La generación aumentada por recuperación (RAG) es un marco popular de IA generativa que mejora las capacidades de los modelos de lenguaje de gran tamaño (LLM) al incorporar información relevante y actualizada durante el proceso de generación. Este enfoque permite a los LLMs complementar su conocimiento preentrenado con datos actuales y específicos del dominio. RAG es una solución rentable para personalizar un LLM para casos de uso específicos sin el costoso y lento proceso de ajuste fino o reentrenamiento de todo el modelo.
Generación aumentada por recuperación para una IA más inteligente
La generación aumentada por recuperación permite a las organizaciones aprovechar los modelos de lenguaje de propósito general para aplicaciones especializadas sin necesidad de modelos costosos y entrenados a medida. La generación aumentada por recuperación (RAG) aborda directamente las limitaciones fundamentales de estos modelos al enriquecer las consultas con información actual y específica del dominio para mejorar las capacidades de generación. Esto permite a las organizaciones incorporar información en tiempo real, conjuntos de datos propios y documentación especializada que no forma parte del entrenamiento del modelo original. Al proporcionar pruebas de manera transparente con las respuestas, RAG mejora la confianza y reduce el riesgo de alucinaciones.
¿Qué son los modelos de lenguaje grandes?
Los LLM son una forma de inteligencia artificial diseñada para comprender y producir texto similar al humano. Como una aplicación avanzada del procesamiento del lenguaje natural (NLP), los LLM pueden aprender patrones, estructuras y gramática de grandes cantidades de datos de entrenamiento, lo que les permite generar respuestas coherentes a las solicitudes de los usuarios. La fortaleza de los LLMs radica en su capacidad para llevar a cabo una amplia gama de tareas de generación de lenguaje sin la necesidad de entrenamiento específico para cada tarea. Esto los convierte en herramientas versátiles para aplicaciones como chatbots, traducción, creación de contenido y resumen.
Las limitaciones de los grandes modelos de lenguaje
Un modelo de lenguaje grande es una red neuronal compleja que aprende analizando conjuntos de datos de entrenamiento masivos. Estos modelos requieren recursos computacionales sustanciales, lo que los hace extremadamente costosos y que consumen mucho tiempo para desarrollar. Además, la infraestructura especializada necesaria para alojar y mantener LLMs personalizados crea barreras financieras significativas, limitando su accesibilidad únicamente a organizaciones bien dotadas de recursos con inversiones tecnológicas considerables.
Los LLM son excelentes para responder preguntas sobre contenido histórico, pero su conocimiento está limitado por las restricciones de sus datos de entrenamiento. Esto los hace menos efectivos para consultas que requieren conocimientos actualizados, ya que no pueden responder consultas sobre eventos recientes sin un reentrenamiento del modelo.
De manera similar, los LLM no pueden responder de manera nativa a preguntas sobre la documentación interna de la empresa u otros conjuntos de datos específicos del dominio que son exclusivos de una organización en particular. Esta limitación plantea desafíos significativos para las empresas que buscan aprovechar las tecnologías de IA que requieren un conocimiento profundo y especializado adaptado a sus necesidades.
Estas limitaciones destacan otro desafío de los LLM: las alucinaciones. Sin información verificable, los modelos de lenguaje pueden generar respuestas seguras, plausibles y completamente fabricadas. Esta tendencia a generar información convincente pero falsa genera riesgos significativos para las aplicaciones que requieren precisión y confiabilidad.

Beneficios de la generación aumentada por recuperación
RAG se ha vuelto popular debido a su arquitectura relativamente simple, junto con mejoras significativas en el rendimiento.
Rentable
RAG permite a las organizaciones utilizar modelos preentrenados de propósito general para aplicaciones especializadas sin el gasto de desarrollar modelos entrenados a medida. La recuperación efectiva reduce los costos de la API al asegurar que solo se incluya la información necesaria para optimizar los LLM que cobran por token.
