die schnelle Technik eine Schlüsselrolle bei der Kombination von abgerufenen Dokumenten mit der ursprünglichen Benutzeranfrage, um kohärente und präzise Antworten zu erzeugen. Sorgfältig ausgearbeitete Eingabeaufforderungen reduzieren Mehrdeutigkeiten, minimieren irrelevante Informationen und stellen sicher, dass das Modell mit den Absichten des Benutzers übereinstimmt, was zu qualitativ hochwertigeren Ergebnissen führt.
Optimierung Ihrer Anwendung zur Retrieval Augmented Generation
RAG-Lösungen können optimiert werden, um eine höhere Genauigkeit und eine insgesamt verbesserte Erfahrung für Endbenutzer zu bieten.
Optimierung der Informationsbeschaffung
Die Informationsbeschaffung für RAG kann durch verschiedene Strategien verbessert werden. Überprüfen Sie zunächst die Chunking-Techniken, um sicherzustellen, dass die Dokumente in sinnvolle, kontextbezogene Segmente unterteilt sind. Wählen Sie als Nächstes das richtige Einbettungsmodell, um die semantische Bedeutung Ihrer Inhalte zu erfassen. Domänenspezifische Modelle können für bestimmte Anwendungsfälle bessere Ergebnisse liefern. Obwohl die semantische Suche am häufigsten verwendet wird, sollten Sie überlegen, ob die Stichwortsuche oder ein hybrider Ansatz die Abrufbarkeit verbessern kann.
Wenden Sie außerdem nach dem ersten Abruf Reranking-Methoden an, um die Genauigkeit der Ergebnisse zu verbessern. Es ist auch wichtig, die Anzahl der abgerufenen Dokumente anzupassen: Zu viele können zu Unruhe führen, während bei zu wenigen wichtige Zusammenhänge übersehen werden können. Das richtige Gleichgewicht zu finden, trägt dazu bei, die Leistung und Relevanz der Abfrage zu verbessern.
Optimierung der Antwortgenerierung
Die Verbesserung der Sprachgenerierung in RAG kann durch mehrere Schlüsselansätze erreicht werden. Konzentrieren Sie sich zunächst auf eine schnelle Entwicklung, um Abfragen und Kontext so zu strukturieren, dass das Sprachmodell genauere und relevantere Antworten generiert. Klare Anweisungen, Kontext und Beispiele helfen, Unklarheiten zu reduzieren und die Qualität der Ergebnisse zu verbessern. Als Nächstes sollten Sie verschiedene Modelle oder domänenspezifische LLMs evaluieren, um sicherzustellen, dass die generierten Antworten mit den Nuancen Ihres spezifischen Anwendungsfalls übereinstimmen und so die Relevanz und Genauigkeit verbessern. Zusätzlich sollten anpassbare Modellparameter wie die Temperatur berücksichtigt werden, um die Kreativität der Modellantworten zu steuern.
Optimierung für den Produktionsmaßstab
Stellen Sie sicher, dass Ihr RAG-System produktionsbereit ist, indem Sie für Ihre wichtigsten Anwendungskomponenten die besten Anbieter auswählen.
Wählen Sie für Ihre Vektordatenbank eine Plattform, die hocheffiziente Such- und Indexierungsfunktionen bietet, insbesondere eine, die eine skalierbare, schnelle ANN-Suche (Approximative Nearest Neighbor) unterstützt. Fortgeschrittene Vektordatenbanken können auch Metadatenfilterung unterstützen, wodurch die Genauigkeit und Geschwindigkeit verbessert werden kann, indem die Suchergebnisse auf der Grundlage zusätzlicher Kontextinformationen eingegrenzt werden. Dadurch kann Ihr System relevante Dokumente schnell abrufen, auch wenn der Datenbestand wächst.
Bei der Auswahl eines Einbettungsmodells ist es wichtig, die hohe Dimensionalität von Vektoren mit einer effizienten Speicherung und Abfrage in Einklang zu bringen. Während höherdimensionale Einbettungen reichhaltigere semantische Beziehungen erfassen, sind sie mit höheren Rechenkosten, Speicheranforderungen und langsameren Abrufzeiten verbunden.
