検索拡張生成(RAG:Retrieval-Augmented Generation)とは、生成プロセス中に関連性の高い最新情報を取り込むことで、大規模言語モデル(LLM:Large Language Model)の性能を向上させる一般的な生成 AI のフレームワークです。このアプローチにより、LLM は事前に学習した知識に加え、最新のドメイン固有データを活用できるようになります。RAG を活用することで、コストや時間のかかるモデル全体のファインチューニングや再トレーニングのプロセスを行うことなく、特定のユースケースに応じて LLM を効果的にカスタマイズできます。
インテリジェントな AI のための検索拡張生成
検索拡張生成(RAG)は、コストのかかるカスタムトレーニングを行うことなく、汎用の大規模言語モデル(LLM)を特定の用途に活用することを可能にします。RAG は、最新のドメイン固有情報でクエリを補強し、LLM が抱える根本的な制限の課題を解決し、生成機能を強化します。これにより、リアルタイム情報や独自のデータセット、元のモデルのトレーニングには含まれていない専門的な文書を取り入れることができます。また、回答とともに参照情報を透過的に提供できるため、信頼性を高め、ハルシネーション(幻覚)のリスクを低減します。
大規模言語モデル(LLM)とは
大規模言語モデル(LLM)は、人間のようなテキストを理解し、生成するように設計された人工知能の一種です。自然言語処理(NLP)の高度なアプリケーションとして、LLM は膨大な量の学習データからパターン、構造、文法を学習し、ユーザーのプロンプトに対して首尾一貫した応答を生成できます。LLM の強みは、タスク固有のトレーニングを必要とせずに、幅広い言語生成タスクを実行できる点にあります。そのため、チャットボット、翻訳、コンテンツ作成、要約などの用途に汎用性の高いツールといえます。
大規模言語モデル(LLM)における制限と課題
LLM は、膨大な学習データセットを分析して学習する複雑なニューラルネットワークです。これらのモデルは膨大な計算資源を必要とするため、開発には莫大なコストと時間がかかります。また、LLM を運用・維持するための専用インフラも不可欠であることから、導入には相応の技術力と資金力が求められます。こうした経済的・技術的なハードルにより、LLM は一部の大規模な組織に限られて活用されているのが現状です。
LLM は歴史的な内容に関する質問に答えるのに優れている一方で、その知識は学習データの制限によって制約を受けます。そのため、モデルの再トレーニングを行わないと最新の出来事に関する質問に答えることができません。最新情報を必要とする質問にはあまり効果的ではありません。
同様に、LLM は企業内の文書や特定の業界・分野に特化した独自のデータセットについて、ネイティブに回答できません。こうした制限は、ニーズに特化し、深く専門的な知識を必要とする AI テクノロジーを活用しようとする企業にとって、大きな課題となります。
さらに、LLM のもう一つの大きな課題として「幻覚(ハルシネーション)」があります。信頼できる情報が不足している場合は、モデルは自信ありげで説得力のある、しかし実際には根拠のない誤った回答を生成してしまうことがあります。こうした誤情報の生成傾向は、正確性と信頼性が求められる用途において深刻なリスクとなります。

検索拡張生成(RAG)を使用するメリット
RAG は比較的シンプルなアーキテクチャでありながら、性能を大幅に向上させることができるため近年注目を集めています。次のようなメリットがあります。
優れたコスト効果
RAG により、汎用の事前学習済みモデルをカスタム学習なしで特定用途に応用できるため、専用モデルの開発コストを回避できます。さらに、必要な情報だけを効果的に取得して LLM に渡すため、トークン単位で課金される API のコストも抑えることができます。
ドメインのカスタマイズ
RAG は、専門的な知識ライブラリを統合し、事前にトレーニングされたモデルを特定のドメインに合わせて調整することを可能にします。これにより、モデルのトレーニングのカスタマイズは不要で、独自のドキュメントや業界固有のドキュメントに関する回答を生成できます。ファインチューニングは同様の利点をもたらします。しかし、より多くの時間、コスト、メンテナンスが必要となります。