Personalización de dominios
RAG permite a las organizaciones adaptar modelos preentrenados a dominios específicos mediante la integración de bibliotecas de conocimientos especializados. Esto permite que los modelos generen respuestas sobre documentación propietaria y específica de la industria sin necesidad de entrenamiento personalizado del modelo. El ajuste fino puede proporcionar beneficios similares, pero requiere significativamente más tiempo, costo y mantenimiento.
Información estratégica en tiempo real
RAG permite a los grandes modelos de lenguaje acceder y generar respuestas utilizando información actual al recuperar dinámicamente datos actualizados de fuentes externas. Esto supera las limitaciones de conocimiento de los conjuntos de datos de entrenamiento estático, permitiendo que los modelos ofrezcan información sobre eventos recientes y tendencias emergentes.
Transparencia
RAG mejora la fiabilidad de las respuestas de la IA al proporcionar citas de fuentes y evidencia para el contenido generado. Al vincular cada respuesta a fuentes específicas en la base de conocimientos, RAG permite a los usuarios verificar el origen y la exactitud de la información, reduciendo el riesgo de alucinaciones y generando confianza en los resultados generados por la IA.
Adaptabilidad
Una ventaja clave de RAG es su capacidad para adaptarse fácilmente a nuevos modelos de última generación. A medida que surgen avances en los modelos de lenguaje o técnicas de recuperación, las organizaciones pueden sustituir modelos más nuevos o ajustar estrategias de recuperación sin tener que rehacer todo el sistema. Esta flexibilidad garantiza que un sistema RAG pueda mantenerse al día con la tecnología de vanguardia.
¿Cómo funciona la generación aumentada por recuperación?
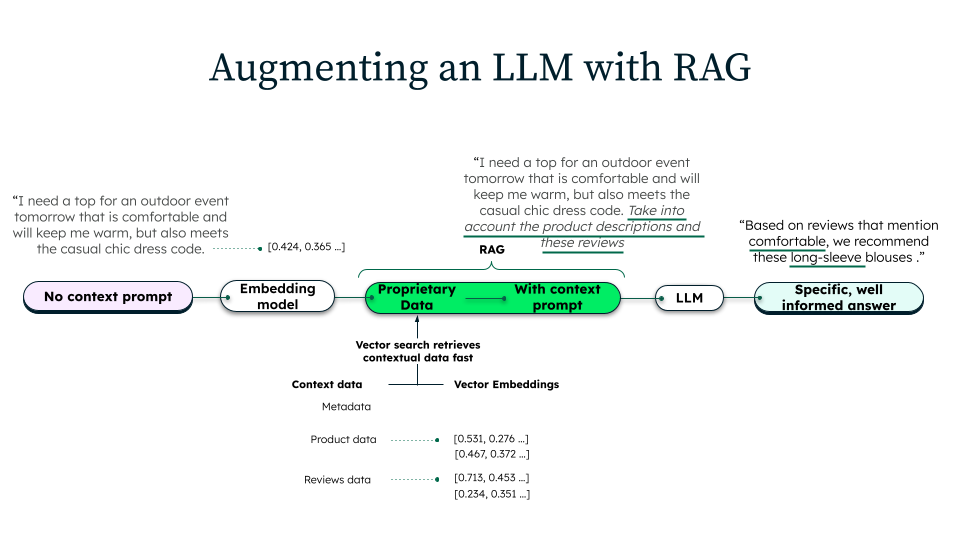
RAG consta de tres fases distintas: ingestión, recuperación y generación.
Ingestión de datos
Durante la ingesta, las organizaciones preparan su base de conocimientos para su recuperación. Los datos de origen se recopilan de varios repositorios, como documentación interna, bases de datos o recursos externos. A continuación, estos documentos se limpian, se formatean y se dividen en fragmentos más pequeños y manejables. Cada fragmento se convierte en una representación vectorial mediante un modelo de incrustación, que capta el significado semántico del texto. Estos vectores se almacenan en bases de datos vectoriales que facilitan una búsqueda y recuperación semántica eficiente.
