A geração aumentada de recuperação (RAG) é um framework popular de IA generativa que aprimora as capacidades de grandes modelos de linguagem (LLM) ao incorporar informações relevantes e atualizadas durante o processo de geração. Esta abordagem permite que os LLMs complementem seu conhecimento pré-treinado com dados atuais e específicos do domínio. RAG é uma solução custo-efetiva para personalizar um LLM para casos de uso específicos sem o processo caro e demorado de ajuste fino ou retreinamento de todo o modelo.
Geração aumentada de recuperação para IA mais inteligente
A geração aumentada de recuperação permite que as organizações utilizem modelos de linguagem de uso geral para aplicações especializadas sem a necessidade de modelos caros e personalizados. A RAG aborda diretamente as limitações fundamentais desses modelos, enriquecendo as consultas com informações atuais e específicas do domínio para melhorar as capacidades de geração. Isso permite que as organizações integrem informações em tempo real, conjuntos de dados proprietários e documentação especializada que não fazem parte do treinamento original do modelo. Ao fornecer evidências de forma transparente com respostas, a RAG melhora a confiança e reduz o risco de alucinações.
O que são grandes modelos de linguagem?
LLMs são uma forma de inteligência artificial projetada para compreender e gerar textos semelhantes aos humanos. Como um aplicativo avançado de Processamento de Linguagem Natural (PLN), os LLMs podem aprender padrões, estruturas e gramática a partir de grandes volumes de dados de treinamento, permitindo-lhes gerar respostas coerentes a solicitações de usuários. A força dos LLMs está na sua capacidade de executar uma ampla variedade de tarefas de geração de linguagem sem a necessidade de treinamento específico para cada tarefa. Isso os torna ferramentas versáteis para aplicativos como chatbots, tradução, criação de conteúdo e sumarização.
As limitações dos grandes modelos de linguagem
Um LLM é uma rede neural complexa que aprende ao analisar grandes conjuntos de dados de treinamento. Esses modelos requerem recursos computacionais significativos, tornando-os extremamente caros e demorados para serem desenvolvidos. Além disso, a infraestrutura especializada necessária para hospedar e manter LLMs personalizados cria barreiras financeiras significativas, limitando sua acessibilidade apenas a organizações bem financiadas com investimentos tecnológicos consideráveis.
LLMs são excelentes para responder a perguntas sobre conteúdo histórico, mas seu conhecimento é restrito pelas limitações dos dados de treinamento. Isso os torna menos eficazes para consultas que exigem conhecimento atualizado, pois não conseguem responder a consultas sobre eventos recentes sem retreinamento do modelo.
Da mesma forma, os LLMs não conseguem responder nativamente a perguntas sobre a documentação interna da empresa ou outros conjuntos de dados específicos do domínio exclusivos de uma organização. Essa limitação impõe desafios significativos para empresas que buscam utilizar tecnologias de AI que demandam conhecimento profundo e especializado, específico para suas necessidades.
Essas limitações destacam outro desafio dos LLMs: alucinações. Sem informações verificáveis, os modelos de linguagem podem gerar respostas que soam confiantes e plausíveis, mas são completamente fabricadas. Essa tendência de gerar informações convincentes, mas falsas, acarreta riscos significativos para aplicativos que demandam precisão e confiabilidade.

Benefícios da geração aumentada de recuperação
O RAG tornou-se popular devido à sua arquitetura relativamente simples, juntamente com melhorias significativas no desempenho.
Econômico
A RAG permite que as organizações utilizem modelos pré-treinados de uso geral para aplicativos especializados sem o custo de desenvolver modelos personalizados. A recuperação eficaz reduz os custos da API, assegurando que apenas as informações necessárias sejam incluídas para otimizar os LLMs que cobram por token.
Customização de domínio
O RAG permite que as organizações personalizem modelos pré-treinados para domínios específicos integrando bibliotecas de conhecimento especializadas. Isso permite que os modelos gerem respostas sobre documentação proprietária e específica do setor sem a necessidade de treinamento personalizado do modelo. O ajuste fino pode oferecer benefícios semelhantes, mas exige significativamente mais tempo, custos e manutenção.