リアルタイムなインサイト
RAG は、外部ソースから最新のデータを動的に取得し、それをもとに応答を生成することで、LLM がリアルタイムの情報にアクセスできるようにします。これにより、固定された学習データに起因する知識の制限を克服し、最新の出来事や新たなトレンドに関するインサイトの提供が可能になります。
透明性
RAG は、生成されたコンテンツにソースの引用と証拠を提供し、AI の応答の信頼性を向上させます。各レスポンスを知識ベース内の特定のソースに紐付けするため、ユーザーは情報の出所や正確性を検証できます。また、ハルシネーションのリスクを低減し、生成 AI アウトプットの信頼性を向上させます。
適応性
RAG の主な利点の一つは、新しい最新モデルに容易に適応できることです。言語モデルや検索技術の進歩に伴い、組織はシステム全体を再構築せずに、新しいモデルを取り入れたり、検索戦略を変更できます。この柔軟性により、RAG システムは常に最先端技術に対応できます。
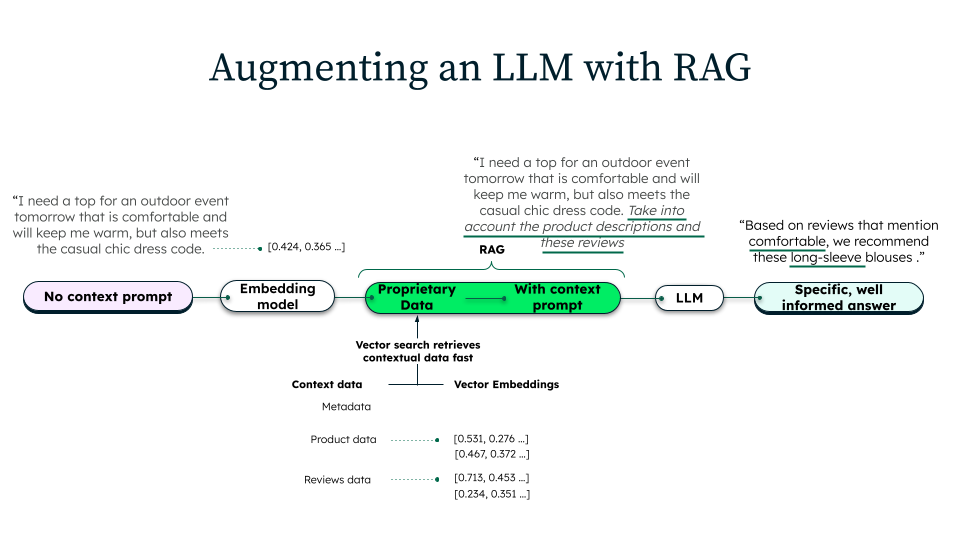
検索拡張生成(RAG)の仕組み
RAG は、取り込み、検索、生成の 3 つの段階から構成されています。
データの取り込み
インジェスト(取り込み)では、組織が検索対象となる知識ベースを準備します。ソースデータは、社内文書、データベース、外部リソースなど、さまざまなリポジトリから収集されます。これらのドキュメントは、クリーニングされ、フォーマットされ、管理可能な小さなチャンクに分割されます。各チャンクは、埋め込みモデルを使用してベクトル表現に変換され、テキストの意味的な特徴を数値化します。こうして生成されたベクトルは、意味検索を効率的に行えるベクトルデータベースに格納されます。
情報検索
ユーザーがクエリを送信すると、システムは生成前に関連するコンテキストを取得します。クエリは、取り込み時に使用されたのと同じ埋め込みモデルを使用して、ベクトル表現に変換されます。ベクトル検索は、クエリと最も意味的に類似したドキュメントチャンクをデータベースから検索します。さらに、検索結果に対してフィルタリング、ランキング、重み付けなどを行うことで、特に関連性の高い情報だけが選ばれ、最終的な回答の精度を向上させます。
生成
関連する文脈が検索されると、元のプロンプト、検索された同じ文章、具体的な指示を使用して、拡張プロンプトが作成されます。LLM はこのプロンプトを処理し、事前学習された知識と検索されたコンテンツを合成した応答を生成します。このアプローチにより、応答が外部のデータソースから情報を得て、ユーザの意図に沿ったものとなり、より正確な回答につながります。
検索拡張生成(RAG)の業界別ユースケース
RAG は、さまざまな業界で活用されており、大規模言語モデル(LLM)と AI の変革的な可能性を引き出しています。
- 製造業:設備マニュアルや保守ログと LLM を連携させることで、リアルタイムの運用ガイダンスを提供します。RAG は、技術者が機械に関する正確な情報への迅速なアクセスを可能にし、ダウンタイムを削減し、機器のパフォーマンスを向上させます。
- カスタマーサポート:社内文書、製品ガイド、サポート履歴を活用して問題を診断します。RAG は、ポートチームは必要な情報を即座に取得できるため、応答時間の短縮や初回対応解決率の向上に役立ちます。
- 医療・ヘルスケア:医学研究、臨床ガイドライン、患者記録を統合し、診断の決定や治療の推奨をサポートします。RAG により、医療従事者は、最新の医学知識へのアクセスし、透明性のあるエビデンスに基づいたインサイトを提供できます。
- 金融サービス:規制文書、市場レポート、コンプライアンスガイドラインを統合し、投資調査、リスク評価、規制遵守をサポートします。RAG により、金融アナリストは複雑な最新の財務情報を迅速に取得し、分析できます。
- ソフトウェアエンジニアリング:エンジニアは、コードを記述する際に、ドキュメントやコードスニペットをレビューに RAG を活用できます。また、類似した過去の問題に基づいてバグ修正の可能性を提案することで、デバッグを支援し、生産性と品質を向上させます。
検索拡張生成(RAG)の主要な概念
チャンク化