Recuperación de información
Cuando un usuario envía una consulta, el sistema recupera el contexto relevante antes de la generación. La consulta se transforma en una representación vectorial utilizando el mismo modelo de incrustación empleado durante la ingesta. La búsqueda vectorial buscará en la base de datos los fragmentos de documentos más similares semánticamente a la consulta. Se pueden aplicar técnicas adicionales de filtrado, clasificación o reponderación para asegurar que solo se recupere la información más relevante, mejorando la precisión de la respuesta final.
Generación
Una vez que se recupera el contexto relevante, se construye un mensaje aumentado utilizando el mensaje original, los mismos pasajes recuperados e instrucciones específicas. El LLM procesa este aviso para generar una respuesta que sintetice su conocimiento preentrenado con el contenido recuperado. Este enfoque asegura que la respuesta esté fundamentada en fuentes de datos externas y alineada con la intención del usuario, resultando en una respuesta más precisa.
Casos de uso industriales para la generación aumentada por recuperación
RAG ya se está utilizando en diversas industrias para desbloquear el potencial transformador de los modelos de lenguaje de gran tamaño y la inteligencia artificial.
- Fabricación: Augmente los LLM con manuales de equipos y registros de mantenimiento para proporcionar orientación operativa en tiempo real. RAG permite a los técnicos acceder rápidamente a información precisa sobre la maquinaria, reduciendo el tiempo de inactividad y mejorando el rendimiento del equipo.
- Soporte al cliente: Aproveche la documentación interna, las guías de productos y el historial de soporte para diagnosticar problemas. RAG ayuda a los equipos de soporte a recuperar instantáneamente contenido útil, reduciendo los tiempos de respuesta y mejorando las tasas de resolución en el primer contacto para responder eficientemente a las consultas de los clientes.
- Cuidado de la salud: Sintetice investigaciones médicas, pautas clínicas y registros de pacientes para apoyar decisiones de diagnóstico y recomendaciones de tratamiento. La RAG permite a los profesionales de la salud acceder al conocimiento médico actual mientras proporciona información transparente y basada en evidencia.
- Servicios financieros: Integre documentos normativos, informes de mercado y directrices de cumplimiento para apoyar la investigación de inversiones, la evaluación de riesgos y el cumplimiento normativo. RAG permite a los analistas financieros recuperar y analizar rápidamente información financiera compleja y actualizada.
- Ingeniería de software: Revise la documentación y los fragmentos de código para asistir a los ingenieros mientras escriben código. RAG también puede ayudar con la depuración al sugerir posibles soluciones basadas en problemas similares del pasado, mejorando la productividad y la calidad.
Conceptos clave para la generación aumentada por recuperación
Chunking
El particionamiento es un componente del proceso de ingestión de datos que mejora la precisión del sistema mientras reduce los costos. Implica dividir grandes bloques de contenido en segmentos más pequeños y manejables para prepararlos para su recuperación. El objetivo es crear fragmentos significativos y completamente contextualizados, asegurando que retengan suficiente información para ser útiles mientras se minimiza la redundancia.
La fragmentación efectiva equilibra la granularidad y la integridad, permitiendo al sistema recuperar información relevante sin sobrecargar al LLM con detalles innecesarios. Los fragmentos bien estructurados mejoran la precisión de la recuperación, reducen el uso de tokens y conducen a respuestas más precisas y rentables.
Modelos de incrustación
Los modelos de incrustación convierten datos en representaciones numéricas llamadas vectores que capturan el significado semántico. Esto permite al sistema entender las relaciones entre palabras, frases y documentos, mejorando la precisión en la recuperación de información relevante.
Durante la ingesta, el modelo de incrustación procesa cada fragmento de datos, convirtiéndolo en un vector antes de almacenarlo en una base de datos de vectores. Cuando un usuario envía una consulta, esta se convierte en un vector utilizando el mismo modelo de incrustación.
Los diferentes tipos de modelos de incrustación admiten varios casos de uso. Los modelos de propósito general funcionan bien para aplicaciones amplias, mientras que los modelos específicos de dominio están diseñados para industrias como la legal, la médica o la financiera, mejorando la precisión de recuperación en campos especializados. Los modelos multimodales van más allá del procesamiento de texto para manejar imágenes, audio y otros tipos de datos, lo que permite capacidades de recuperación más avanzadas. Algunos modelos pueden generar una representación numérica del texto que se puede comparar directamente con una imagen o un video para una recuperación multimodal realmente avanzada.