Insights em tempo real
A RAG permite que LLMs acessem e gerem respostas usando informações atuais, recuperando dinamicamente dados atualizados de fontes externas. Isso supera as limitações de conhecimento dos conjuntos de dados de treinamento estáticos, permitindo que os modelos forneçam perspicácia sobre eventos recentes e tendências emergentes.
Transparência
O RAG melhora a confiabilidade das respostas da AI ao fornecer citações de fontes e evidências para o conteúdo gerado. Ao vincular cada resposta a fontes específicas na base de conhecimento, o RAG permite que os usuários verifiquem a origem e a precisão das informações, reduzindo o risco de alucinações e aumentando a confiança nos resultados gerados por IA.
Adaptabilidade
Uma das principais vantagens do RAG é a sua capacidade de se adaptar facilmente a novos modelos de última geração. Conforme surgem avanços nos modelos de linguagem ou técnicas de recuperação, as organizações podem integrar modelos mais novos ou ajustar estratégias de recuperação sem a necessidade de reformular todo o sistema. Essa flexibilidade assegura que um sistema RAG possa permanecer atualizado com as mais recentes tecnologias.
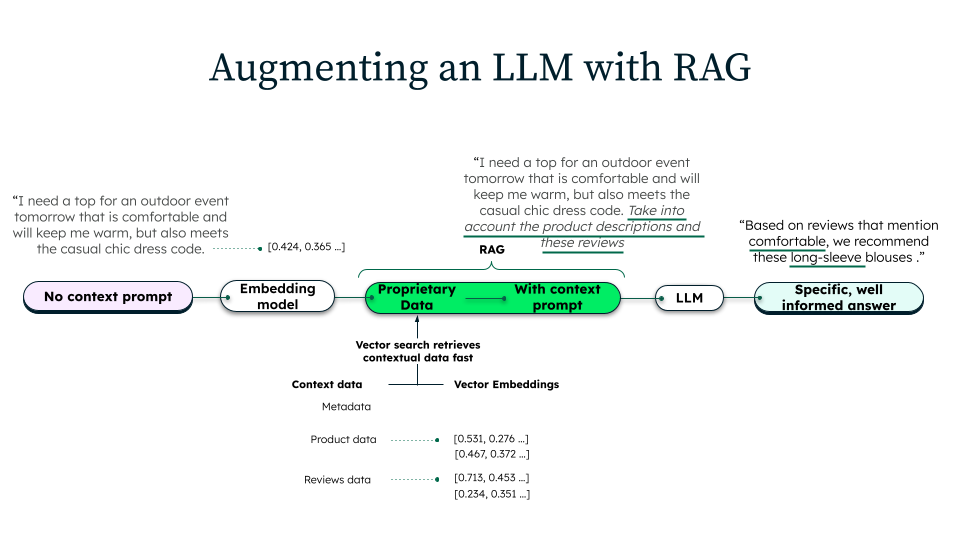
Como funciona a geração aumentada de recuperação?
A RAG consiste em três fases distintas: ingestão, recuperação e geração.
Ingestão de dados
Durante a ingestão, as organizações preparam sua base de conhecimento para recuperação. Os dados de origem são coletados de diversos repositórios, como documentação interna, bancos de dados ou recursos externos. Esses documentos são então limpos, formatados, e divididos em partes menores e gerenciáveis. Cada parte é convertida em uma representação vetorial usando um modelo de incorporação, que captura o significado semântico do texto. Esses vetores são armazenados em bancos de dados vetoriais que possibilitam uma pesquisa semântica e recuperação eficientes.
Recuperação de informação
Quando um usuário submete uma consulta, o sistema recupera o contexto relevante antes da geração. A consulta é transformada em uma representação vetorial usando o mesmo modelo de embedding utilizado durante a ingestão. A pesquisa vetorial buscará no banco de dados as partes de documento mais semanticamente semelhantes à query. Técnicas adicionais de filtro, classificação ou reponderação podem ser aplicadas para garantir que apenas as informações mais relevantes sejam recuperadas, melhorando a precisão da resposta final.