チャンク化は、システムの精度を高めながらコストを削減する、データ取り込みプロセスのコンポーネントです。チャンク化では、大きなコンテンツを管理しやすい小さなセグメントに分割し、検索に備えます。ポイントは、意味のある完全に文脈化されたチャンクを作成し、冗長性を最小限に抑え、有用な情報を十分に保持することです。
粒度と完全性のバランスがとれているチャンク化が効果的といえます。不要な詳細情報で LLM を圧迫することなく、システムが関連情報を検索できることが理想的です。適切に構造化されたチャンクは、検索精度を向上させ、トークンの使用量を減らし、コスト効率と精度の高い回答につながります。
埋め込みモデル
埋め込みモデルは、テキストなどのデータを「ベクトル」と呼ばれる数値表現に変換し、その意味的な関係性を捉えられるようにする技術です。これにより、システムは単語、フレーズ、文書間の関係を理解できるようになり、関連情報の検索精度が向上します。
データ取り込みの際には、埋め込みモデルは各データチャンクを処理し、ベクトルデータベースに格納する前にベクトルに変換します。ユーザーがクエリを送信すると、同じ埋め込みモデルを使用してベクトルに変換されます。
埋め込みモデルの種類は、さまざまなユースケースをサポートします。汎用的なモデルは幅広い用途に対応し、ドメイン特化型モデルは法律、医療、金融などの業界に特化し、専門分野での検索精度を向上させます。マルチモーダルモデルは、テキスト処理にとどまらず、画像、音声、その他のデータタイプを扱うことで、高度な検索機能を実現します。画像や動画と直接比較できるテキストの数値表現を作成し、真に高度なマルチモーダル検索を実現するモデルもあります。
セマンティック検索
セマンティック検索は、ユーザーのクエリの背後にある「意味」に注目し、情報検索を改善し、キーワード検索を大幅に向上させる手法です。埋め込み技術を使用すると、クエリとドキュメントの両方が、意味的な意味を捉えたベクトルに変換されます。ユーザーがクエリを送信すると、ベクトルデータベースは、正確なクエリ用語がコンテンツに直接存在しない場合でも、最も関連性の高いドキュメントを検索します。
このアプローチは、より正確で関連性の高い結果を保証し、より良い文脈理解を可能にします。同義語、関連する概念、単語のバリエーションを認識し、セマンティック検索はユーザーエクスペリエンスを向上させ、曖昧さを減らし、ユーザーの意図によりマッチした結果を提供します。
再ランク付け
再ランク付けは、最初の検索段階後に検索結果の関連性を向上させるために使用される手法です。一連の文書が検索されると、再ランク付けモデルがユーザーのクエリとの関連性に基づいてそれらを並べ替えます。このモデルは、文書の品質、文脈上の関連性、機械学習ベースのスコアリングなどの追加機能を活用して、結果を絞り込むことができます。
再ランク付けは、最も有用で文脈に適した情報に優先順位を付け、精度とユーザーの満足度を向上させます。特に、最初の検索フェーズで幅広い検索結果が返される場合に有効で、システムを微調整して最も関連性の高い回答を提示できます。
プロンプトエンジニアリング
プロンプトエンジニアリングとは、LLM の出力を適切な方向に導くために、入力プロンプトを精密に設計する技術です。プロンプトを効果的に構成することで、モデルが正確で適切な回答を生成できるようになります。このプロセスには、明確な指示、関連する文脈、場合によっては具体例が含まれ、モデルがタスクを理解するのに役立ちます。
RAG におけるプロンプトエンジニアリングは、検索された文書と元のユーザークエリを組み合わせて、一貫性があり的確な応答を生成するうえで重要な役割を担います。適切に設計されたプロンプトは、曖昧さを排除し、関連性の低い情報を最小限に抑え、モデルがユーザーの意図を正確に反映した高品質な出力を導きます。
RAG アプリケーションの最適化
RAG ソリューションは、精度の向上とユーザー体験の改善を目的として、さまざまな側面から最適化できます。
情報検索の最適化
RAG の情報検索はいくつかの戦略によって改善できます。まず、ドキュメントが意味のある、文脈に関連したセグメントに分割されるように、チャンク化技術を見直します。次に、コンテンツの意味を正確に捉えるために、適切な埋め込みモデルを選択します。特定のユースケースでは、ドメインに特化したモデルの方が良い結果が得られるかもしれません。検索方法として一般的なセマンティック検索に加えて、キーワード検索やハイブリッドアプローチが検索を向上させるかどうかを検討します。