Búsqueda semántica
La búsqueda semántica mejora la recuperación de información al enfocarse en el significado detrás de la consulta de un usuario, mejorando significativamente la búsqueda por palabras clave. Mediante incrustaciones, tanto las consultas como los documentos se convierten en vectores que capturan el significado semántico. Cuando un usuario envía una consulta, la base de datos vectorial busca los documentos más relevantes, incluso si los términos exactos de la consulta no están presentes directamente en el contenido.
Este enfoque permite una mejor comprensión contextual, asegurando resultados más precisos y relevantes. Al reconocer sinónimos, conceptos relacionados y variaciones de palabras, la búsqueda semántica mejora la experiencia del usuario y reduce la ambigüedad, proporcionando resultados que se ajustan mejor a la intención del usuario.
Reordenamiento
El reranking es una técnica empleada para mejorar la relevancia de los resultados de búsqueda tras una fase inicial de recuperación. Una vez que se recupera un conjunto de documentos, un modelo de reordenamiento los reordena según su relevancia para la consulta del usuario. Este modelo puede utilizar características adicionales, como la calidad del documento, la relevancia contextual o la puntuación basada en el aprendizaje automático para mejorar los resultados.
La reclasificación ayuda a priorizar la información más útil y contextualmente apropiada, mejorando la precisión y la satisfacción del usuario. Es especialmente útil cuando la fase inicial de recuperación puede devolver una amplia gama de resultados, permitiendo que el sistema refine la selección y presente las respuestas más relevantes.
Ingeniería de prompts
La ingeniería de prompts implica elaborar cuidadosamente la entrada proporcionada a un LLM para dirigir su salida en la dirección deseada. Al estructurar las indicaciones de manera efectiva, usted puede asegurarse de que el modelo genere respuestas más precisas, relevantes y apropiadas. Este proceso implica incluir instrucciones claras, contexto relevante y, a veces, ejemplos para ayudar al modelo a comprender la tarea.
En la generación aumentada de recuperación, la ingeniería de prompts desempeña un papel clave en la combinación de documentos recuperados con la consulta original del usuario para producir respuestas coherentes y precisas. Las indicaciones bien diseñadas reducen la ambigüedad, minimizan la información irrelevante y aseguran que el modelo se alinee con la intención del usuario, lo que resulta en salidas de mayor calidad.
Optimizando su aplicación de generación aumentada por recuperación
Las soluciones de RAG pueden optimizarse para proporcionar una mayor precisión y una experiencia general mejorada para los usuarios finales.
Optimización de la recuperación de información
La recuperación de información para RAG puede mejorarse mediante varias estrategias. Primero, revise las técnicas de segmentación para asegurar que los documentos se dividan en segmentos significativos y contextualmente relevantes. A continuación, elija el modelo de incrustación adecuado para capturar el significado semántico de su contenido. Los modelos específicos de dominio pueden ofrecer mejores resultados para ciertos casos de uso. Aunque la búsqueda semántica es la más utilizada, considere si la búsqueda por palabras clave o un enfoque híbrido pueden mejorar la recuperación.
Además, aplique métodos de reordenamiento después de la recuperación inicial para mejorar la precisión de los resultados. También es crucial ajustar la cantidad de documentos recuperados: demasiados pueden introducir ruido, mientras que muy pocos pueden omitir contexto importante. Encontrar el equilibrio adecuado ayuda a mejorar el rendimiento y la relevancia en la recuperación de datos.
Optimización de la generación de respuestas
Mejorar la generación de lenguaje en RAG se puede lograr mediante varios enfoques clave. Primero, concéntrese en la ingeniería de prompts para estructurar las consultas y el contexto de manera que guíe al modelo de lenguaje a generar respuestas más precisas y relevantes. Las instrucciones claras, el contexto y los ejemplos ayudan a reducir la ambigüedad y a mejorar la calidad de los resultados. A continuación, evalúe diferentes modelos o LLMs específicos de dominio para asegurarse de que las respuestas generadas se alineen con los matices de su caso de uso específico, mejorando la relevancia y la precisión. Además, se deben considerar parámetros ajustables del modelo, como la temperatura, para controlar la creatividad de las respuestas del modelo.