Geração
Assim que o contexto relevante é recuperado, um prompt aumentado é construído utilizando o prompt original, as mesmas passagens recuperadas e instruções específicas. O LLM processa este prompt para gerar uma resposta que sintetiza seu conhecimento pré-treinado com o conteúdo recuperado. Essa abordagem assegura que a resposta seja fundamentada em fontes de dados externas e esteja alinhada com a intenção do usuário, resultando em uma resposta mais precisa.
Casos de uso do setor para geração aumentada de recuperação
RAG já está sendo utilizada em diversos setores para desbloquear o potencial transformador dos grandes modelos de linguagem e da inteligência artificial.
- Fabricação: Aumente os LLMs com manuais de equipamentos e registros de manutenção para fornecer orientação operacional em tempo real. O RAG permite que os técnicos acessem rapidamente informações precisas sobre o maquinário, reduzindo o tempo de inatividade e melhorando o desempenho dos equipamentos.
- Suporte ao cliente: Utilize a documentação interna, guias de produtos e histórico de suporte para diagnosticar problemas. A RAG ajuda as equipes de suporte a recuperar instantaneamente conteúdo útil, reduzindo os tempos de resposta e melhorando as taxas de resolução no primeiro contato para responder eficientemente às consultas dos clientes.
- Saúde: Sintetizar pesquisas médicas, diretrizes clínicas e registros de pacientes para suporte decisões de diagnóstico e recomendações de tratamento. A RAG permite que os profissionais de saúde acessem o conhecimento médico atual enquanto fornecem perspicácia transparentes e baseadas em evidências.
- Serviços financeiros: Integrar documentos regulatórios, relatórios de mercado e diretrizes de compliance para apoiar a pesquisa de investimentos, a avaliação de risco e a conformidade regulatória. O RAG permite que analistas financeiros recuperem e analisem rapidamente informações financeiras complexas e atualizadas.
- Engenharia de software: Revisar a documentação e os trechos de código para ajudar os engenheiros enquanto gravam código. O RAG também pode auxiliar na depuração, sugerindo correções potenciais com base em problemas semelhantes anteriores, melhorando a produtividade e a qualidade.
Conceitos-chave para geração aumentada de recuperação
Chunking
O particionamento é um componente do processo de ingestão de dados que melhora a precisão do sistema enquanto reduz os custos. Isso envolve dividir grandes partes do conteúdo em segmentos menores e gerenciáveis para prepará-los para recuperação. O objetivo é criar partes significativas e totalmente contextualizadas, garantindo que elas retenham informações suficientes para serem úteis, enquanto minimizam a redundância.
A fragmentação eficaz equilibra a granularidade e a completude, permitindo que o sistema recupere informações relevantes sem sobrecarregar o LLM com detalhes desnecessários. Partes bem estruturadas melhoram a precisão da recuperação, reduzem o uso de tokens e resultam em respostas mais precisas e eficientes em termos de custo.
Modelos de incorporação
Modelos de incorporação convertem dados em representações numéricas chamadas vetores que capturam o significado semântico. Isso permite que o sistema compreenda os relacionamentos entre palavras, frases e documentos, melhorando a precisão na recuperação de informações relevantes.
Durante a ingestão, o modelo de incorporação processa cada parte de dados, transformando-o em um vetor antes de armazená-lo em um banco de dados vetorial. Quando um usuário submete uma query, ela é convertida em um vetor usando o mesmo modelo de incorporação.
Diferentes tipos de modelos de embedding oferecem suporte a vários casos de uso. Modelos de uso geral funcionam bem para aplicativos amplos, enquanto modelos específicos de domínio são adaptados para setores como jurídico, médico ou financeiro, melhorando a precisão da recuperação em campos especializados. Os modelos multimodais go além do processamento de texto para lidar com imagens, áudio e outros tipos de dados, possibilitando capacidades de recuperação mais avançadas. Alguns modelos podem criar uma representação numérica de texto que pode ser comparada diretamente com uma imagem ou vídeo para uma recuperação multimodal realmente avançada.