Wenn Sie ein Large Language Model (LLM) für die Generierungskomponente auswählen, stellen Sie außerdem sicher, dass es den spezifischen Anforderungen Ihres Anwendungsfalls entspricht. LLMs sollten in der Lage sein, die abgerufenen Informationen genau zu interpretieren und kohärente, kontextbezogene Antworten zu generieren. Die Wahl des LLM wirkt sich auch auf die Gesamtkosten und die Leistung des Systems aus – größere Modelle können eine höhere Genauigkeit bieten, jedoch auf Kosten einer höheren Latenz und höheren Rechenanforderungen. Es ist wichtig, Ihre Reaktionszeit, die Qualität der Ergebnisse und die Anforderungen an die Infrastruktur zu bewerten, um ein LLM auszuwählen, das die richtige Balance zwischen Leistung und Effizienz bietet.
Herausforderungen der Retrieval Augmented Generation
Eine der größten Herausforderungen von RAG ist die Schwierigkeit, Inhalte für eine effektive Abfrage zu zentralisieren und zu organisieren. RAG-Systeme erfordern den Zugriff auf große Datenmengen aus verschiedenen Bereichen, aber die Organisation dieser Inhalte in einer Weise, die es dem Modell ermöglicht, die relevantesten und aktuellsten Informationen effizient abzurufen, ist eine komplexe Aufgabe. Daten können über verschiedene Plattformen, Formate und Datenbanken verteilt sein, was es schwierig macht, eine umfassende Abdeckung und Genauigkeit zu gewährleisten. Darüber hinaus ist es von entscheidender Bedeutung, die Konsistenz über mehrere Quellen hinweg sicherzustellen. Die abgerufenen Informationen können widersprüchlich, veraltet oder unvollständig sein, was die Wissensbasis durcheinanderbringen und die Qualität und Zuverlässigkeit der generierten Antworten beeinträchtigen kann. Diese Herausforderungen verdeutlichen den Bedarf an ausgefeilteren Indexierungs- und Abrufsystemen, damit RAG-Modelle die bestmöglichen Inhalte abrufen und relevante, genaue Ergebnisse generieren können.
Eine weitere große Herausforderung ist die derzeitige Beschränkung der RAG auf die Beantwortung von Fragen, anstatt komplexere Aufgaben zu übernehmen. RAG-Systeme sind zwar hervorragend darin, auf der Grundlage abgerufener Informationen Antworten zu generieren, haben jedoch Schwierigkeiten, Aktionen auszuführen, die über die Beantwortung von Anfragen oder die Generierung von Inhalten hinausgehen. Diese Einschränkung ergibt sich daraus, dass RAG in erster Linie darauf ausgelegt ist, relevante Daten aus externen Quellen zu beziehen und auf der Grundlage dieser Daten Ergebnisse zu liefern, anstatt mit realen Umgebungen zu interagieren oder diese zu manipulieren. Daher können RAG-Modelle zwar bei der Informationsbeschaffung und der Erstellung von Inhalten helfen, ihre Fähigkeit, Aufgaben wie Problemlösung oder Entscheidungsfindung auszuführen, ist jedoch noch nicht ausreichend entwickelt, was ihr Potenzial für dynamischere Anwendungen einschränkt.
Erstellung einer speicheroptimierten interaktiven Retrieval Augment Generation
Durch die Erweiterung von RAG mit einem Speicher wird die Fähigkeit verbessert, ein interaktiveres Erlebnis zu schaffen, indem wichtige Details und der Kontext aus früheren Interaktionen gespeichert werden. Herkömmliche RAG-Systeme reagieren in der Regel auf Anfragen, ohne Informationen über mehrere Austausche hinweg zu speichern, was zu einem unzusammenhängenden Erlebnis führt. Durch die Integration von Speichermechanismen könnten RAG-Systeme relevante Fakten, Präferenzen oder Erkenntnisse aus aktuellen und früheren Gesprächen speichern und diese Informationen bei Bedarf abrufen. Dadurch kann das System personalisiertere, kontextbezogene Antworten bieten und ein nahtloseres Erlebnis schaffen. Mit der Zeit entwickelt das System ein tieferes Verständnis für die Bedürfnisse des Benutzers und passt seine Antworten an, um relevanter und ansprechender zu sein, sodass sich die Erfahrung wie ein fortlaufendes Gespräch und nicht wie eine Reihe isolierter Anfragen anfühlt.