Optimización para la escala de producción
Asegúrese de que su sistema RAG esté listo para la producción eligiendo a los mejores proveedores de su clase para los componentes clave de su aplicación.
Para su base de datos vectorial, elija una plataforma que ofrezca capacidades de búsqueda e indexación altamente eficientes, especialmente una que soporte búsquedas escalables y rápidas de Vecinos Aproximados Más Cercanos (ANN). Las bases de datos vectoriales avanzadas también pueden admitir el filtrado de metadatos, lo que puede mejorar la precisión y la velocidad al reducir los resultados de búsqueda basados en información contextual adicional. Esto permitirá que su sistema recupere documentos relevantes rápidamente, incluso a medida que el conjunto de datos crece.
Al elegir un modelo de incrustación, es importante equilibrar la alta dimensionalidad de los vectores con un almacenamiento y una recuperación eficientes. Aunque las incrustaciones de dimensiones superiores capturan relaciones semánticas más ricas, implican un mayor costo computacional, mayores requisitos de almacenamiento y tiempos de recuperación más lentos.
Además, al seleccionar un modelo de lenguaje grande (LLM) para el componente de generación, asegúrese de que se ajuste a las necesidades específicas de su caso de uso. Los LLM deberían ser capaces de interpretar con precisión la información recuperada y generar respuestas coherentes y contextualmente relevantes. La elección del LLM también influye en el costo total y el rendimiento del sistema: los modelos más grandes pueden ofrecer una mayor precisión, pero a costa de una mayor latencia y mayores demandas computacionales. Es crucial evaluar su tiempo de respuesta, calidad de salida y requisitos de infraestructura para seleccionar un LLM que logre el equilibrio adecuado entre rendimiento y eficiencia.
Desafíos de la generación aumentada por recuperación
Uno de los desafíos clave de RAG es la dificultad para centralizar y organizar el contenido para su recuperación efectiva. Los sistemas RAG requieren acceso a grandes cantidades de datos en diversos dominios, pero organizar este contenido de manera que permita al modelo recuperar eficientemente la información más relevante y actualizada es una tarea compleja. Los datos pueden estar distribuidos en diferentes plataformas, formatos y bases de datos, lo que dificulta asegurar una cobertura y precisión completas. Además, asegurar la consistencia entre múltiples fuentes es crucial. La información recuperada puede ser contradictoria, desactualizada o incompleta, lo que puede confundir la base de conocimientos y socavar la calidad y fiabilidad de las respuestas generadas. Estos desafíos destacan la necesidad de sistemas de indexación y recuperación más avanzados que permitan a los modelos RAG obtener el mejor contenido posible y producir resultados relevantes y precisos.
Otro desafío significativo es la limitación actual de RAG para responder preguntas en lugar de realizar tareas más complejas. Aunque los sistemas RAG sobresalen en generar respuestas basadas en la información recuperada, tienen dificultades para llevar a cabo acciones más allá de responder consultas o crear contenido. Esta limitación surge porque RAG está diseñada principalmente para extraer datos relevantes de fuentes externas y proporcionar resultados basados en esos datos en lugar de interactuar con o manipular entornos del mundo real. Como resultado, aunque los modelos RAG pueden asistir en la recuperación de información y la generación de contenido, su capacidad para realizar tareas como la resolución de problemas o la toma de decisiones sigue estando poco desarrollada, lo que limita su potencial para aplicaciones más dinámicas.