Pesquisa semântica
A pesquisa semântica aprimora a recuperação de informações ao focar no significado por trás da query de um usuário, melhorando significativamente a pesquisa por palavras-chave. Usando embeddings, tanto as consultas quanto os documentos são convertidos em vetores que capturam o significado semântico. Quando um usuário submete uma query, o banco de dados vetorial pesquisa para encontrar os documentos mais relevantes, mesmo que os termos exatos da query não estejam diretamente presentes no conteúdo.
Essa abordagem possibilita uma compreensão contextual aprimorada, assegurando resultados mais precisos e relevantes. Ao identificar sinônimos, conceitos relacionados e variações de palavras, a pesquisa semântica melhora a experiência do usuário e diminui a ambiguidade, oferecendo resultados que melhor correspondem à intenção do usuário.
Reclassificação
Reranking é uma técnica utilizada para aprimorar a relevância dos resultados de pesquisa após uma fase inicial de recuperação. Assim que um conjunto de documentos é recuperado, um modelo de rerranqueamento os reordena com base em sua relevância para a query do usuário. Este modelo pode utilizar recursos adicionais, como qualidade do documento, relevância contextual ou pontuação baseada em aprendizado de máquina, para aprimorar os resultados.
O reranqueamento ajuda a priorizar as informações mais úteis e contextualmente apropriadas, melhorando a precisão e a satisfação do usuário. É especialmente útil quando a fase inicial de recuperação pode retornar uma ampla gama de resultados, permitindo que o sistema ajuste a seleção e apresente as respostas mais relevantes.
Engenharia de instruções
A engenharia de prompts envolve a elaboração cuidadosa da entrada fornecida a um LLM para guiar sua saída na direção desejada. Ao estruturar os prompts de forma eficaz, você pode garantir que o modelo gere respostas mais precisas, relevantes e adequadas. Esse processo envolve a inclusão de instruções claras, contexto relevante e, por vezes, exemplos para auxiliar o modelo a compreender a tarefa.
Em RAG, a engenharia de prompt desempenha um papel crucial na combinação de documentos recuperados com a query original do usuário para produzir respostas coerentes e precisas. Prompts bem elaborados reduzem a ambiguidade, minimizam informações irrelevantes e garantem que o modelo esteja alinhado com a intenção do usuário, resultando em saídas de maior qualidade.
Otimizando seu aplicativo de geração aumentada de recuperação
As soluções RAG podem ser otimizadas para aumentar a precisão e melhorar a experiência geral dos usuários finais.
Otimização da recuperação de informações
A recuperação de informações para RAG pode ser aprimorada através de várias estratégias. Primeiro, revise as técnicas de divisão para garantir que os documentos sejam divididos em partes significativas e contextualmente relevantes. Em seguida, selecione o modelo de incorporação adequado para capturar o significado semântico do seu conteúdo. Modelos específicos de domínio podem oferecer melhores resultados para certos casos de uso. Embora a pesquisa semântica seja a mais utilizada, avalie se a pesquisa por palavras-chave ou uma abordagem híbrida pode melhorar a recuperação.
Além disso, aplique métodos de reclassificação após a recuperação inicial para refinar a precisão dos resultados. É igualmente crucial ajustar a quantidade de documentos recuperados: muitos podem introduzir ruído, enquanto poucos podem deixar de captar um contexto importante. Encontrar o equilíbrio adequado ajuda a melhorar o desempenho e a relevância da recuperação de dados.
Otimizar a geração de respostas
A melhoria da geração de linguagem no RAG pode ser alcançada por meio de várias abordagens principais. Primeiro, concentre-se na engenharia de prompts para estruturar queries e contextos de uma maneira que guia o modelo de linguagem a gerar respostas mais precisas e relevantes. Instruções claras, contexto e exemplos ajudam a reduzir a ambiguidade e a melhorar a qualidade do resultado. Em seguida, avalie diferentes modelos ou LLMs específicos do domínio para garantir que as respostas geradas estejam alinhadas com as nuances do seu caso de uso específico, melhorando a relevância e a precisão. Além disso, parâmetros ajustáveis do modelo, como a temperatura, devem ser considerados para controlar a criatividade das respostas do modelo.