さらに、最初の検索後に再ランク付けの方法を適用し、結果の精度を向上させます。また、検索される文書数の調整も重要です。多すぎるとノイズが増え、少なすぎると重要な文脈を見逃す可能性があります。適切なバランスを見つけることで、検索のパフォーマンスと関連性を向上させることができます。
出力の最適化
RAG の回答品質の改善には、いくつかの重要なアプローチがあります。第一に、言語モデルがより正確で適切な応答を生成するよう導く方法で、クエリとコンテキストを構造化するプロンプトエンジニアリングに焦点を当てます。明確な指示、文脈、例を含めることで、曖昧さを減らし、出力の品質を向上させるのに役立ちます。次に、さまざまなモデルまたはドメイン固有の LLM を評価し、生成された応答が特定のユースケースのニュアンスに合致していることを確認し、関連性と精度を向上させます。さらに、モデルの応答の創造性を制御するために、温度などの調整可能なモデルパラメータを検討する必要があります。
本場環境規模の最適化
RAG システムを本番環境で安定して運用するには、アプリケーションの主要コンポーネントにおいて、最適なベンダーの選定が重要です。
ベクトルデータベースには、非常に効率的な検索とインデックス作成機能を提供するプラットフォーム、特にスケーラブルで高速な近似最近傍(ANN)検索をサポートするプラットフォームを選択します。高度なベクトルデータベースは、メタデータフィルタリングにも対応しています。メタデータフィルタリングは、追加のコンテキスト情報に基づいて検索結果を絞り込むことにより、精度と速度を向上させます。これにより、データセットが大きくなっても、システムが関連ドキュメントを迅速に検索できるようになります。
埋め込みモデルを選択する際、ベクトルの高次元性と効率的な保存や検索のバランスをとることが重要です。高次元の埋め込みは、より豊かな意味的関係を捉えることができる反面、計算コスト、ストレージ要件、検索時間の増加を伴います。
さらに、生成コンポーネント用の大規模言語モデル(LLM)を選択する際には、それがユースケースの特定のニーズに合致していることを確認してください。LLM は、検索された情報を正確に解釈し、首尾一貫した、文脈に関連した応答を生成できる必要があります。LLM の選択は、システムの全体的なコストとパフォーマンスにも影響します。大きなモデルは精度が高くなる一方で、待ち時間と計算負荷が高くなります。レスポンスタイム、出力品質、インフラ要件を評価し、パフォーマンスと効率の適切なバランスを取る LLM の選択が重要です。
検索拡張生成(RAG)の課題
RAG の重要な課題の一つは、効果的な検索のためにコンテンツを一元化して整理することの複雑さです。RAG システムは、多様な領域にわたる膨大な量のデータにアクセスする必要があり、モデルが最も関連性の高い最新の情報を効率的に検索できるようにコンテンツを整理することは複雑な作業です。データはさまざまなプラットフォーム、フォーマット、データベースに分散しており、包括的な網羅性と正確性を確保するのは困難です。さらに、複数の情報源間で一貫性の確保も重要です。検索された情報が矛盾していたり、古かったり、不完全であったりすると、知識ベースの品質が低下し、生成される回答の質と信頼性が損なわれる可能性があります。これらの課題は、RAG モデルが可能な限り最高のコンテンツを取り込み、関連性のある正確な出力を生成できるようにする、洗練されたインデックス付けと検索システムの必要性を浮き彫りにしています。
もう一つの重要な課題は、RAG が現在、複雑なタスクの実行ではなく、質問への回答に限定されていることです。RAG システムは、検索した情報に基づいた応答の生成に優れている一方で、質問応答やコンテンツ生成を超えるような処理、たとえば問題解決や意思決定といったタスクの実行は得意としていません。この制約は、RAG が実世界環境と対話したり操作したりするのではなく、主に外部ソースから関連データを取り込み、そのデータに基づいて出力を提供するように設計されているために生じます。その結果、RAG モデルは情報検索やコンテンツ生成には使用できる一方で、問題解決や意思決定のようなタスクを実行する能力はまだ不十分であり、動的なアプリケーションの展開には限界があります。