Creación de generación interactiva de recuperación aumentada mejorada con memoria
Mejorar RAG con memoria amplía su capacidad para crear una experiencia más interactiva al recordar detalles clave y el contexto de interacciones anteriores. Los sistemas RAG tradicionales suelen responder a consultas sin conservar información a lo largo de múltiples intercambios, lo que resulta en una experiencia fragmentada. Al integrar mecanismos de memoria, los sistemas RAG podrían almacenar hechos, preferencias o conocimientos relevantes de conversaciones actuales y anteriores, permitiéndoles recordar esta información cuando sea necesario. Esto permite que el sistema ofrezca respuestas más personalizadas, conscientes del contexto, y cree una experiencia más fluida. Con el tiempo, el sistema desarrolla una comprensión más profunda de las necesidades del usuario, adaptando sus respuestas para que sean más relevantes y atractivas, haciendo que la experiencia se sienta como una conversación continua en lugar de una serie de consultas aisladas.
El futuro de la generación aumentada por recuperación y la IA generativa
Seguirán surgiendo nuevas técnicas dentro de RAG, mejorando su capacidad para recuperar y generar información de maneras más eficientes, adaptativas e inteligentes. Un área clave de crecimiento es el desarrollo de mecanismos avanzados de recuperación, que permiten a los sistemas RAG acceder dinámicamente a una gama más amplia de fuentes, incluidas bases de datos especializadas, contenido no estructurado e información en tiempo real. Estas mejoras harán que los sistemas RAG sean más conscientes del contexto, permitiéndoles generar resultados altamente relevantes y precisos en diversos dominios.
Al mismo tiempo, la integración de nuevas capacidades agentivas de IA generativa capacitará a los sistemas de IA para realizar tareas de resolución de problemas, análisis de datos y toma de decisiones. Estos sistemas agenciales no solo recuperarán y generarán respuestas, sino que también tomarán acciones basadas en la información que recopilen, haciéndolos más interactivos, autosuficientes e inteligentes. Como resultado, RAG se convertirá en el núcleo de aplicaciones como la investigación automatizada, las recomendaciones personalizadas y los asistentes virtuales interactivos, impulsando una nueva era de IA receptiva y proactiva.
Ajuste fino vs. generación aumentada por recuperación
El ajuste fino es un proceso mediante el cual un modelo de lenguaje se modifica a través de un entrenamiento adicional sobre nuevo contenido, enseñando al modelo nuevos conocimientos o comportamientos que se integran permanentemente en su memoria paramétrica. Este enfoque requiere recursos computacionales y experiencia significativos, tiene una capacidad limitada para nueva información debido a las restricciones del tamaño del modelo, y cualquier cambio realizado es permanente y no se puede actualizar fácilmente. Un modelo ajustado puede ofrecer resultados específicos del dominio, pero tiene requisitos significativos de tiempo de entrenamiento e implicaciones de costo, lo que dificulta mantenerlo actualizado.
La generación aumentada por recuperación (RAG) recupera dinámicamente contenido que no forma parte de los datos de entrenamiento antes de que se produzca la generación del lenguaje. Esto permite que los modelos RAG incorporen nuevos datos sin alterar los parámetros subyacentes del modelo, haciéndolos más flexibles y escalables para tareas que requieren mucho conocimiento, como el ajuste fino.
Cree aplicaciones RAG con MongoDB Atlas y Voyage AI
MongoDB Atlas es una base de datos robusta de propósito general que admite vectores y búsqueda vectorial, lo que la convierte en una opción ideal para desarrollar aplicaciones RAG de nivel de producción.
Voyage AI ofrece potentes modelos de incrustación y reclasificadores para lograr una recuperación de información altamente precisa.
Lleve sus proyectos al siguiente nivel: simplifique su proceso de desarrollo y desbloquee un nuevo valor mientras se beneficia de una integración fluida con los principales socios de IA, los principales proveedores de servicios en la cloud, los proveedores de modelos LLM e integradores de sistemas.
Recursos
Explore MongoDB Atlas, la base de datos vectorial con búsqueda integrada, capacidades vectoriales y mucho más. Regístrese gratis ahora.
Para obtener más información sobre Voyage AI, puede obtener más información en este blog.
Obtenga asesoramiento estratégico y soporte de implementación para la búsqueda y el resto de la pila de IA, visite nuestro Programa de aplicaciones de AI de MongoDB para obtener más detalles.