Otimizando para escala de produção
Garanta que seu sistema RAG esteja pronto para produção escolhendo fornecedores de primeira linha para os componentes principais do seu aplicativo.
Para seu banco de dados vetorial, opte por uma plataforma que forneça capacidades de pesquisa e indexação altamente eficientes, especialmente uma que suporte pesquisa ANN dimensionável e rápida. Bancos de dados vetoriais avançados também podem oferecer suporte à filtragem de metadados, o que pode melhorar a precisão e a velocidade ao restringir os resultados da pesquisa com base em informações contextuais adicionais. Isso permitirá que seu sistema recupere documentos relevantes rapidamente, mesmo à medida que o conjunto de dados cresce.
Ao escolher um modelo de incorporação, é crucial equilibrar a alta dimensionalidade dos vetores com a eficiência no armazenamento e na recuperação. Embora as incorporações de dimensões mais altas capturem relacionamentos semânticos mais ricos, elas acarretam um aumento no custo computacional, nos requisitos de armazenamento e em tempos de recuperação mais lentos.
Além disso, ao escolher um LLM para o componente de geração, certifique-se de que ele atenda às necessidades específicas do seu caso de uso. Os LLMs devem ser capazes de interpretar com precisão as informações recuperadas e gerar respostas coerentes e relevantes ao contexto. A escolha do LLM também tem impacto no custo total e no desempenho do sistema — modelos maiores podem oferecer melhor precisão, mas ao custo de maior latência e exigências computacionais. É fundamental avaliar o tempo de resposta, a qualidade do resultado e os requisitos de infraestrutura para escolher um LLM que atinja o equilíbrio ideal entre desempenho e eficiência.
Desafios da geração aumentada de recuperação
Um dos principais desafios da Geração Aumentada de Recuperação (RAG) é a dificuldade em centralizar e organizar o conteúdo para uma recuperação eficaz. Os sistemas RAG necessitam de acesso a vastas quantidades de dados em diversos domínios, mas organizar esse conteúdo de modo a permitir que o modelo recupere eficientemente as informações mais relevantes e atualizadas é uma tarefa complexa. Os dados podem ser distribuídos por várias plataformas, formatos e bancos de dados, o que torna difícil garantir uma cobertura e precisão completas. Além disso, garantir a consistência entre várias fontes é crucial. As informações recuperadas podem ser contraditórias, desatualizadas ou incompletas, o que pode confundir a Base de Conhecimento e prejudicar a qualidade e a confiabilidade das respostas geradas. Esses desafios destacam a necessidade de sistemas de indexação e recuperação mais sofisticados para permitir que os modelos RAG acessem o melhor conteúdo possível e gerem saídas relevantes e precisas.
Outro desafio significativo é a limitação atual do RAG em responder a perguntas em vez de realizar tarefas mais complexas. Embora os sistemas RAG sejam excelentes em gerar respostas com base nas informações recuperadas, eles têm dificuldade em executar ações além de responder a consultas ou gerar conteúdo. Essa restrição surge porque a RAG é projetada principalmente para extrair dados relevantes de fontes externas e fornecer saídas com base nesses dados, em vez de interagir com ou manipular ambientes do mundo real. Como resultado, embora os modelos RAG possam auxiliar na recuperação de informações e geração de conteúdo, sua capacidade de executar tarefas como resolução de problemas ou tomada de decisões continua subdesenvolvida, limitando seu potencial para aplicativos mais dinâmicos.