メモリ機能を強化したインタラクティブな RAG の構築
RAG にメモリ機能を組み込むことで、過去のやり取りから重要な情報や文脈を記憶し、よりインタラクティブな体験を提供できるようになります。従来の RAG システムは、個々の問い合わせに対して独立して応答する設計となっており、会話全体としては断片的で一貫性に欠ける場合がありました。メモリメカニズムを統合することで、RAG システムは現在および過去の会話から関連する事実、ユーザーの好み、インサイトを保持し、必要に応じてこれらの情報を呼び出すことができます。これにより、RAG システムは、パーソナライズされたコンテキストを認識した応答を提供し、シームレスな経験を作成できます。時間の経過とともに、このシステムはユーザーのニーズをより深く理解し、より適切で魅力的な応答を返すように進化していきます。その結果、体験は単なる一連の質問ではなく、継続的な対話のように感じられるようになります。
検索拡張生成(RAG)と生成 AI の将来
RAG における新たな技術革新は今後も進み、より効率的で適応性が高く、知的な方法で情報の検索と生成を行えるようになります。特に注目されるのは、高度な検索メカニズムの開発です。これにより、RAG システムは専門的なデータベース、非構造化コンテンツ、リアルタイム情報など、より幅広い情報源に動的にアクセスできるようになります。このような改良により、RAG システムは文脈をさらに認識できるようになり、さまざまな領域にわたって関連性と精度の高い出力を生成できるようになります。
同時に、新しい生成 AI エージェント機能を統合することで、AI システムは問題解決、データ分析、意思決定タスクを実行できるようになります。このようなエージェント型システムは、回答を検索して生成するだけでなく、収集した情報に基づいて行動を起こすことで、インタラクティブで、自律的、インテリジェントなものとなります。その結果、RAG は自動リサーチ、パーソナライズされたレコメンデーション、対話型バーチャルアシスタントなどのアプリケーションの中心となり、応答的でプロアクティブな AI の新時代を牽引します。
ファインチューニングと検索拡張生成(RAG)の比較
ファインチューニングとは、新しいコンテンツに対する追加トレーニングを通じて言語モデルを修正するプロセスで、本質的にモデルに新しい知識や動作を教え、そのパラメトリックメモリに恒久的に埋め込むものです。このアプローチには、多大な計算リソースと専門知識が必要であり、モデルサイズの制約により新しい情報の容量が制限され、加えられた変更は永続的で簡単に更新できません。ファインチューニングされたモデルは、ドメイン固有の結果を提供できる一方で、トレーニングに要する時間とコストが大きく、最新の状態に保つことが困難です。
検索拡張生成(RAG)は、生成が行われる前に、学習データの一部ではないコンテンツを動的に検索します。これにより、RAG モデルはモデルの基本パラメータを変更することなく新しいデータを取り込むことができるため、ファインチューニングのような知識集約的なタスクを必要とせず、柔軟でスケーラブルになります。
MongoDB Atlas と Voyage AI による RAG アプリケーションの構築
MongoDB Atlas は、ベクトルとベクトル検索に対応した堅牢な汎用データベースであり、本番環境に対応した RAG アプリケーションの構築に最適です。
Voyage AI は、高精度な情報検索を実現する強力な埋め込みモデルとリランカーを提供します。
主要な AI パートナー、大手クラウドプロバイダ、LLM モデルプロバイダ、システムインテグレーターとのシームレスな連携により、開発プロセスを効率化し、新たな価値を創出し、プロジェクトの成果を加速させます。
関連リソース
MongoDB Atlas は、検索機能やベクトル機能などを内蔵したベクトルデータベースです。今すぐ無料で登録できます。
Voyage AI について詳しくは、こちらのブログをご覧ください。
検索やその他の AI スタックに関する戦略的なアドバイスや導入支援については、MongoDB AI Applications Program をご覧ください。