Die Zukunft der Retrieval Augmented Generation und der generativen KI
Es werden weiterhin neue Techniken innerhalb von RAG entwickelt, die die Fähigkeit verbessern, Informationen auf effizientere, anpassungsfähigere und intelligentere Weise abzurufen und zu generieren. Ein wichtiger Wachstumsbereich ist die Entwicklung fortschrittlicher Abrufmechanismen, die es RAG-Systemen ermöglichen, dynamisch auf eine breitere Palette von Quellen zuzugreifen, darunter spezialisierte Datenbanken, unstrukturierte Inhalte und Echtzeitinformationen. Diese Verbesserungen werden RAG-Systeme kontextbezogener machen und es ihnen ermöglichen, in verschiedenen Bereichen äußerst relevante und genaue Ergebnisse zu generieren.
Gleichzeitig werden KI-Systeme durch die Integration neuer generativer KI-Agent-Fähigkeiten in die Lage versetzt, Aufgaben in den Bereichen Problemlösung, Datenanalyse und Entscheidungsfindung zu übernehmen. Diese agentischen Systeme rufen nicht nur Antworten ab und generieren sie, sondern ergreifen auch Maßnahmen auf der Grundlage der von ihnen gesammelten Informationen, wodurch sie interaktiver, autarker und intelligenter werden. Infolgedessen wird RAG eine zentrale Rolle bei Anwendungen wie automatisierter Forschung, personalisierten Empfehlungen und interaktiven virtuellen Assistenten spielen und eine neue Ära der reaktionsschnellen und proaktiven KI einläuten.
Feinabstimmung vs. Retrieval Augmented Generation
Die Feinabstimmung ist ein Prozess, bei dem ein Sprachmodell durch zusätzliches Training mit neuen Inhalten modifiziert wird, wobei dem Modell im Wesentlichen neues Wissen oder neue Verhaltensweisen beigebracht werden, die dauerhaft in seinem parametrischen Gedächtnis verankert werden. Dieser Ansatz erfordert erhebliche Rechenressourcen und Fachwissen, hat aufgrund der begrenzten Modellgröße nur eine begrenzte Kapazität für neue Informationen und alle vorgenommenen Änderungen sind dauerhaft und können nicht einfach aktualisiert werden. Ein fein abgestimmtes Modell kann bereichsspezifische Ergebnisse liefern, erfordert jedoch einen erheblichen Zeitaufwand für die Schulung und hat Auswirkungen auf die Kosten, was es schwierig macht, auf dem neuesten Stand zu bleiben.
RAG (Retrieval Augmented Generation) ruft Inhalte, die nicht Teil der Trainingsdaten sind, dynamisch ab, bevor die Sprachgenerierung erfolgt. Dadurch können RAG-Modelle neue Daten einbeziehen, ohne die zugrunde liegenden Parameter des Modells zu verändern, wodurch es flexibler und skalierbarer wird und wissensintensive Aufgaben wie die Feinabstimmung erleichtert.
Erstellen Sie RAG-Anwendungen mit MongoDB Atlas und Voyage AI
MongoDB Atlas ist eine robuste Allzweck-Datenbank, die Vektoren und Vektorsuchen unterstützt und sich daher ideal für die Erstellung von RAG-Anwendungen in Produktionsqualität eignet.
Voyage AI bietet leistungsstarke Einbettungsmodelle und Reranking-Modelle für eine äußerst präzise Informationsbeschaffung.
Bringen Sie Ihre Projekte auf die nächste Stufe – vereinfachen Sie Ihren Entwicklungsprozess und erschließen Sie neue Werte, während Sie von der nahtlosen Integration mit führenden KI-Partnern, großen Cloud-Anbietern, LLM-Modellanbietern und Systemintegratoren profitieren.
Ressourcen
Entdecken Sie MongoDB Atlas – die Vektordatenbank mit integrierter Suche, Vektorfunktionen und mehr. Jetzt kostenlos registrieren.
Um mehr über Voyage AI zu erfahren, können Sie diesen Blog besuchen.
Erhalten Sie strategische Beratung und Unterstützung bei der Implementierung für die Suche und den Rest des KI-Stacks. Besuchen Sie unser MongoDB-KI-Anwendungsprogramm, um weitere Informationen zu erhalten.