Criando geração de recuperação aumentada interativa aprimorada por memória
O aprimoramento da RAG com memória expande sua capacidade de criar uma experiência mais interativa ao lembrar detalhes chave e o contexto de interações passadas. Os sistemas RAG tradicionais normalmente respondem a consultas sem reter informações ao longo de várias interações, resultando em uma experiência fragmentada. Ao integrar mecanismos de memória, os sistemas RAG poderiam armazenar fatos, preferências ou perspicácias relevantes de conversas atuais e anteriores, permitindo que eles recuperem essas informações conforme necessário. Isso permite que o sistema ofereça respostas mais personalizadas, sensíveis ao contexto e crie uma experiência perfeita. Com o tempo, o sistema desenvolve uma compreensão mais aprofundada das necessidades do usuário, ajustando suas respostas para serem mais pertinentes e envolventes, fazendo com que a experiência se assemelhe a uma conversa contínua em vez de uma série de consultas isoladas.
O futuro da geração aumentada de recuperação e da IA generativa
Novas técnicas dentro da Geração Aumentada de Recuperação (RAG) continuarão a surgir, aprimorando sua capacidade de recuperar e gerar informações de maneiras mais eficientes, adaptáveis e inteligentes. Uma área chave de crescimento é o desenvolvimento de mecanismos avançados de recuperação, permitindo que os sistemas RAG acessem dinamicamente uma gama mais ampla de fontes, incluindo bancos de dados especializados, conteúdo não estruturado e informações em tempo real. Essas melhorias tornarão os sistemas RAG mais cientes do contexto, permitindo que eles gerem saídas altamente relevantes e precisas em diversos domínios.
Ao mesmo tempo, a integração de novas capacidades agenticas de IA generativa capacitará os sistemas de AI a realizar tarefas de resolução de problemas, análise de dados e tomada de decisões. Esses sistemas agentes não apenas recuperarão e gerarão respostas, mas também tomarão ações com base nas informações que coletam, tornando-os mais interativos, autossuficientes e inteligentes. Como resultado, a RAG se tornará central para aplicativos como pesquisa automatizada, recomendações personalizadas e assistentes virtuais interativos, impulsionando uma nova era de AI responsiva e proativa.
Ajuste fino versus geração aumentada de recuperação
O ajuste fino é um processo em que um modelo de linguagem é modificado por meio de treinamento adicional em novo conteúdo, essencialmente ensinando ao modelo novos conhecimentos ou comportamentos que se tornam permanentemente incorporados em sua memória paramétrica. Esta abordagem exige recursos computacionais significativos e experiência, possui capacidade limitada para novas informações devido a restrições de tamanho do modelo, e quaisquer alterações realizadas são permanentes e não podem ser facilmente atualizadas. Um modelo ajustado pode fornecer resultados específicos para o domínio, mas possui requisitos significativos de tempo de treinamento e implicações de custo, tornando difícil mantê-lo atualizado.
A geração RAG recupera dinamicamente o conteúdo que não faz parte dos dados de treinamento antes que a geração de linguagem ocorra. Isso permite que os modelos RAG incorporem novos dados sem alterar os parâmetros subjacentes do modelo, tornando-os mais flexíveis e dimensionáveis para tarefas intensivas em conhecimento, como ajuste fino.
Desenvolva aplicações RAG com MongoDB Atlas e Voyage AI
O MongoDB Atlas é um banco de dados robusto de uso geral que oferece suporte a vetores e pesquisa vetorial, tornando-o uma escolha ideal para desenvolver aplicações RAG de nível de produção.
A Voyage AI oferece modelos de incorporação e reclassificação poderosos para criar uma recuperação de informações altamente precisa.
Leve seus projetos para o próximo nível — simplifique seu processo de desenvolvimento e desbloqueie novos valores enquanto se beneficia da integração perfeita com os principais parceiros de IA, grandes provedores de nuvem, fornecedores de modelos LLM e integradores de sistemas.
Recursos
Explore o MongoDB Atlas - o banco de dados vetorial com pesquisa integrada, capacidades vetoriais e muito mais. Registre-se gratuitamente agora.
Para aprender mais sobre o Voyage AI, você pode aprender mais em este blog.
Obtenha conselho estratégico e suporte de implementação para pesquisa e o restante da pilha de IA, visite nosso Programa de Aplicações de IA do MongoDB para mais detalhes.